 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-Informed 3D Multi-Object Tracking under Adverse Conditions
Apr 15, 2026The challenge of 3D multi-object tracking (3D MOT) is achieving robustness in real-world applications, for example under adverse conditions and maintaining consistency as distance increases. To overcome these challenges, sensor fusion approaches that combine LiDAR, cameras, and radar have emerged. However, existing multi-modal fusion methods usually treat radar as another learned feature inside the network. When the overall model degrades in difficult environmental conditions, the robustness advantages that radar could provide are also reduced. We propose RadarMOT, a radar-informed 3D MOT framework that explicitly uses radar point cloud data as additional observation to refine state estimation and recover detector misses at long ranges. Evaluations on the MAN-TruckScenes dataset show that RadarMOT consistently improves the Average Multi-Object Tracking Accuracy (AMOTA) with absolute 12.7% at long range and 10.3% in adverse weather. The code will be available at https://github.com/bingxue-xu/radarmot
SynFlow: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data
Apr 10, 2026Reliable 3D dynamic perception requires models that can anticipate motion beyond predefined categories, yet progress is hindered by the scarcity of dense, high-quality motion annotations. While self-supervision on unlabeled real data offers a path forward, empirical evidence suggests that scaling unlabeled data fails to close the performance gap due to noisy proxy signals. In this paper, we propose a shift in paradigm: learning robust real-world motion priors entirely from scalable simulation. We introduce SynFlow, a data generation pipeline that generates large-scale synthetic dataset specifically designed for LiDAR scene flow. Unlike prior works that prioritize sensor-specific realism, SynFlow employs a motion-oriented strategy to synthesize diverse kinematic patterns across 4,000 sequences ($\sim$940k frames), termed SynFlow-4k. This represents a 34x scale-up in annotated volume over existing real-world benchmarks. Our experiments demonstrate that SynFlow-4k provides a highly domain-invariant motion prior. In a zero-shot regime, models trained exclusively on our synthetic data generalize across multiple real-world benchmarks, rivaling in-domain supervised baselines on nuScenes and outperforming state-of-the-art methods on TruckScenes by 31.8%. Furthermore, SynFlow-4k serves as a label-efficient foundation: fine-tuning with only 5% of real-world labels surpasses models trained from scratch on the full available budget. We open-source the pipeline and dataset to facilitate research in generalizable 3D motion estimation. More detail can be found at https://kin-zhang.github.io/SynFlow.
TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Feb 22, 2026Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.
Visible Structure Retrieval for Lightweight Image-Based Relocalisation
Nov 16, 2025Accurate camera pose estimation from an image observation in a previously mapped environment is commonly done through structure-based methods: by finding correspondences between 2D keypoints on the image and 3D structure points in the map. In order to make this correspondence search tractable in large scenes, existing pipelines either rely on search heuristics, or perform image retrieval to reduce the search space by comparing the current image to a database of past observations. However, these approaches result in elaborate pipelines or storage requirements that grow with the number of past observations. In this work, we propose a new paradigm for making structure-based relocalisation tractable. Instead of relying on image retrieval or search heuristics, we learn a direct mapping from image observations to the visible scene structure in a compact neural network. Given a query image, a forward pass through our novel visible structure retrieval network allows obtaining the subset of 3D structure points in the map that the image views, thus reducing the search space of 2D-3D correspondences. We show that our proposed method enables performing localisation with an accuracy comparable to the state of the art, while requiring lower computational and storage footprint.
ArgoTweak: Towards Self-Updating HD Maps through Structured Priors
Sep 10, 2025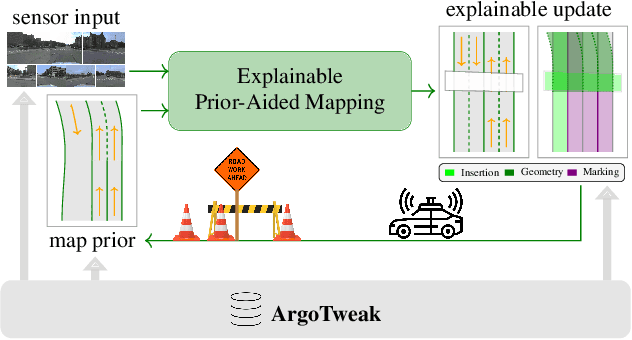
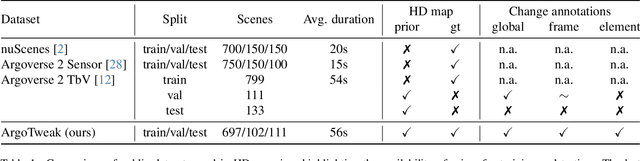
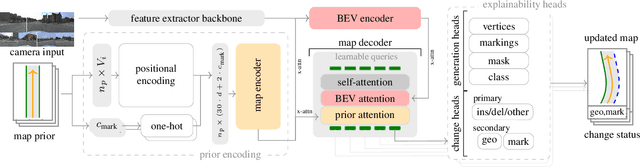
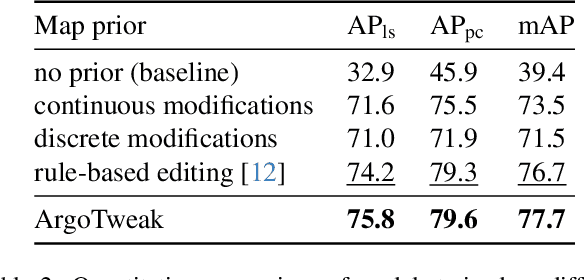
Reliable integration of prior information is crucial for self-verifying and self-updating HD maps. However, no public dataset includes the required triplet of prior maps, current maps, and sensor data. As a result, existing methods must rely on synthetic priors, which create inconsistencies and lead to a significant sim2real gap. To address this, we introduce ArgoTweak, the first dataset to complete the triplet with realistic map priors. At its core, ArgoTweak employs a bijective mapping framework, breaking down large-scale modifications into fine-grained atomic changes at the map element level, thus ensuring interpretability. This paradigm shift enables accurate change detection and integration while preserving unchanged elements with high fidelity. Experiments show that training models on ArgoTweak significantly reduces the sim2real gap compared to synthetic priors. Extensive ablations further highlight the impact of structured priors and detailed change annotations. By establishing a benchmark for explainable, prior-aided HD mapping, ArgoTweak advances scalable, self-improving mapping solutions. The dataset, baselines, map modification toolbox, and further resources are available at https://kth-rpl.github.io/ArgoTweak/.
DeltaFlow: An Efficient Multi-frame Scene Flow Estimation Method
Aug 23, 2025



Previous dominant methods for scene flow estimation focus mainly on input from two consecutive frames, neglecting valuable information in the temporal domain. While recent trends shift towards multi-frame reasoning, they suffer from rapidly escalating computational costs as the number of frames grows. To leverage temporal information more efficiently, we propose DeltaFlow ($\Delta$Flow), a lightweight 3D framework that captures motion cues via a $\Delta$ scheme, extracting temporal features with minimal computational cost, regardless of the number of frames. Additionally, scene flow estimation faces challenges such as imbalanced object class distributions and motion inconsistency. To tackle these issues, we introduce a Category-Balanced Loss to enhance learning across underrepresented classes and an Instance Consistency Loss to enforce coherent object motion, improving flow accuracy. Extensive evaluations on the Argoverse 2 and Waymo datasets show that $\Delta$Flow achieves state-of-the-art performance with up to 22% lower error and $2\times$ faster inference compared to the next-best multi-frame supervised method, while also demonstrating a strong cross-domain generalization ability. The code is open-sourced at https://github.com/Kin-Zhang/DeltaFlow along with trained model weights.
PRIX: Learning to Plan from Raw Pixels for End-to-End Autonomous Driving
Jul 24, 2025While end-to-end autonomous driving models show promising results, their practical deployment is often hindered by large model sizes, a reliance on expensive LiDAR sensors and computationally intensive BEV feature representations. This limits their scalability, especially for mass-market vehicles equipped only with cameras. To address these challenges, we propose PRIX (Plan from Raw Pixels). Our novel and efficient end-to-end driving architecture operates using only camera data, without explicit BEV representation and forgoing the need for LiDAR. PRIX leverages a visual feature extractor coupled with a generative planning head to predict safe trajectories from raw pixel inputs directly. A core component of our architecture is the Context-aware Recalibration Transformer (CaRT), a novel module designed to effectively enhance multi-level visual features for more robust planning. We demonstrate through comprehensive experiments that PRIX achieves state-of-the-art performance on the NavSim and nuScenes benchmarks, matching the capabilities of larger, multimodal diffusion planners while being significantly more efficient in terms of inference speed and model size, making it a practical solution for real-world deployment. Our work is open-source and the code will be at https://maxiuw.github.io/prix.
Quantifying Epistemic Uncertainty in Absolute Pose Regression
Apr 09, 2025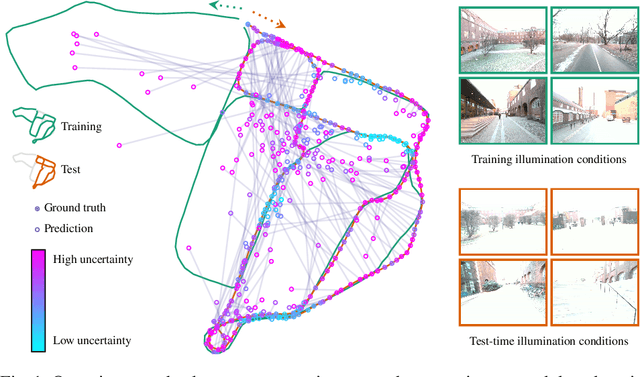
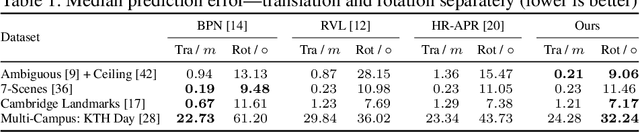

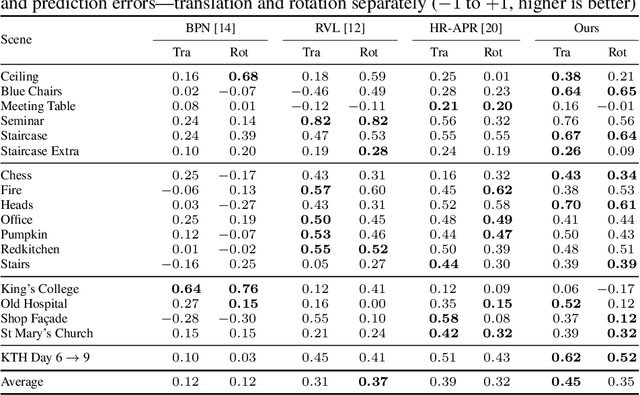
Visual relocalization is the task of estimating the camera pose given an image it views. Absolute pose regression offers a solution to this task by training a neural network, directly regressing the camera pose from image features. While an attractive solution in terms of memory and compute efficiency, absolute pose regression's predictions are inaccurate and unreliable outside the training domain. In this work, we propose a novel method for quantifying the epistemic uncertainty of an absolute pose regression model by estimating the likelihood of observations within a variational framework. Beyond providing a measure of confidence in predictions, our approach offers a unified model that also handles observation ambiguities, probabilistically localizing the camera in the presence of repetitive structures. Our method outperforms existing approaches in capturing the relation between uncertainty and prediction error.
SSF: Sparse Long-Range Scene Flow for Autonomous Driving
Jan 29, 2025



Scene flow enables an understanding of the motion characteristics of the environment in the 3D world. It gains particular significance in the long-range, where object-based perception methods might fail due to sparse observations far away. Although significant advancements have been made in scene flow pipelines to handle large-scale point clouds, a gap remains in scalability with respect to long-range. We attribute this limitation to the common design choice of using dense feature grids, which scale quadratically with range. In this paper, we propose Sparse Scene Flow (SSF), a general pipeline for long-range scene flow, adopting a sparse convolution based backbone for feature extraction. This approach introduces a new challenge: a mismatch in size and ordering of sparse feature maps between time-sequential point scans. To address this, we propose a sparse feature fusion scheme, that augments the feature maps with virtual voxels at missing locations. Additionally, we propose a range-wise metric that implicitly gives greater importance to faraway points. Our method, SSF, achieves state-of-the-art results on the Argoverse2 dataset, demonstrating strong performance in long-range scene flow estimation. Our code will be released at https://github.com/KTH-RPL/SSF.git.
Conditional Variational Autoencoders for Probabilistic Pose Regression
Oct 07, 2024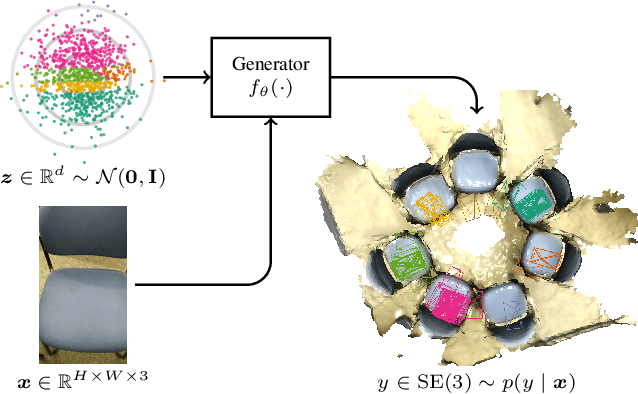
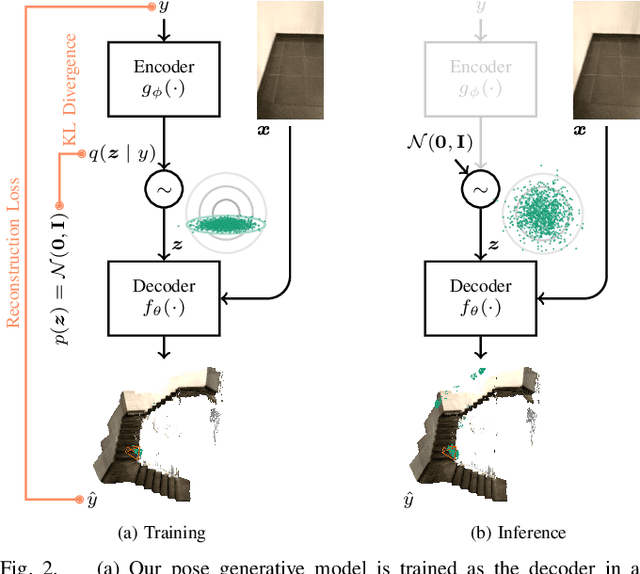
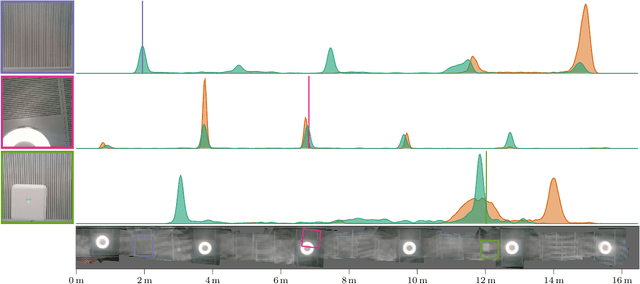
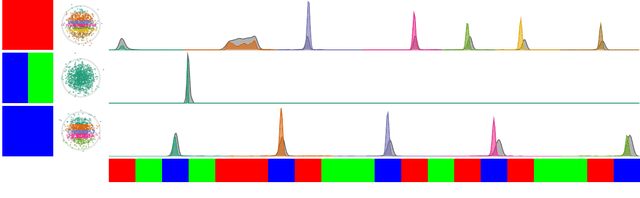
Robots rely on visual relocalization to estimate their pose from camera images when they lose track. One of the challenges in visual relocalization is repetitive structures in the operation environment of the robot. This calls for probabilistic methods that support multiple hypotheses for robot's pose. We propose such a probabilistic method to predict the posterior distribution of camera poses given an observed image. Our proposed training strategy results in a generative model of camera poses given an image, which can be used to draw samples from the pose posterior distribution. Our method is streamlined and well-founded in theory and outperforms existing methods on localization in presence of ambiguities.