 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAncientBench: Towards Comprehensive Evaluation on Excavated and Transmitted Chinese Corpora
Dec 19, 2025
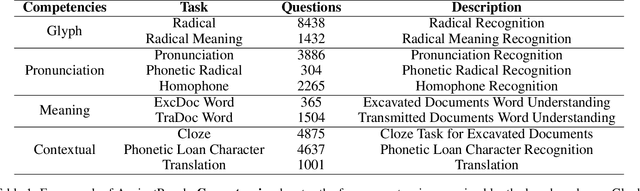

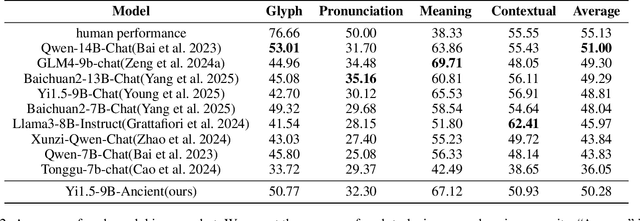
Comprehension of ancient texts plays an important role in archaeology and understanding of Chinese history and civilization. The rapid development of large language models needs benchmarks that can evaluate their comprehension of ancient characters. Existing Chinese benchmarks are mostly targeted at modern Chinese and transmitted documents in ancient Chinese, but the part of excavated documents in ancient Chinese is not covered. To meet this need, we propose the AncientBench, which aims to evaluate the comprehension of ancient characters, especially in the scenario of excavated documents. The AncientBench is divided into four dimensions, which correspond to the four competencies of ancient character comprehension: glyph comprehension, pronunciation comprehension, meaning comprehension, and contextual comprehension. The benchmark also contains ten tasks, including radical, phonetic radical, homophone, cloze, translation, and more, providing a comprehensive framework for evaluation. We convened archaeological researchers to conduct experimental evaluations, proposed an ancient model as baseline, and conducted extensive experiments on the currently best-performing large language models. The experimental results reveal the great potential of large language models in ancient textual scenarios as well as the gap with humans. Our research aims to promote the development and application of large language models in the field of archaeology and ancient Chinese language.
Automated Construction of Medical Indicator Knowledge Graphs Using Retrieval Augmented Large Language Models
Nov 17, 2025Artificial intelligence (AI) is reshaping modern healthcare by advancing disease diagnosis, treatment decision-making, and biomedical research. Among AI technologies, large language models (LLMs) have become especially impactful, enabling deep knowledge extraction and semantic reasoning from complex medical texts. However, effective clinical decision support requires knowledge in structured, interoperable formats. Knowledge graphs serve this role by integrating heterogeneous medical information into semantically consistent networks. Yet, current clinical knowledge graphs still depend heavily on manual curation and rule-based extraction, which is limited by the complexity and contextual ambiguity of medical guidelines and literature. To overcome these challenges, we propose an automated framework that combines retrieval-augmented generation (RAG) with LLMs to construct medical indicator knowledge graphs. The framework incorporates guideline-driven data acquisition, ontology-based schema design, and expert-in-the-loop validation to ensure scalability, accuracy, and clinical reliability. The resulting knowledge graphs can be integrated into intelligent diagnosis and question-answering systems, accelerating the development of AI-driven healthcare solutions.
Ancient Script Image Recognition and Processing: A Review
Jun 24, 2025Ancient scripts, e.g., Egyptian hieroglyphs, Oracle Bone Inscriptions, and Ancient Greek inscriptions, serve as vital carriers of human civilization, embedding invaluable historical and cultural information. Automating ancient script image recognition has gained importance, enabling large-scale interpretation and advancing research in archaeology and digital humanities. With the rise of deep learning, this field has progressed rapidly, with numerous script-specific datasets and models proposed. While these scripts vary widely, spanning phonographic systems with limited glyphs to logographic systems with thousands of complex symbols, they share common challenges and methodological overlaps. Moreover, ancient scripts face unique challenges, including imbalanced data distribution and image degradation, which have driven the development of various dedicated methods. This survey provides a comprehensive review of ancient script image recognition methods. We begin by categorizing existing studies based on script types and analyzing respective recognition methods, highlighting both their differences and shared strategies. We then focus on challenges unique to ancient scripts, systematically examining their impact and reviewing recent solutions, including few-shot learning and noise-robust techniques. Finally, we summarize current limitations and outline promising future directions. Our goal is to offer a structured, forward-looking perspective to support ongoing advancements in the recognition, interpretation, and decipherment of ancient scripts.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023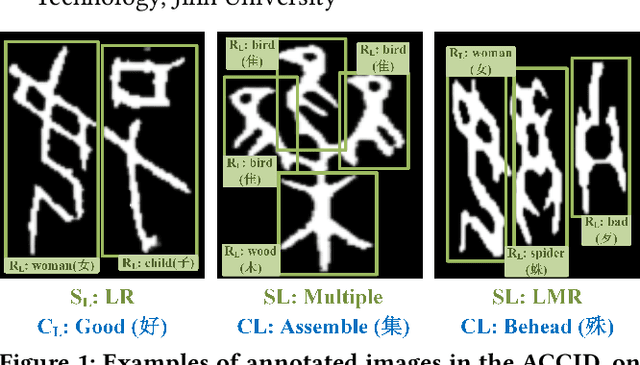
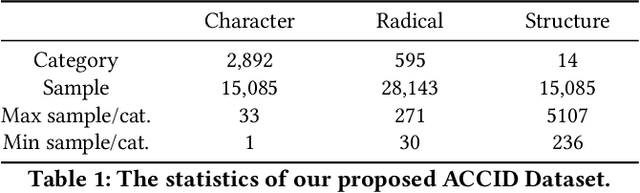
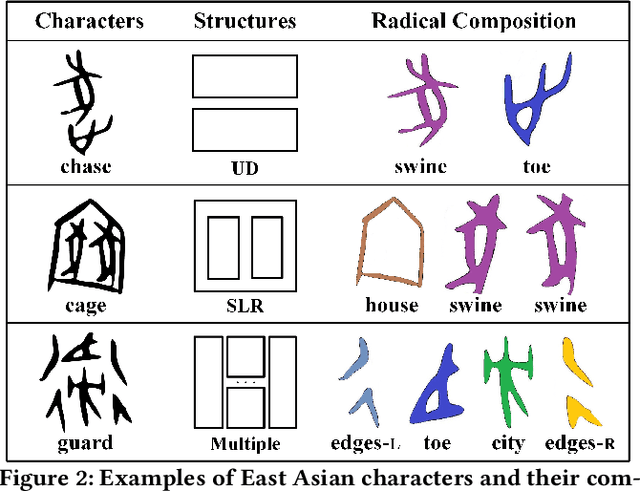

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
A semantics-driven methodology for high-quality image annotation
Jul 26, 2023Recent work in Machine Learning and Computer Vision has highlighted the presence of various types of systematic flaws inside ground truth object recognition benchmark datasets. Our basic tenet is that these flaws are rooted in the many-to-many mappings which exist between the visual information encoded in images and the intended semantics of the labels annotating them. The net consequence is that the current annotation process is largely under-specified, thus leaving too much freedom to the subjective judgment of annotators. In this paper, we propose vTelos, an integrated Natural Language Processing, Knowledge Representation, and Computer Vision methodology whose main goal is to make explicit the (otherwise implicit) intended annotation semantics, thus minimizing the number and role of subjective choices. A key element of vTelos is the exploitation of the WordNet lexico-semantic hierarchy as the main means for providing the meaning of natural language labels and, as a consequence, for driving the annotation of images based on the objects and the visual properties they depict. The methodology is validated on images populating a subset of the ImageNet hierarchy.
Incremental Image Labeling via Iterative Refinement
Apr 18, 2023


Data quality is critical for multimedia tasks, while various types of systematic flaws are found in image benchmark datasets, as discussed in recent work. In particular, the existence of the semantic gap problem leads to a many-to-many mapping between the information extracted from an image and its linguistic description. This unavoidable bias further leads to poor performance on current computer vision tasks. To address this issue, we introduce a Knowledge Representation (KR)-based methodology to provide guidelines driving the labeling process, thereby indirectly introducing intended semantics in ML models. Specifically, an iterative refinement-based annotation method is proposed to optimize data labeling by organizing objects in a classification hierarchy according to their visual properties, ensuring that they are aligned with their linguistic descriptions. Preliminary results verify the effectiveness of the proposed method.
Aligning Visual and Lexical Semantics
Dec 13, 2022We discuss two kinds of semantics relevant to Computer Vision (CV) systems - Visual Semantics and Lexical Semantics. While visual semantics focus on how humans build concepts when using vision to perceive a target reality, lexical semantics focus on how humans build concepts of the same target reality through the use of language. The lack of coincidence between visual and lexical semantics, in turn, has a major impact on CV systems in the form of the Semantic Gap Problem (SGP). The paper, while extensively exemplifying the lack of coincidence as above, introduces a general, domain-agnostic methodology to enforce alignment between visual and lexical semantics.
RCRN: Real-world Character Image Restoration Network via Skeleton Extraction
Jul 19, 2022
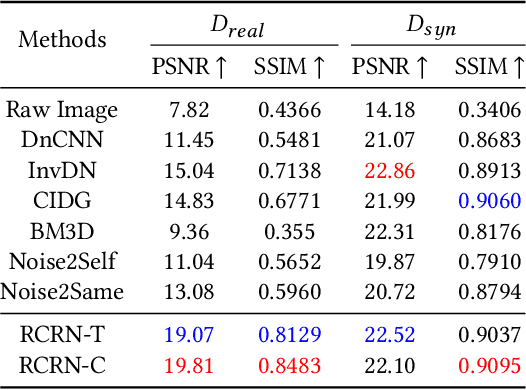

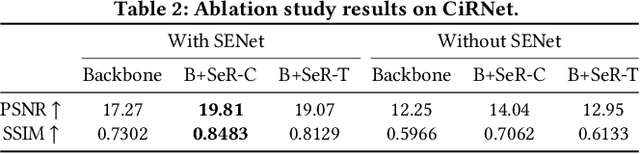
Constructing high-quality character image datasets is challenging because real-world images are often affected by image degradation. There are limitations when applying current image restoration methods to such real-world character images, since (i) the categories of noise in character images are different from those in general images; (ii) real-world character images usually contain more complex image degradation, e.g., mixed noise at different noise levels. To address these problems, we propose a real-world character restoration network (RCRN) to effectively restore degraded character images, where character skeleton information and scale-ensemble feature extraction are utilized to obtain better restoration performance. The proposed method consists of a skeleton extractor (SENet) and a character image restorer (CiRNet). SENet aims to preserve the structural consistency of the character and normalize complex noise. Then, CiRNet reconstructs clean images from degraded character images and their skeletons. Due to the lack of benchmarks for real-world character image restoration, we constructed a dataset containing 1,606 character images with real-world degradation to evaluate the validity of the proposed method. The experimental results demonstrate that RCRN outperforms state-of-the-art methods quantitatively and qualitatively.
CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising
Jul 19, 2022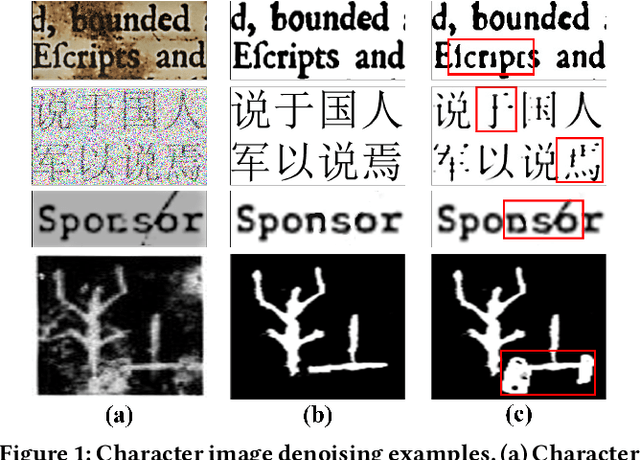
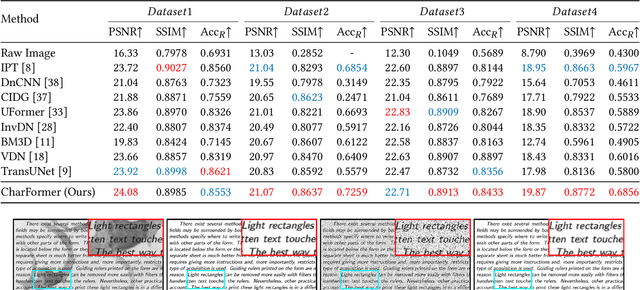
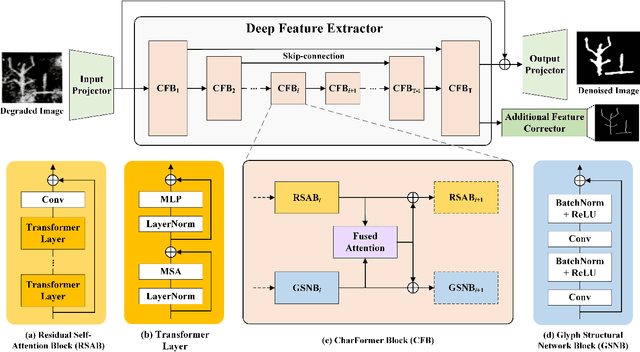
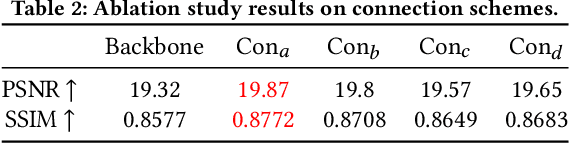
Degraded images commonly exist in the general sources of character images, leading to unsatisfactory character recognition results. Existing methods have dedicated efforts to restoring degraded character images. However, the denoising results obtained by these methods do not appear to improve character recognition performance. This is mainly because current methods only focus on pixel-level information and ignore critical features of a character, such as its glyph, resulting in character-glyph damage during the denoising process. In this paper, we introduce a novel generic framework based on glyph fusion and attention mechanisms, i.e., CharFormer, for precisely recovering character images without changing their inherent glyphs. Unlike existing frameworks, CharFormer introduces a parallel target task for capturing additional information and injecting it into the image denoising backbone, which will maintain the consistency of character glyphs during character image denoising. Moreover, we utilize attention-based networks for global-local feature interaction, which will help to deal with blind denoising and enhance denoising performance. We compare CharFormer with state-of-the-art methods on multiple datasets. The experimental results show the superiority of CharFormer quantitatively and qualitatively.
REZCR: A Zero-shot Character Recognition Method via Radical Extraction
Jul 12, 2022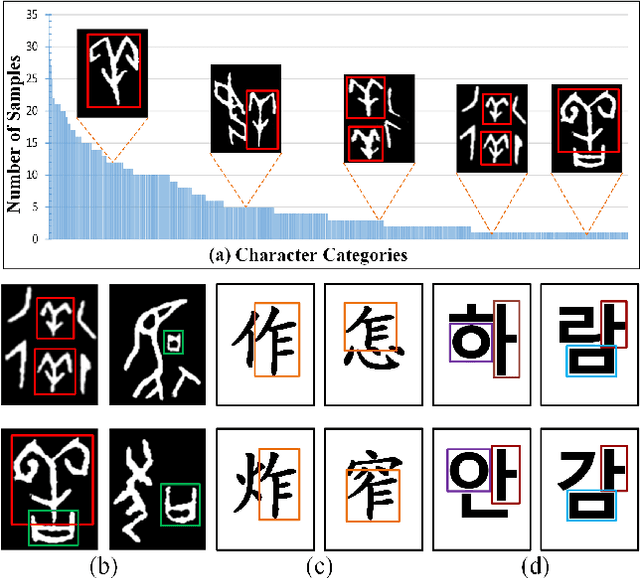
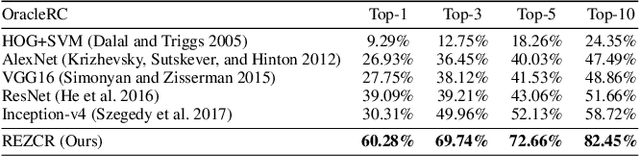

The long-tail effect is a common issue that limits the performance of deep learning models on real-world datasets. Character image dataset development is also affected by such unbalanced data distribution due to differences in character usage frequency. Thus, current character recognition methods are limited when applying to real-world datasets, in particular to the character categories in the tail which are lacking training samples, e.g., uncommon characters, or characters from historical documents. In this paper, we propose a zero-shot character recognition framework via radical extraction, i.e., REZCR, to improve the recognition performance of few-sample character categories, in which we exploit information on radicals, the graphical units of characters, by decomposing and reconstructing characters following orthography. REZCR consists of an attention-based radical information extractor (RIE) and a knowledge graph-based character reasoner (KGR). The RIE aims to recognize candidate radicals and their possible structural relations from character images. The results will be fed into KGR to recognize the target character by reasoning with a pre-designed character knowledge graph. We validate our method on multiple datasets, REZCR shows promising experimental results, especially for few-sample character datasets.