 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Computer Vision learn from Ranganathan?
Jan 30, 2026The Semantic Gap Problem (SGP) in Computer Vision (CV) arises from the misalignment between visual and lexical semantics leading to flawed CV dataset design and CV benchmarks. This paper proposes that classification principles of S.R. Ranganathan can offer a principled starting point to address SGP and design high-quality CV datasets. We elucidate how these principles, suitably adapted, underpin the vTelos CV annotation methodology. The paper also briefly presents experimental evidence showing improvements in CV annotation and accuracy, thereby, validating vTelos.
Language and Knowledge Representation: A Stratified Approach
Apr 14, 2025The thesis proposes the problem of representation heterogeneity to emphasize the fact that heterogeneity is an intrinsic property of any representation, wherein, different observers encode different representations of the same target reality in a stratified manner using different concepts, language and knowledge (as well as data). The thesis then advances a top-down solution approach to the above stratified problem of representation heterogeneity in terms of several solution components, namely: (i) a representation formalism stratified into concept level, language level, knowledge level and data level to accommodate representation heterogeneity, (ii) a top-down language representation using Universal Knowledge Core (UKC), UKC namespaces and domain languages to tackle the conceptual and language level heterogeneity, (iii) a top-down knowledge representation using the notions of language teleontology and knowledge teleontology to tackle the knowledge level heterogeneity, (iv) the usage and further development of the existing LiveKnowledge catalog for enforcing iterative reuse and sharing of language and knowledge representations, and, (v) the kTelos methodology integrating the solution components above to iteratively generate the language and knowledge representations absolving representation heterogeneity. The thesis also includes proof-of-concepts of the language and knowledge representations developed for two international research projects - DataScientia (data catalogs) and JIDEP (materials modelling). Finally, the thesis concludes with future lines of research.
From Knowledge Organization to Knowledge Representation and Back
Jan 22, 2024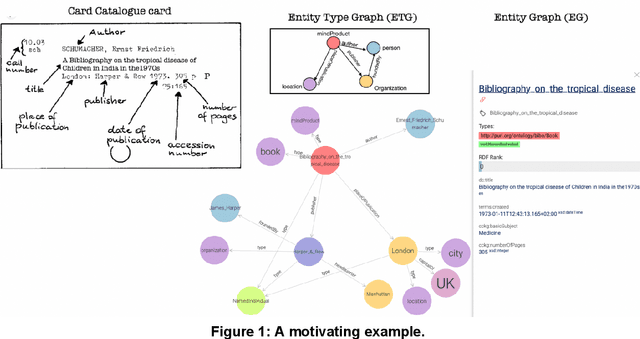
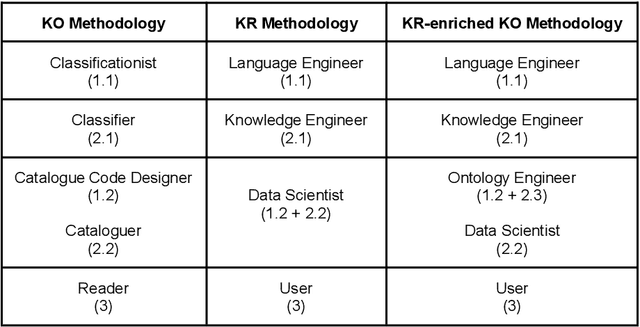
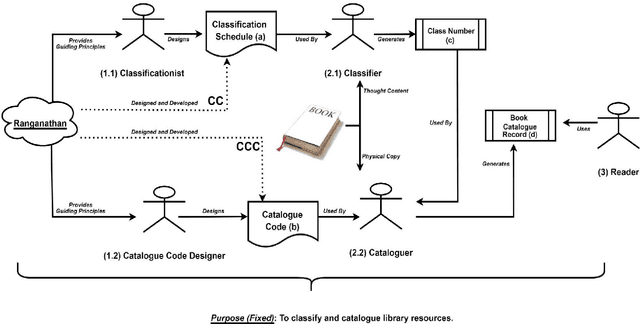
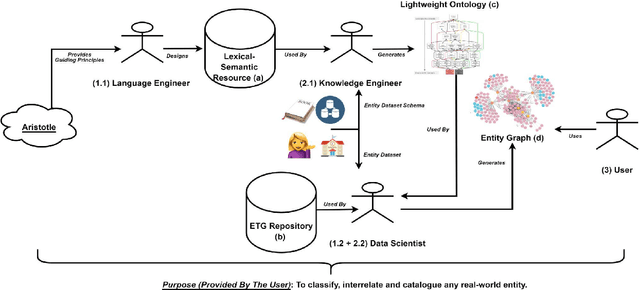
Knowledge Organization (KO) and Knowledge Representation (KR) have been the two mainstream methodologies of knowledge modelling in the Information Science community and the Artificial Intelligence community, respectively. The facet-analytical tradition of KO has developed an exhaustive set of guiding canons for ensuring quality in organising and managing knowledge but has remained limited in terms of technology-driven activities to expand its scope and services beyond the bibliographic universe of knowledge. KR, on the other hand, boasts of a robust ecosystem of technologies and technology-driven service design which can be tailored to model any entity or scale to any service in the entire universe of knowledge. This paper elucidates both the facet-analytical KO and KR methodologies in detail and provides a functional mapping between them. Out of the mapping, the paper proposes an integrated KR-enriched KO methodology with all the standard components of a KO methodology plus the advanced technologies provided by the KR approach. The practical benefits of the methodological integration has been exemplified through the flagship application of the Digital University at the University of Trento, Italy.
From Knowledge Representation to Knowledge Organization and Back
Dec 12, 2023Knowledge Representation (KR) and facet-analytical Knowledge Organization (KO) have been the two most prominent methodologies of data and knowledge modelling in the Artificial Intelligence community and the Information Science community, respectively. KR boasts of a robust and scalable ecosystem of technologies to support knowledge modelling while, often, underemphasizing the quality of its models (and model-based data). KO, on the other hand, is less technology-driven but has developed a robust framework of guiding principles (canons) for ensuring modelling (and model-based data) quality. This paper elucidates both the KR and facet-analytical KO methodologies in detail and provides a functional mapping between them. Out of the mapping, the paper proposes an integrated KO-enriched KR methodology with all the standard components of a KR methodology plus the guiding canons of modelling quality provided by KO. The practical benefits of the methodological integration has been exemplified through a prominent case study of KR-based image annotation exercise.
Towards a Gateway for Knowledge Graph Schemas Collection, Analysis, and Embedding
Nov 21, 2023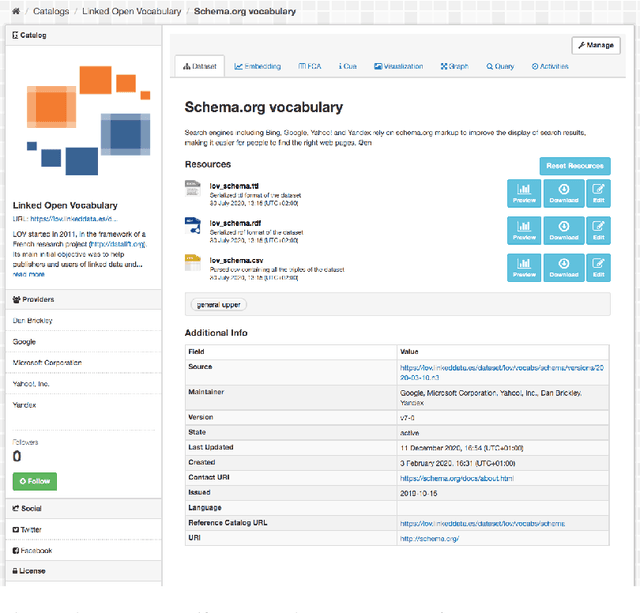
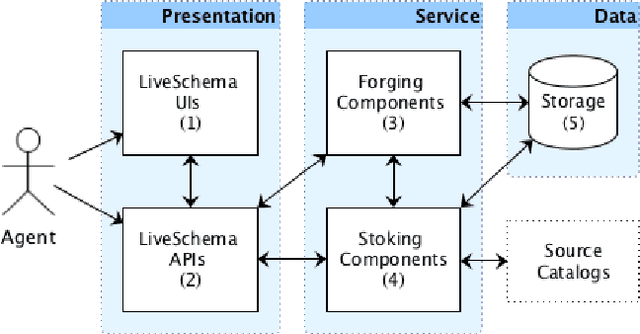
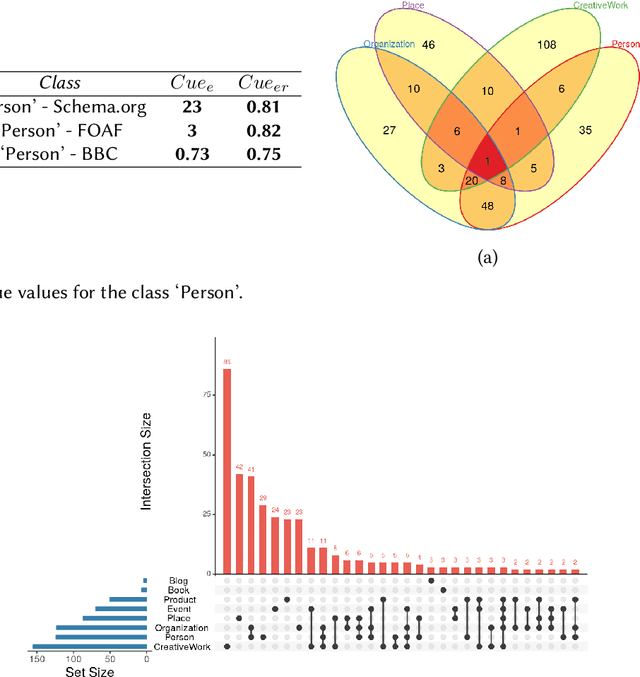
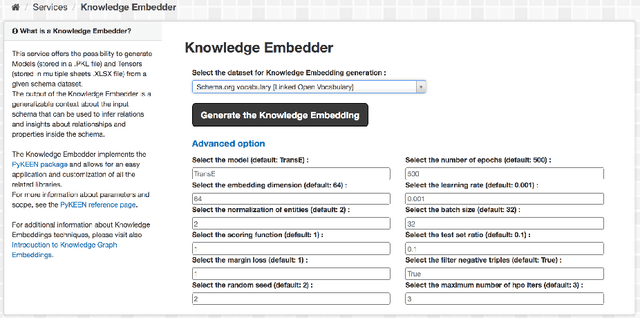
One of the significant barriers to the training of statistical models on knowledge graphs is the difficulty that scientists have in finding the best input data to address their prediction goal. In addition to this, a key challenge is to determine how to manipulate these relational data, which are often in the form of particular triples (i.e., subject, predicate, object), to enable the learning process. Currently, many high-quality catalogs of knowledge graphs, are available. However, their primary goal is the re-usability of these resources, and their interconnection, in the context of the Semantic Web. This paper describes the LiveSchema initiative, namely, a first version of a gateway that has the main scope of leveraging the gold mine of data collected by many existing catalogs collecting relational data like ontologies and knowledge graphs. At the current state, LiveSchema contains - 1000 datasets from 4 main sources and offers some key facilities, which allow to: i) evolving LiveSchema, by aggregating other source catalogs and repositories as input sources; ii) querying all the collected resources; iii) transforming each given dataset into formal concept analysis matrices that enable analysis and visualization services; iv) generating models and tensors from each given dataset.
A semantics-driven methodology for high-quality image annotation
Jul 26, 2023Recent work in Machine Learning and Computer Vision has highlighted the presence of various types of systematic flaws inside ground truth object recognition benchmark datasets. Our basic tenet is that these flaws are rooted in the many-to-many mappings which exist between the visual information encoded in images and the intended semantics of the labels annotating them. The net consequence is that the current annotation process is largely under-specified, thus leaving too much freedom to the subjective judgment of annotators. In this paper, we propose vTelos, an integrated Natural Language Processing, Knowledge Representation, and Computer Vision methodology whose main goal is to make explicit the (otherwise implicit) intended annotation semantics, thus minimizing the number and role of subjective choices. A key element of vTelos is the exploitation of the WordNet lexico-semantic hierarchy as the main means for providing the meaning of natural language labels and, as a consequence, for driving the annotation of images based on the objects and the visual properties they depict. The methodology is validated on images populating a subset of the ImageNet hierarchy.
Building Interoperable Electronic Health Records as Purpose-Driven Knowledge Graphs
May 10, 2023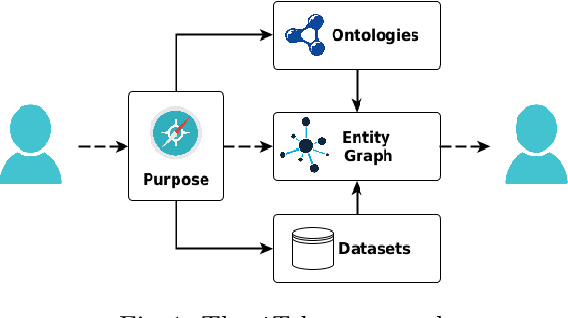

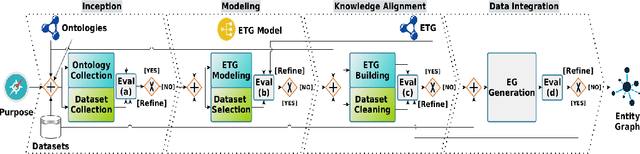

When building a new application we are increasingly confronted with the need of reusing and integrating pre-existing knowledge. Nevertheless, it is a fact that this prior knowledge is virtually impossible to reuse as-is. This is true also in domains, e.g., eHealth, where a lot of effort has been put into developing high-quality standards and reference ontologies, e.g. FHIR1. In this paper, we propose an integrated methodology, called iTelos, which enables data and knowledge reuse towards the construction of Interoperable Electronic Health Records (iEHR). The key intuition is that the data level and the schema level of an application should be developed independently, thus allowing for maximum flexibility in the reuse of the prior knowledge, but under the overall guidance of the needs to be satisfied, formalized as competence queries. This intuition is implemented by codifying all the requirements, including those concerning reuse, as part of a purpose defined a priori, which is then used to drive a middle-out development process where the application schema and data are continuously aligned. The proposed methodology is validated through its application to a large-scale case study.
* DSAI SPRINGER BOOK. arXiv admin note: text overlap with arXiv:2105.09418
Incremental Image Labeling via Iterative Refinement
Apr 18, 2023


Data quality is critical for multimedia tasks, while various types of systematic flaws are found in image benchmark datasets, as discussed in recent work. In particular, the existence of the semantic gap problem leads to a many-to-many mapping between the information extracted from an image and its linguistic description. This unavoidable bias further leads to poor performance on current computer vision tasks. To address this issue, we introduce a Knowledge Representation (KR)-based methodology to provide guidelines driving the labeling process, thereby indirectly introducing intended semantics in ML models. Specifically, an iterative refinement-based annotation method is proposed to optimize data labeling by organizing objects in a classification hierarchy according to their visual properties, ensuring that they are aligned with their linguistic descriptions. Preliminary results verify the effectiveness of the proposed method.
Disentangling Domain Ontologies
Mar 21, 2023In this paper, we introduce and illustrate the novel phenomenon of Conceptual Entanglement which emerges due to the representational manifoldness immanent while incrementally modelling domain ontologies step-by-step across the following five levels: perception, labelling, semantic alignment, hierarchical modelling and intensional definition. In turn, we propose Conceptual Disentanglement, a multi-level conceptual modelling strategy which enforces and explicates, via guiding principles, semantic bijections with respect to each level of conceptual entanglement (across all the above five levels) paving the way for engineering conceptually disentangled domain ontologies. We also briefly argue why state-of-the-art ontology development methodologies and approaches are insufficient with respect to our characterization.
Aligning Visual and Lexical Semantics
Dec 13, 2022We discuss two kinds of semantics relevant to Computer Vision (CV) systems - Visual Semantics and Lexical Semantics. While visual semantics focus on how humans build concepts when using vision to perceive a target reality, lexical semantics focus on how humans build concepts of the same target reality through the use of language. The lack of coincidence between visual and lexical semantics, in turn, has a major impact on CV systems in the form of the Semantic Gap Problem (SGP). The paper, while extensively exemplifying the lack of coincidence as above, introduces a general, domain-agnostic methodology to enforce alignment between visual and lexical semantics.