 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Robotic Manipulation in Dynamic Environments
Mar 16, 2026Vision-Language-Action (VLA) models excel in static manipulation but struggle in dynamic environments with moving targets. This performance gap primarily stems from a scarcity of dynamic manipulation datasets and the reliance of mainstream VLAs on single-frame observations, restricting their spatiotemporal reasoning capabilities. To address this, we introduce DOMINO, a large-scale dataset and benchmark for generalizable dynamic manipulation, featuring 35 tasks with hierarchical complexities, over 110K expert trajectories, and a multi-dimensional evaluation suite. Through comprehensive experiments, we systematically evaluate existing VLAs on dynamic tasks, explore effective training strategies for dynamic awareness, and validate the generalizability of dynamic data. Furthermore, we propose PUMA, a dynamics-aware VLA architecture. By integrating scene-centric historical optical flow and specialized world queries to implicitly forecast object-centric future states, PUMA couples history-aware perception with short-horizon prediction. Results demonstrate that PUMA achieves state-of-the-art performance, yielding a 6.3% absolute improvement in success rate over baselines. Moreover, we show that training on dynamic data fosters robust spatiotemporal representations that transfer to static tasks. All code and data are available at https://github.com/H-EmbodVis/DOMINO.
Advancing Earth Observation Through Machine Learning: A TorchGeo Tutorial
Mar 02, 2026Earth observation machine learning pipelines differ fundamentally from standard computer vision workflows. Imagery is typically delivered as large, georeferenced scenes, labels may be raster masks or vector geometries in distinct coordinate reference systems, and both training and evaluation often require spatially aware sampling and splitting strategies. TorchGeo is a PyTorch-based domain library that provides datasets, samplers, transforms and pre-trained models with the goal of making it easy to use geospatial data in machine learning pipelines. In this paper, we introduce a tutorial that demonstrates 1.) the core TorchGeo abstractions through code examples, and 2.) an end-to-end case study on multispectral water segmentation from Sentinel-2 imagery using the Earth Surface Water dataset. This demonstrates how to train a semantic segmentation model using TorchGeo datasets, apply the model to a Sentinel-2 scene over Rio de Janeiro, Brazil, and save the resulting predictions as a GeoTIFF for further geospatial analysis. The tutorial code itself is distributed as two Python notebooks: https://torchgeo.readthedocs.io/en/stable/tutorials/torchgeo.html and https://torchgeo.readthedocs.io/en/stable/tutorials/earth_surface_water.html.
Earth Embeddings as Products: Taxonomy, Ecosystem, and Standardized Access
Jan 19, 2026Geospatial Foundation Models (GFMs) provide powerful representations, but high compute costs hinder their widespread use. Pre-computed embedding data products offer a practical "frozen" alternative, yet they currently exist in a fragmented ecosystem of incompatible formats and resolutions. This lack of standardization creates an engineering bottleneck that prevents meaningful model comparison and reproducibility. We formalize this landscape through a three-layer taxonomy: Data, Tools, and Value. We survey existing products to identify interoperability barriers. To bridge this gap, we extend TorchGeo with a unified API that standardizes the loading and querying of diverse embedding products. By treating embeddings as first-class geospatial datasets, we decouple downstream analysis from model-specific engineering, providing a roadmap for more transparent and accessible Earth observation workflows.
Leveraging Satellite Image Time Series for Accurate Extreme Event Detection
Jun 13, 2025Climate change is leading to an increase in extreme weather events, causing significant environmental damage and loss of life. Early detection of such events is essential for improving disaster response. In this work, we propose SITS-Extreme, a novel framework that leverages satellite image time series to detect extreme events by incorporating multiple pre-disaster observations. This approach effectively filters out irrelevant changes while isolating disaster-relevant signals, enabling more accurate detection. Extensive experiments on both real-world and synthetic datasets validate the effectiveness of SITS-Extreme, demonstrating substantial improvements over widely used strong bi-temporal baselines. Additionally, we examine the impact of incorporating more timesteps, analyze the contribution of key components in our framework, and evaluate its performance across different disaster types, offering valuable insights into its scalability and applicability for large-scale disaster monitoring.
LineArt: A Knowledge-guided Training-free High-quality Appearance Transfer for Design Drawing with Diffusion Model
Dec 16, 2024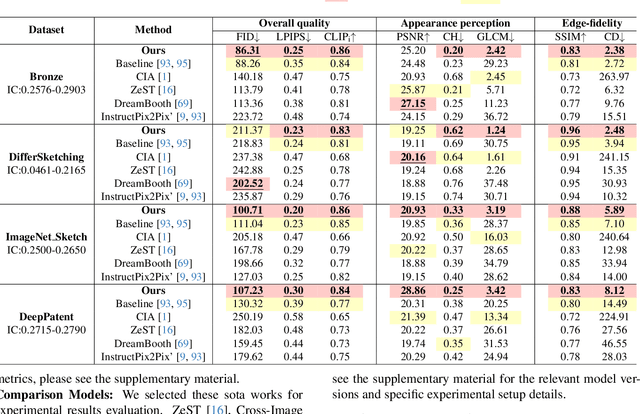


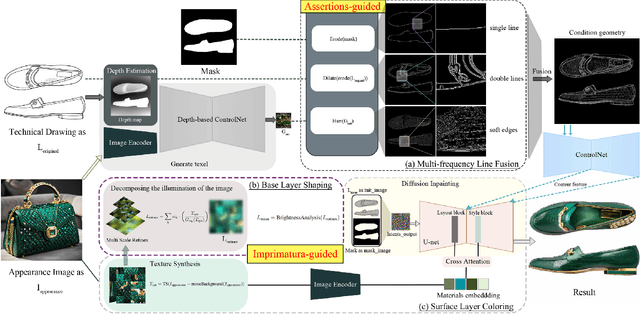
Image rendering from line drawings is vital in design and image generation technologies reduce costs, yet professional line drawings demand preserving complex details. Text prompts struggle with accuracy, and image translation struggles with consistency and fine-grained control. We present LineArt, a framework that transfers complex appearance onto detailed design drawings, facilitating design and artistic creation. It generates high-fidelity appearance while preserving structural accuracy by simulating hierarchical visual cognition and integrating human artistic experience to guide the diffusion process. LineArt overcomes the limitations of current methods in terms of difficulty in fine-grained control and style degradation in design drawings. It requires no precise 3D modeling, physical property specs, or network training, making it more convenient for design tasks. LineArt consists of two stages: a multi-frequency lines fusion module to supplement the input design drawing with detailed structural information and a two-part painting process for Base Layer Shaping and Surface Layer Coloring. We also present a new design drawing dataset ProLines for evaluation. The experiments show that LineArt performs better in accuracy, realism, and material precision compared to SOTAs.
PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models
Dec 05, 2024Geospatial Foundation Models (GFMs) have emerged as powerful tools for extracting representations from Earth observation data, but their evaluation remains inconsistent and narrow. Existing works often evaluate on suboptimal downstream datasets and tasks, that are often too easy or too narrow, limiting the usefulness of the evaluations to assess the real-world applicability of GFMs. Additionally, there is a distinct lack of diversity in current evaluation protocols, which fail to account for the multiplicity of image resolutions, sensor types, and temporalities, which further complicates the assessment of GFM performance. In particular, most existing benchmarks are geographically biased towards North America and Europe, questioning the global applicability of GFMs. To overcome these challenges, we introduce PANGAEA, a standardized evaluation protocol that covers a diverse set of datasets, tasks, resolutions, sensor modalities, and temporalities. It establishes a robust and widely applicable benchmark for GFMs. We evaluate the most popular GFMs openly available on this benchmark and analyze their performance across several domains. In particular, we compare these models to supervised baselines (e.g. UNet and vanilla ViT), and assess their effectiveness when faced with limited labeled data. Our findings highlight the limitations of GFMs, under different scenarios, showing that they do not consistently outperform supervised models. PANGAEA is designed to be highly extensible, allowing for the seamless inclusion of new datasets, models, and tasks in future research. By releasing the evaluation code and benchmark, we aim to enable other researchers to replicate our experiments and build upon our work, fostering a more principled evaluation protocol for large pre-trained geospatial models. The code is available at https://github.com/VMarsocci/pangaea-bench.
SAM-MIL: A Spatial Contextual Aware Multiple Instance Learning Approach for Whole Slide Image Classification
Jul 25, 2024
Multiple Instance Learning (MIL) represents the predominant framework in Whole Slide Image (WSI) classification, covering aspects such as sub-typing, diagnosis, and beyond. Current MIL models predominantly rely on instance-level features derived from pretrained models such as ResNet. These models segment each WSI into independent patches and extract features from these local patches, leading to a significant loss of global spatial context and restricting the model's focus to merely local features. To address this issue, we propose a novel MIL framework, named SAM-MIL, that emphasizes spatial contextual awareness and explicitly incorporates spatial context by extracting comprehensive, image-level information. The Segment Anything Model (SAM) represents a pioneering visual segmentation foundational model that can capture segmentation features without the need for additional fine-tuning, rendering it an outstanding tool for extracting spatial context directly from raw WSIs. Our approach includes the design of group feature extraction based on spatial context and a SAM-Guided Group Masking strategy to mitigate class imbalance issues. We implement a dynamic mask ratio for different segmentation categories and supplement these with representative group features of categories. Moreover, SAM-MIL divides instances to generate additional pseudo-bags, thereby augmenting the training set, and introduces consistency of spatial context across pseudo-bags to further enhance the model's performance. Experimental results on the CAMELYON-16 and TCGA Lung Cancer datasets demonstrate that our proposed SAM-MIL model outperforms existing mainstream methods in WSIs classification. Our open-source implementation code is is available at https://github.com/FangHeng/SAM-MIL.
Continuous Urban Change Detection from Satellite Image Time Series with Temporal Feature Refinement and Multi-Task Integration
Jun 25, 2024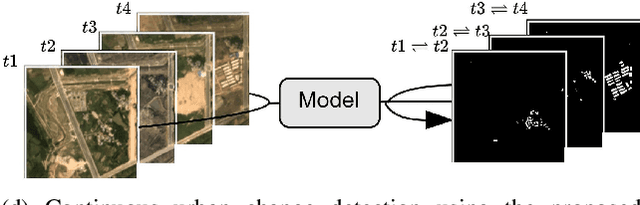
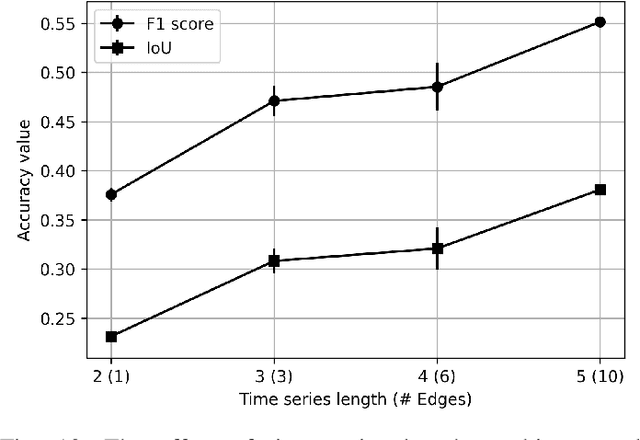
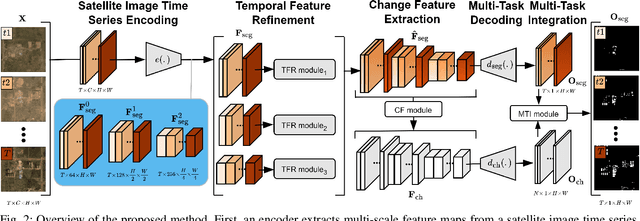
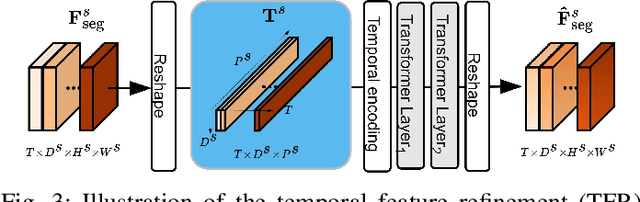
Urbanization advances at unprecedented rates, resulting in negative effects on the environment and human well-being. Remote sensing has the potential to mitigate these effects by supporting sustainable development strategies with accurate information on urban growth. Deep learning-based methods have achieved promising urban change detection results from optical satellite image pairs using convolutional neural networks (ConvNets), transformers, and a multi-task learning setup. However, transformers have not been leveraged for urban change detection with multi-temporal data, i.e., >2 images, and multi-task learning methods lack integration approaches that combine change and segmentation outputs. To fill this research gap, we propose a continuous urban change detection method that identifies changes in each consecutive image pair of a satellite image time series. Specifically, we propose a temporal feature refinement (TFR) module that utilizes self-attention to improve ConvNet-based multi-temporal building representations. Furthermore, we propose a multi-task integration (MTI) module that utilizes Markov networks to find an optimal building map time series based on segmentation and dense change outputs. The proposed method effectively identifies urban changes based on high-resolution satellite image time series acquired by the PlanetScope constellation (F1 score 0.551) and Gaofen-2 (F1 score 0.440). Moreover, our experiments on two challenging datasets demonstrate the effectiveness of the proposed method compared to bi-temporal and multi-temporal urban change detection and segmentation methods.
FilterPrompt: Guiding Image Transfer in Diffusion Models
Apr 20, 2024In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
DeFlow: Decoder of Scene Flow Network in Autonomous Driving
Jan 29, 2024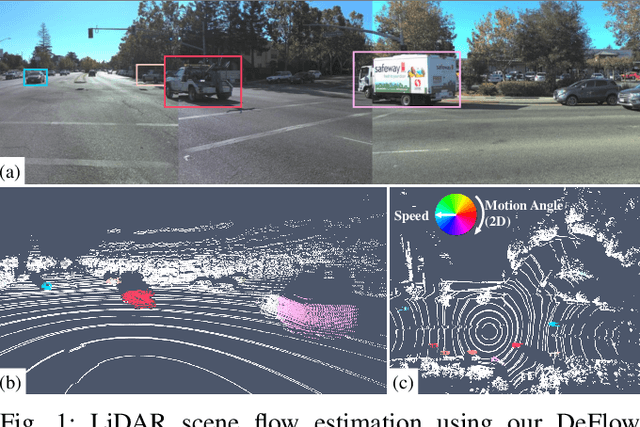
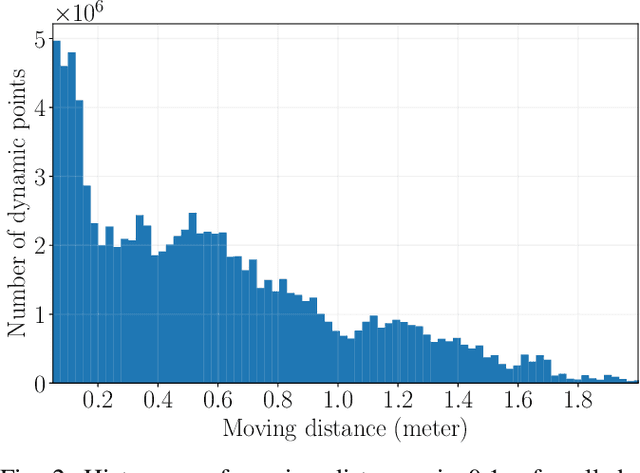
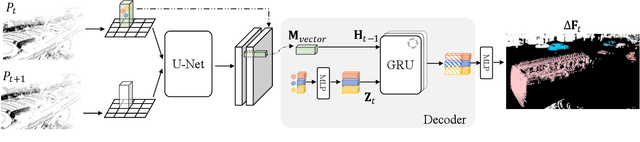
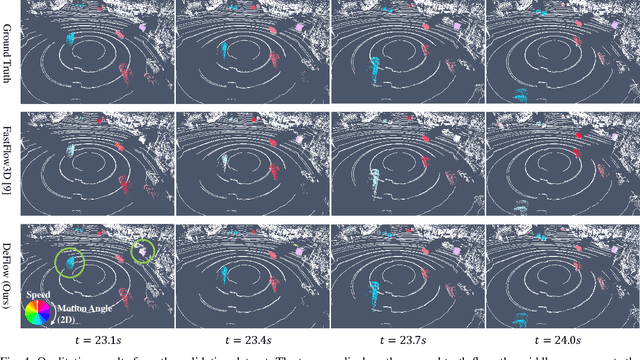
Scene flow estimation determines a scene's 3D motion field, by predicting the motion of points in the scene, especially for aiding tasks in autonomous driving. Many networks with large-scale point clouds as input use voxelization to create a pseudo-image for real-time running. However, the voxelization process often results in the loss of point-specific features. This gives rise to a challenge in recovering those features for scene flow tasks. Our paper introduces DeFlow which enables a transition from voxel-based features to point features using Gated Recurrent Unit (GRU) refinement. To further enhance scene flow estimation performance, we formulate a novel loss function that accounts for the data imbalance between static and dynamic points. Evaluations on the Argoverse 2 scene flow task reveal that DeFlow achieves state-of-the-art results on large-scale point cloud data, demonstrating that our network has better performance and efficiency compared to others. The code is open-sourced at https://github.com/KTH-RPL/deflow.