 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLadderMoE: Ladder-Side Mixture of Experts Adapters for Bronze Inscription Recognition
Oct 02, 2025

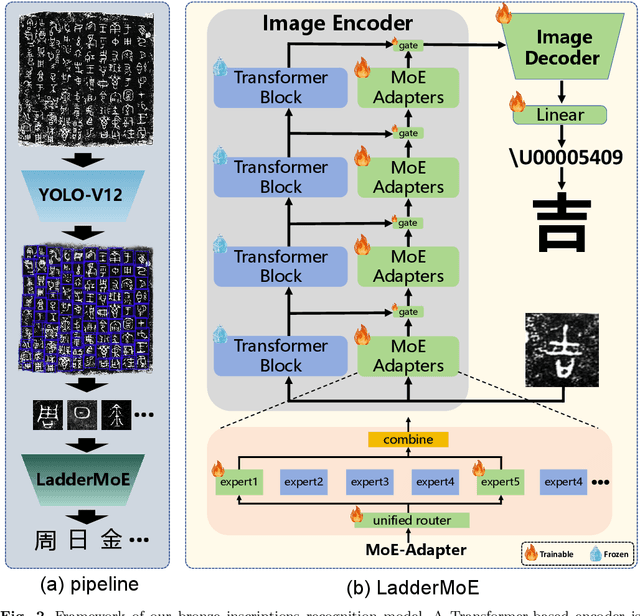

Bronze inscriptions (BI), engraved on ritual vessels, constitute a crucial stage of early Chinese writing and provide indispensable evidence for archaeological and historical studies. However, automatic BI recognition remains difficult due to severe visual degradation, multi-domain variability across photographs, rubbings, and tracings, and an extremely long-tailed character distribution. To address these challenges, we curate a large-scale BI dataset comprising 22454 full-page images and 198598 annotated characters spanning 6658 unique categories, enabling robust cross-domain evaluation. Building on this resource, we develop a two-stage detection-recognition pipeline that first localizes inscriptions and then transcribes individual characters. To handle heterogeneous domains and rare classes, we equip the pipeline with LadderMoE, which augments a pretrained CLIP encoder with ladder-style MoE adapters, enabling dynamic expert specialization and stronger robustness. Comprehensive experiments on single-character and full-page recognition tasks demonstrate that our method substantially outperforms state-of-the-art scene text recognition baselines, achieving superior accuracy across head, mid, and tail categories as well as all acquisition modalities. These results establish a strong foundation for bronze inscription recognition and downstream archaeological analysis.
Clustering-based Feature Representation Learning for Oracle Bone Inscriptions Detection
Aug 26, 2025Oracle Bone Inscriptions (OBIs), play a crucial role in understanding ancient Chinese civilization. The automated detection of OBIs from rubbing images represents a fundamental yet challenging task in digital archaeology, primarily due to various degradation factors including noise and cracks that limit the effectiveness of conventional detection networks. To address these challenges, we propose a novel clustering-based feature space representation learning method. Our approach uniquely leverages the Oracle Bones Character (OBC) font library dataset as prior knowledge to enhance feature extraction in the detection network through clustering-based representation learning. The method incorporates a specialized loss function derived from clustering results to optimize feature representation, which is then integrated into the total network loss. We validate the effectiveness of our method by conducting experiments on two OBIs detection dataset using three mainstream detection frameworks: Faster R-CNN, DETR, and Sparse R-CNN. Through extensive experimentation, all frameworks demonstrate significant performance improvements.
Ancient Script Image Recognition and Processing: A Review
Jun 24, 2025Ancient scripts, e.g., Egyptian hieroglyphs, Oracle Bone Inscriptions, and Ancient Greek inscriptions, serve as vital carriers of human civilization, embedding invaluable historical and cultural information. Automating ancient script image recognition has gained importance, enabling large-scale interpretation and advancing research in archaeology and digital humanities. With the rise of deep learning, this field has progressed rapidly, with numerous script-specific datasets and models proposed. While these scripts vary widely, spanning phonographic systems with limited glyphs to logographic systems with thousands of complex symbols, they share common challenges and methodological overlaps. Moreover, ancient scripts face unique challenges, including imbalanced data distribution and image degradation, which have driven the development of various dedicated methods. This survey provides a comprehensive review of ancient script image recognition methods. We begin by categorizing existing studies based on script types and analyzing respective recognition methods, highlighting both their differences and shared strategies. We then focus on challenges unique to ancient scripts, systematically examining their impact and reviewing recent solutions, including few-shot learning and noise-robust techniques. Finally, we summarize current limitations and outline promising future directions. Our goal is to offer a structured, forward-looking perspective to support ongoing advancements in the recognition, interpretation, and decipherment of ancient scripts.
ShiftedBronzes: Benchmarking and Analysis of Domain Fine-Grained Classification in Open-World Settings
Dec 17, 2024In real-world applications across specialized domains, addressing complex out-of-distribution (OOD) challenges is a common and significant concern. In this study, we concentrate on the task of fine-grained bronze ware dating, a critical aspect in the study of ancient Chinese history, and developed a benchmark dataset named ShiftedBronzes. By extensively expanding the bronze Ding dataset, ShiftedBronzes incorporates two types of bronze ware data and seven types of OOD data, which exhibit distribution shifts commonly encountered in bronze ware dating scenarios. We conduct benchmarking experiments on ShiftedBronzes and five commonly used general OOD datasets, employing a variety of widely adopted post-hoc, pre-trained Vision Large Model (VLM)-based and generation-based OOD detection methods. Through analysis of the experimental results, we validate previous conclusions regarding post-hoc, VLM-based, and generation-based methods, while also highlighting their distinct behaviors on specialized datasets. These findings underscore the unique challenges of applying general OOD detection methods to domain-specific tasks such as bronze ware dating. We hope that the ShiftedBronzes benchmark provides valuable insights into both the field of bronze ware dating and the and the development of OOD detection methods. The dataset and associated code will be available later.
LineArt: A Knowledge-guided Training-free High-quality Appearance Transfer for Design Drawing with Diffusion Model
Dec 16, 2024


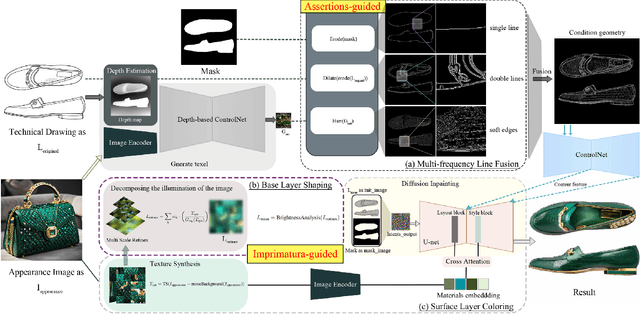
Image rendering from line drawings is vital in design and image generation technologies reduce costs, yet professional line drawings demand preserving complex details. Text prompts struggle with accuracy, and image translation struggles with consistency and fine-grained control. We present LineArt, a framework that transfers complex appearance onto detailed design drawings, facilitating design and artistic creation. It generates high-fidelity appearance while preserving structural accuracy by simulating hierarchical visual cognition and integrating human artistic experience to guide the diffusion process. LineArt overcomes the limitations of current methods in terms of difficulty in fine-grained control and style degradation in design drawings. It requires no precise 3D modeling, physical property specs, or network training, making it more convenient for design tasks. LineArt consists of two stages: a multi-frequency lines fusion module to supplement the input design drawing with detailed structural information and a two-part painting process for Base Layer Shaping and Surface Layer Coloring. We also present a new design drawing dataset ProLines for evaluation. The experiments show that LineArt performs better in accuracy, realism, and material precision compared to SOTAs.
FilterPrompt: Guiding Image Transfer in Diffusion Models
Apr 20, 2024In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
PairingNet: A Learning-based Pair-searching and -matching Network for Image Fragments
Dec 14, 2023In this paper, we propose a learning-based image fragment pair-searching and -matching approach to solve the challenging restoration problem. Existing works use rule-based methods to match similar contour shapes or textures, which are always difficult to tune hyperparameters for extensive data and computationally time-consuming. Therefore, we propose a neural network that can effectively utilize neighbor textures with contour shape information to fundamentally improve performance. First, we employ a graph-based network to extract the local contour and texture features of fragments. Then, for the pair-searching task, we adopt a linear transformer-based module to integrate these local features and use contrastive loss to encode the global features of each fragment. For the pair-matching task, we design a weighted fusion module to dynamically fuse extracted local contour and texture features, and formulate a similarity matrix for each pair of fragments to calculate the matching score and infer the adjacent segment of contours. To faithfully evaluate our proposed network, we created a new image fragment dataset through an algorithm we designed that tears complete images into irregular fragments. The experimental results show that our proposed network achieves excellent pair-searching accuracy, reduces matching errors, and significantly reduces computational time. Details, sourcecode, and data are available in our supplementary material.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023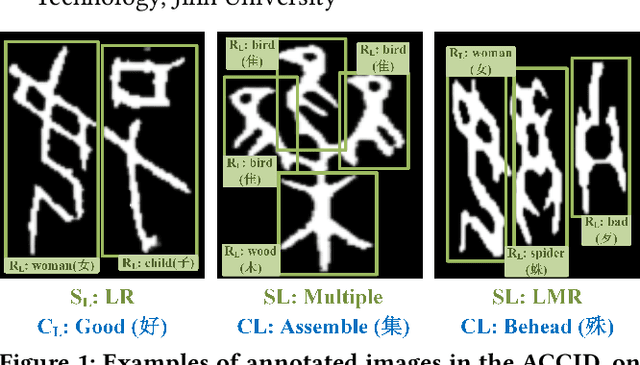
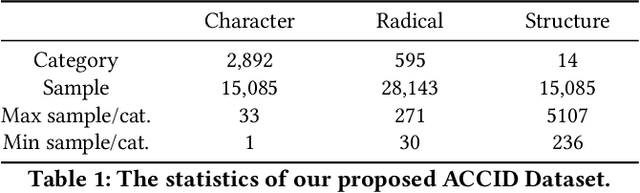
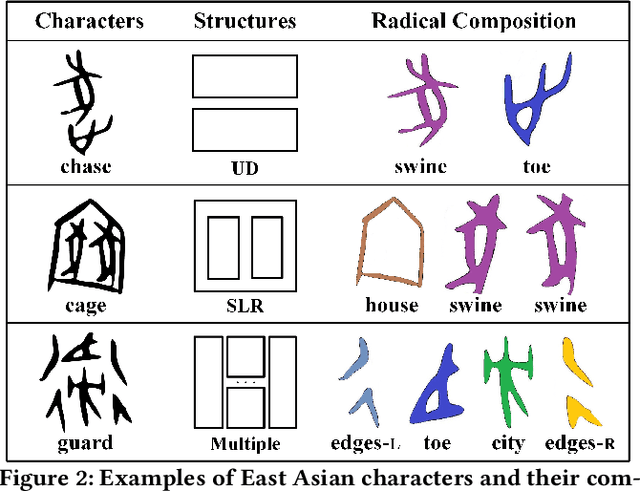

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023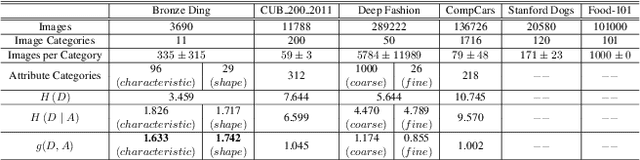
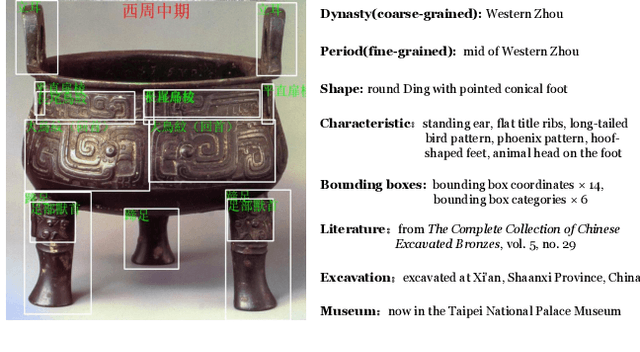
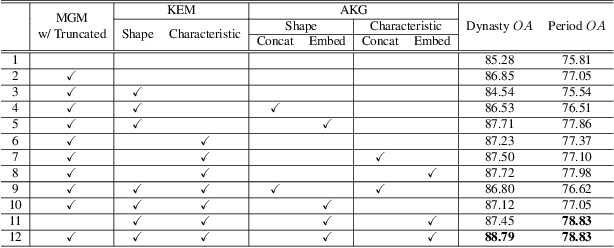
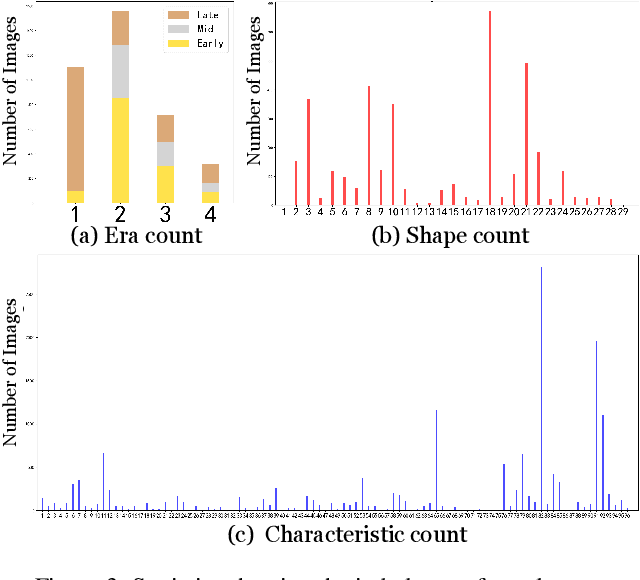
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.
SpaceEditing: Integrating Human Knowledge into Deep Neural Networks via Interactive Latent Space Editing
Dec 08, 2022



We propose an interactive editing method that allows humans to help deep neural networks (DNNs) learn a latent space more consistent with human knowledge, thereby improving classification accuracy on indistinguishable ambiguous data. Firstly, we visualize high-dimensional data features through dimensionality reduction methods and design an interactive system \textit{SpaceEditing} to display the visualized data. \textit{SpaceEditing} provides a 2D workspace based on the idea of spatial layout. In this workspace, the user can move the projection data in it according to the system guidance. Then, \textit{SpaceEditing} will find the corresponding high-dimensional features according to the projection data moved by the user, and feed the high-dimensional features back to the network for retraining, therefore achieving the purpose of interactively modifying the high-dimensional latent space for the user. Secondly, to more rationally incorporate human knowledge into the training process of neural networks, we design a new loss function that enables the network to learn user-modified information. Finally, We demonstrate how \textit{SpaceEditing} meets user needs through three case studies while evaluating our proposed new method, and the results confirm the effectiveness of our method.