 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiftedBronzes: Benchmarking and Analysis of Domain Fine-Grained Classification in Open-World Settings
Dec 17, 2024In real-world applications across specialized domains, addressing complex out-of-distribution (OOD) challenges is a common and significant concern. In this study, we concentrate on the task of fine-grained bronze ware dating, a critical aspect in the study of ancient Chinese history, and developed a benchmark dataset named ShiftedBronzes. By extensively expanding the bronze Ding dataset, ShiftedBronzes incorporates two types of bronze ware data and seven types of OOD data, which exhibit distribution shifts commonly encountered in bronze ware dating scenarios. We conduct benchmarking experiments on ShiftedBronzes and five commonly used general OOD datasets, employing a variety of widely adopted post-hoc, pre-trained Vision Large Model (VLM)-based and generation-based OOD detection methods. Through analysis of the experimental results, we validate previous conclusions regarding post-hoc, VLM-based, and generation-based methods, while also highlighting their distinct behaviors on specialized datasets. These findings underscore the unique challenges of applying general OOD detection methods to domain-specific tasks such as bronze ware dating. We hope that the ShiftedBronzes benchmark provides valuable insights into both the field of bronze ware dating and the and the development of OOD detection methods. The dataset and associated code will be available later.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023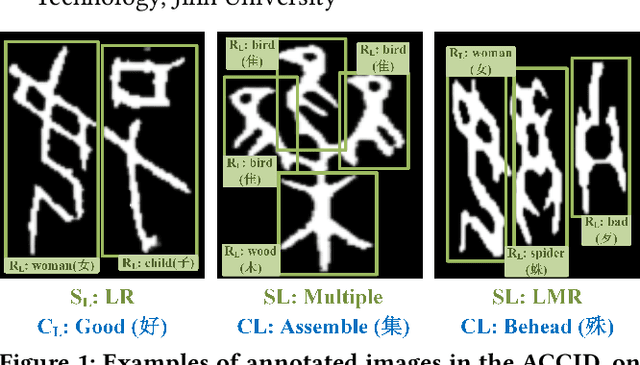
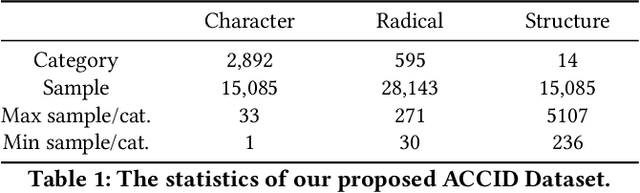
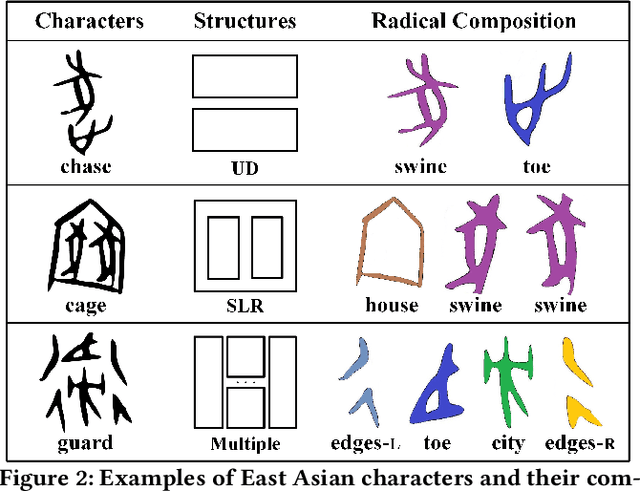

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023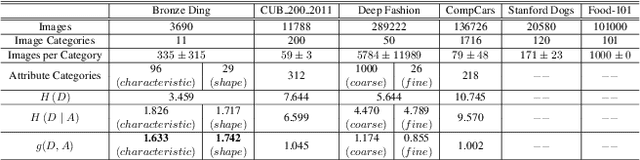
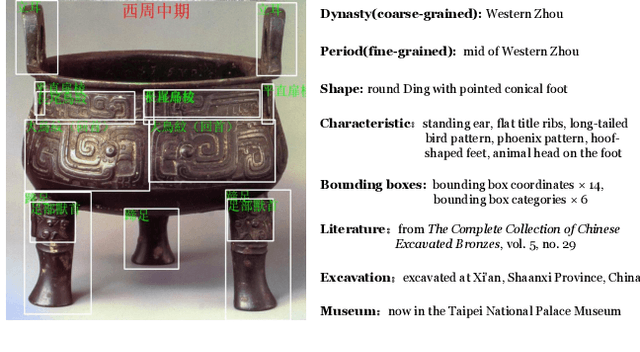
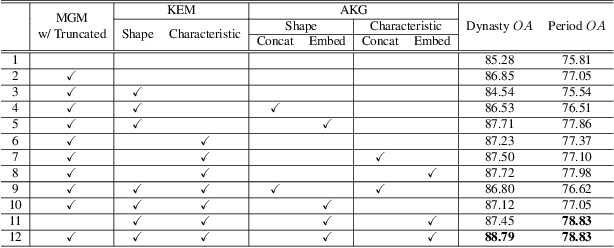
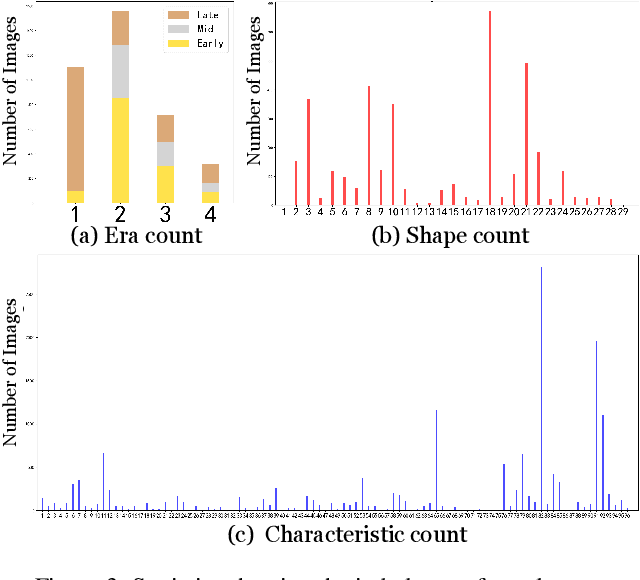
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.