 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-MiniGPT4: Multilingual VLLM Alignment via Translated Data
Mar 31, 2026This paper presents a Multilingual Vision Large Language Model, named M-MiniGPT4. Our model exhibits strong vision-language understanding (VLU) capabilities across 11 languages. We utilize a mixture of native multilingual and translated data to push the multilingual VLU performance of the MiniGPT4 architecture. In addition, we propose a multilingual alignment training stage that uses parallel text corpora to further enhance the multilingual capabilities of our model. M-MiniGPT4 achieves 36% accuracy on the multilingual MMMU benchmark, outperforming state-of-the-art models in the same weight class, including foundation models released after the majority of this work was completed. We open-source our models, code, and translated datasets to facilitate future research in low-resource and multilingual settings.
XProvence: Zero-Cost Multilingual Context Pruning for Retrieval-Augmented Generation
Jan 26, 2026This paper introduces XProvence, a multilingual zero-cost context pruning model for retrieval-augmented generation (RAG), trained on 16 languages and supporting 100+ languages through effective cross-lingual transfer. Motivated by the growing use of RAG systems across diverse languages, we explore several strategies to generalize the Provence framework-which first integrated efficient zero-cost context pruning directly into the re-ranking model-beyond English. Across four multilingual question answering benchmarks, we show how XProvence can prune RAG contexts with minimal-to-no performance degradation and outperforms strong baselines. Our model is available at https://huggingface.co/naver/xprovence-reranker-bgem3-v2.
Two Birds with One Stone: Multi-Task Detection and Attribution of LLM-Generated Text
Aug 19, 2025Large Language Models (LLMs), such as GPT-4 and Llama, have demonstrated remarkable abilities in generating natural language. However, they also pose security and integrity challenges. Existing countermeasures primarily focus on distinguishing AI-generated content from human-written text, with most solutions tailored for English. Meanwhile, authorship attribution--determining which specific LLM produced a given text--has received comparatively little attention despite its importance in forensic analysis. In this paper, we present DA-MTL, a multi-task learning framework that simultaneously addresses both text detection and authorship attribution. We evaluate DA-MTL on nine datasets and four backbone models, demonstrating its strong performance across multiple languages and LLM sources. Our framework captures each task's unique characteristics and shares insights between them, which boosts performance in both tasks. Additionally, we conduct a thorough analysis of cross-modal and cross-lingual patterns and assess the framework's robustness against adversarial obfuscation techniques. Our findings offer valuable insights into LLM behavior and the generalization of both detection and authorship attribution.
DeepChest: Dynamic Gradient-Free Task Weighting for Effective Multi-Task Learning in Chest X-ray Classification
May 29, 2025



While Multi-Task Learning (MTL) offers inherent advantages in complex domains such as medical imaging by enabling shared representation learning, effectively balancing task contributions remains a significant challenge. This paper addresses this critical issue by introducing DeepChest, a novel, computationally efficient and effective dynamic task-weighting framework specifically designed for multi-label chest X-ray (CXR) classification. Unlike existing heuristic or gradient-based methods that often incur substantial overhead, DeepChest leverages a performance-driven weighting mechanism based on effective analysis of task-specific loss trends. Given a network architecture (e.g., ResNet18), our model-agnostic approach adaptively adjusts task importance without requiring gradient access, thereby significantly reducing memory usage and achieving a threefold increase in training speed. It can be easily applied to improve various state-of-the-art methods. Extensive experiments on a large-scale CXR dataset demonstrate that DeepChest not only outperforms state-of-the-art MTL methods by 7% in overall accuracy but also yields substantial reductions in individual task losses, indicating improved generalization and effective mitigation of negative transfer. The efficiency and performance gains of DeepChest pave the way for more practical and robust deployment of deep learning in critical medical diagnostic applications. The code is publicly available at https://github.com/youssefkhalil320/DeepChest-MTL
VR-RAG: Open-vocabulary Species Recognition with RAG-Assisted Large Multi-Modal Models
May 08, 2025Open-vocabulary recognition remains a challenging problem in computer vision, as it requires identifying objects from an unbounded set of categories. This is particularly relevant in nature, where new species are discovered every year. In this work, we focus on open-vocabulary bird species recognition, where the goal is to classify species based on their descriptions without being constrained to a predefined set of taxonomic categories. Traditional benchmarks like CUB-200-2011 and Birdsnap have been evaluated in a closed-vocabulary paradigm, limiting their applicability to real-world scenarios where novel species continually emerge. We show that the performance of current systems when evaluated under settings closely aligned with open-vocabulary drops by a huge margin. To address this gap, we propose a scalable framework integrating structured textual knowledge from Wikipedia articles of 11,202 bird species distilled via GPT-4o into concise, discriminative summaries. We propose Visual Re-ranking Retrieval-Augmented Generation(VR-RAG), a novel, retrieval-augmented generation framework that uses visual similarities to rerank the top m candidates retrieved by a set of multimodal vision language encoders. This allows for the recognition of unseen taxa. Extensive experiments across five established classification benchmarks show that our approach is highly effective. By integrating VR-RAG, we improve the average performance of state-of-the-art Large Multi-Modal Model QWEN2.5-VL by 15.4% across five benchmarks. Our approach outperforms conventional VLM-based approaches, which struggle with unseen species. By bridging the gap between encyclopedic knowledge and visual recognition, our work advances open-vocabulary recognition, offering a flexible, scalable solution for biodiversity monitoring and ecological research.
No Culture Left Behind: ArtELingo-28, a Benchmark of WikiArt with Captions in 28 Languages
Nov 06, 2024Research in vision and language has made considerable progress thanks to benchmarks such as COCO. COCO captions focused on unambiguous facts in English; ArtEmis introduced subjective emotions and ArtELingo introduced some multilinguality (Chinese and Arabic). However we believe there should be more multilinguality. Hence, we present ArtELingo-28, a vision-language benchmark that spans $\textbf{28}$ languages and encompasses approximately $\textbf{200,000}$ annotations ($\textbf{140}$ annotations per image). Traditionally, vision research focused on unambiguous class labels, whereas ArtELingo-28 emphasizes diversity of opinions over languages and cultures. The challenge is to build machine learning systems that assign emotional captions to images. Baseline results will be presented for three novel conditions: Zero-Shot, Few-Shot and One-vs-All Zero-Shot. We find that cross-lingual transfer is more successful for culturally-related languages. Data and code are provided at www.artelingo.org.
Fusion in Context: A Multimodal Approach to Affective State Recognition
Sep 18, 2024
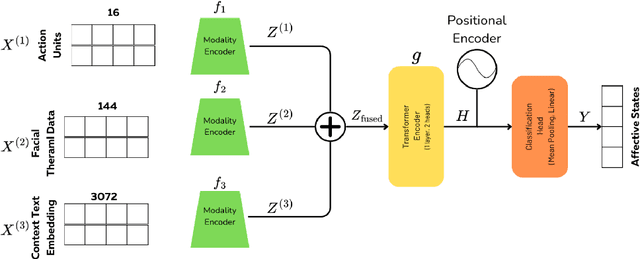
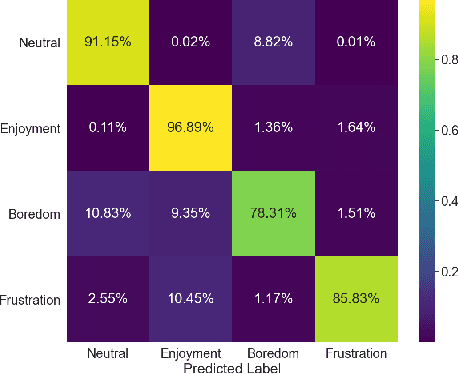

Accurate recognition of human emotions is a crucial challenge in affective computing and human-robot interaction (HRI). Emotional states play a vital role in shaping behaviors, decisions, and social interactions. However, emotional expressions can be influenced by contextual factors, leading to misinterpretations if context is not considered. Multimodal fusion, combining modalities like facial expressions, speech, and physiological signals, has shown promise in improving affect recognition. This paper proposes a transformer-based multimodal fusion approach that leverages facial thermal data, facial action units, and textual context information for context-aware emotion recognition. We explore modality-specific encoders to learn tailored representations, which are then fused using additive fusion and processed by a shared transformer encoder to capture temporal dependencies and interactions. The proposed method is evaluated on a dataset collected from participants engaged in a tangible tabletop Pacman game designed to induce various affective states. Our results demonstrate the effectiveness of incorporating contextual information and multimodal fusion for affective state recognition.
ResumeAtlas: Revisiting Resume Classification with Large-Scale Datasets and Large Language Models
Jun 26, 2024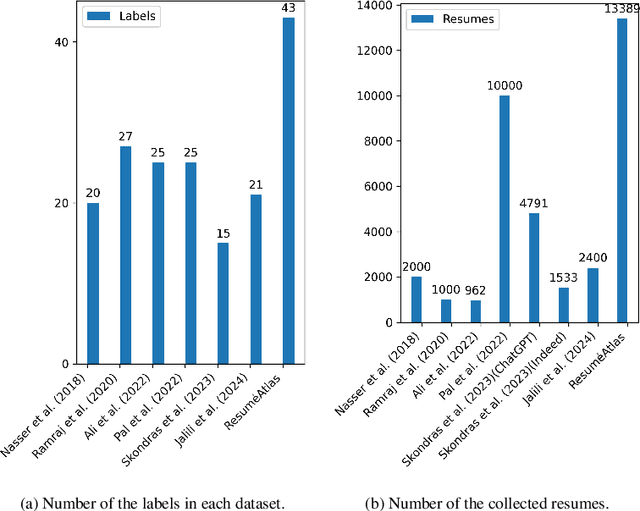

The increasing reliance on online recruitment platforms coupled with the adoption of AI technologies has highlighted the critical need for efficient resume classification methods. However, challenges such as small datasets, lack of standardized resume templates, and privacy concerns hinder the accuracy and effectiveness of existing classification models. In this work, we address these challenges by presenting a comprehensive approach to resume classification. We curated a large-scale dataset of 13,389 resumes from diverse sources and employed Large Language Models (LLMs) such as BERT and Gemma1.1 2B for classification. Our results demonstrate significant improvements over traditional machine learning approaches, with our best model achieving a top-1 accuracy of 92\% and a top-5 accuracy of 97.5\%. These findings underscore the importance of dataset quality and advanced model architectures in enhancing the accuracy and robustness of resume classification systems, thus advancing the field of online recruitment practices.
Arabic Handwritten Text for Person Biometric Identification: A Deep Learning Approach
Jun 01, 2024This study thoroughly investigates how well deep learning models can recognize Arabic handwritten text for person biometric identification. It compares three advanced architectures -- ResNet50, MobileNetV2, and EfficientNetB7 -- using three widely recognized datasets: AHAWP, Khatt, and LAMIS-MSHD. Results show that EfficientNetB7 outperforms the others, achieving test accuracies of 98.57\%, 99.15\%, and 99.79\% on AHAWP, Khatt, and LAMIS-MSHD datasets, respectively. EfficientNetB7's exceptional performance is credited to its innovative techniques, including compound scaling, depth-wise separable convolutions, and squeeze-and-excitation blocks. These features allow the model to extract more abstract and distinctive features from handwritten text images. The study's findings hold significant implications for enhancing identity verification and authentication systems, highlighting the potential of deep learning in Arabic handwritten text recognition for person biometric identification.
Advancing Ear Biometrics: Enhancing Accuracy and Robustness through Deep Learning
May 31, 2024Biometric identification is a reliable method to verify individuals based on their unique physical or behavioral traits, offering a secure alternative to traditional methods like passwords or PINs. This study focuses on ear biometric identification, exploiting its distinctive features for enhanced accuracy, reliability, and usability. While past studies typically investigate face recognition and fingerprint analysis, our research demonstrates the effectiveness of ear biometrics in overcoming limitations such as variations in facial expressions and lighting conditions. We utilized two datasets: AMI (700 images from 100 individuals) and EarNV1.0 (28,412 images from 164 individuals). To improve the accuracy and robustness of our ear biometric identification system, we applied various techniques including data preprocessing and augmentation. Our models achieved a testing accuracy of 99.35% on the AMI Dataset and 98.1% on the EarNV1.0 dataset, showcasing the effectiveness of our approach in precisely identifying individuals based on ear biometric characteristics.