 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Gateway for Knowledge Graph Schemas Collection, Analysis, and Embedding
Nov 21, 2023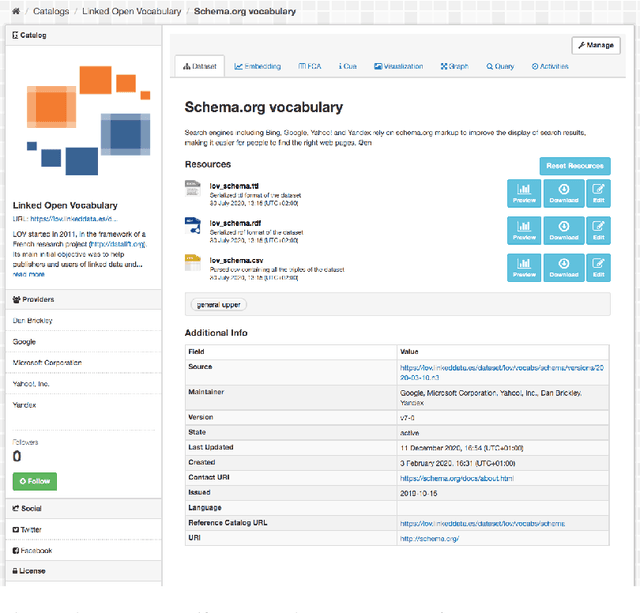
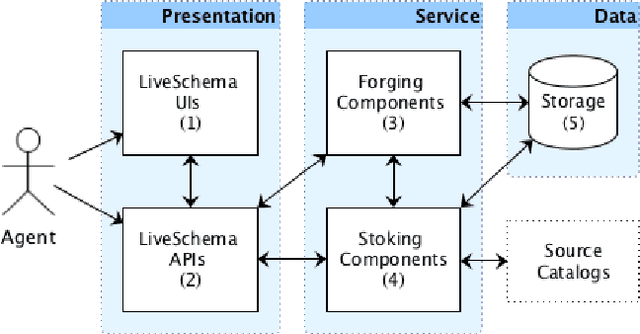
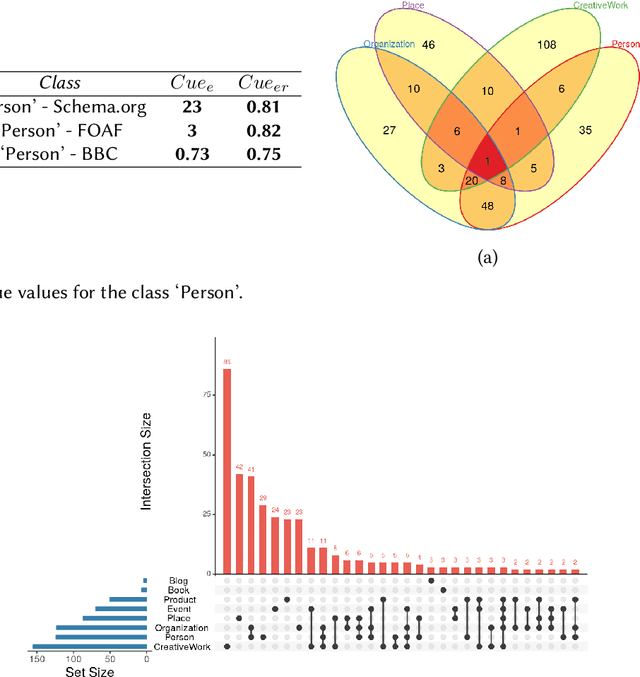
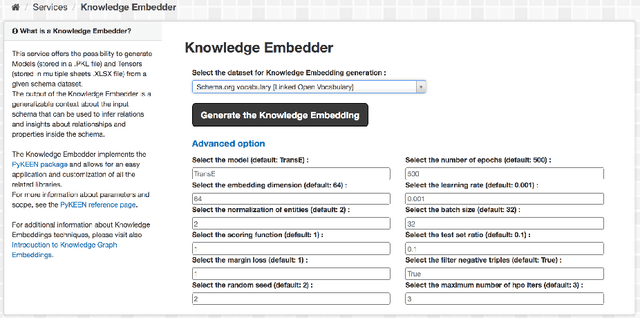
One of the significant barriers to the training of statistical models on knowledge graphs is the difficulty that scientists have in finding the best input data to address their prediction goal. In addition to this, a key challenge is to determine how to manipulate these relational data, which are often in the form of particular triples (i.e., subject, predicate, object), to enable the learning process. Currently, many high-quality catalogs of knowledge graphs, are available. However, their primary goal is the re-usability of these resources, and their interconnection, in the context of the Semantic Web. This paper describes the LiveSchema initiative, namely, a first version of a gateway that has the main scope of leveraging the gold mine of data collected by many existing catalogs collecting relational data like ontologies and knowledge graphs. At the current state, LiveSchema contains - 1000 datasets from 4 main sources and offers some key facilities, which allow to: i) evolving LiveSchema, by aggregating other source catalogs and repositories as input sources; ii) querying all the collected resources; iii) transforming each given dataset into formal concept analysis matrices that enable analysis and visualization services; iv) generating models and tensors from each given dataset.
LiveSchema: A Gateway Towards Learning on Knowledge Graph Schemas
Jul 13, 2022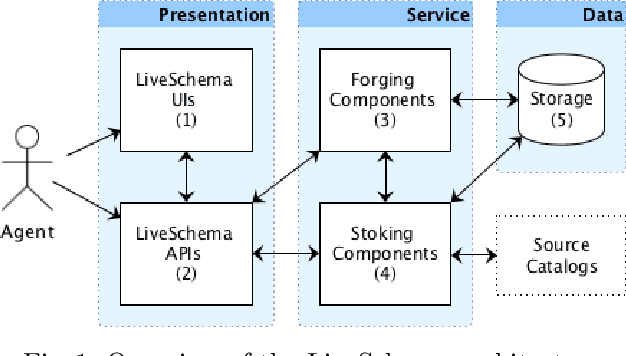
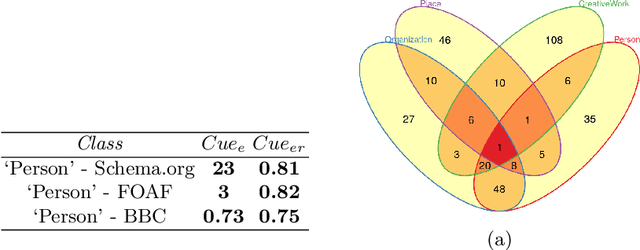
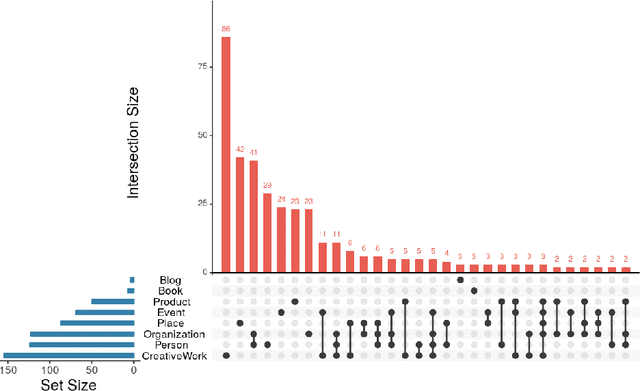
One of the major barriers to the training of algorithms on knowledge graph schemas, such as vocabularies or ontologies, is the difficulty that scientists have in finding the best input resource to address the target prediction tasks. In addition to this, a key challenge is to determine how to manipulate (and embed) these data, which are often in the form of particular triples (i.e., subject, predicate, object), to enable the learning process. In this paper, we describe the LiveSchema initiative, namely a gateway that offers a family of services to easily access, analyze, transform and exploit knowledge graph schemas, with the main goal of facilitating the reuse of these resources in machine learning use cases. As an early implementation of the initiative, we also advance an online catalog, which relies on more than 800 resources, with the first set of example services.