 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepChest: Dynamic Gradient-Free Task Weighting for Effective Multi-Task Learning in Chest X-ray Classification
May 29, 2025While Multi-Task Learning (MTL) offers inherent advantages in complex domains such as medical imaging by enabling shared representation learning, effectively balancing task contributions remains a significant challenge. This paper addresses this critical issue by introducing DeepChest, a novel, computationally efficient and effective dynamic task-weighting framework specifically designed for multi-label chest X-ray (CXR) classification. Unlike existing heuristic or gradient-based methods that often incur substantial overhead, DeepChest leverages a performance-driven weighting mechanism based on effective analysis of task-specific loss trends. Given a network architecture (e.g., ResNet18), our model-agnostic approach adaptively adjusts task importance without requiring gradient access, thereby significantly reducing memory usage and achieving a threefold increase in training speed. It can be easily applied to improve various state-of-the-art methods. Extensive experiments on a large-scale CXR dataset demonstrate that DeepChest not only outperforms state-of-the-art MTL methods by 7% in overall accuracy but also yields substantial reductions in individual task losses, indicating improved generalization and effective mitigation of negative transfer. The efficiency and performance gains of DeepChest pave the way for more practical and robust deployment of deep learning in critical medical diagnostic applications. The code is publicly available at https://github.com/youssefkhalil320/DeepChest-MTL
Revolutionizing Communication with Deep Learning and XAI for Enhanced Arabic Sign Language Recognition
Jan 14, 2025



This study introduces an integrated approach to recognizing Arabic Sign Language (ArSL) using state-of-the-art deep learning models such as MobileNetV3, ResNet50, and EfficientNet-B2. These models are further enhanced by explainable AI (XAI) techniques to boost interpretability. The ArSL2018 and RGB Arabic Alphabets Sign Language (AASL) datasets are employed, with EfficientNet-B2 achieving peak accuracies of 99.48\% and 98.99\%, respectively. Key innovations include sophisticated data augmentation methods to mitigate class imbalance, implementation of stratified 5-fold cross-validation for better generalization, and the use of Grad-CAM for clear model decision transparency. The proposed system not only sets new benchmarks in recognition accuracy but also emphasizes interpretability, making it suitable for applications in healthcare, education, and inclusive communication technologies.
Advanced Arabic Alphabet Sign Language Recognition Using Transfer Learning and Transformer Models
Oct 01, 2024



This paper presents an Arabic Alphabet Sign Language recognition approach, using deep learning methods in conjunction with transfer learning and transformer-based models. We study the performance of the different variants on two publicly available datasets, namely ArSL2018 and AASL. This task will make full use of state-of-the-art CNN architectures like ResNet50, MobileNetV2, and EfficientNetB7, and the latest transformer models such as Google ViT and Microsoft Swin Transformer. These pre-trained models have been fine-tuned on the above datasets in an attempt to capture some unique features of Arabic sign language motions. Experimental results present evidence that the suggested methodology can receive a high recognition accuracy, by up to 99.6\% and 99.43\% on ArSL2018 and AASL, respectively. That is far beyond the previously reported state-of-the-art approaches. This performance opens up even more avenues for communication that may be more accessible to Arabic-speaking deaf and hard-of-hearing, and thus encourages an inclusive society.
* 6 pages, 8 figures
TikGuard: A Deep Learning Transformer-Based Solution for Detecting Unsuitable TikTok Content for Kids
Oct 01, 2024The rise of short-form videos on platforms like TikTok has brought new challenges in safeguarding young viewers from inappropriate content. Traditional moderation methods often fall short in handling the vast and rapidly changing landscape of user-generated videos, increasing the risk of children encountering harmful material. This paper introduces TikGuard, a transformer-based deep learning approach aimed at detecting and flagging content unsuitable for children on TikTok. By using a specially curated dataset, TikHarm, and leveraging advanced video classification techniques, TikGuard achieves an accuracy of 86.7%, showing a notable improvement over existing methods in similar contexts. While direct comparisons are limited by the uniqueness of the TikHarm dataset, TikGuard's performance highlights its potential in enhancing content moderation, contributing to a safer online experience for minors. This study underscores the effectiveness of transformer models in video classification and sets a foundation for future research in this area.
AraSpider: Democratizing Arabic-to-SQL
Feb 12, 2024This study presents AraSpider, the first Arabic version of the Spider dataset, aimed at improving natural language processing (NLP) in the Arabic-speaking community. Four multilingual translation models were tested for their effectiveness in translating English to Arabic. Additionally, two models were assessed for their ability to generate SQL queries from Arabic text. The results showed that using back translation significantly improved the performance of both ChatGPT 3.5 and SQLCoder models, which are considered top performers on the Spider dataset. Notably, ChatGPT 3.5 demonstrated high-quality translation, while SQLCoder excelled in text-to-SQL tasks. The study underscores the importance of incorporating contextual schema and employing back translation strategies to enhance model performance in Arabic NLP tasks. Moreover, the provision of detailed methodologies for reproducibility and translation of the dataset into other languages highlights the research's commitment to promoting transparency and collaborative knowledge sharing in the field. Overall, these contributions advance NLP research, empower Arabic-speaking researchers, and enrich the global discourse on language comprehension and database interrogation.
Markov Switching Model for Driver Behavior Prediction: Use cases on Smartphones
Aug 29, 2021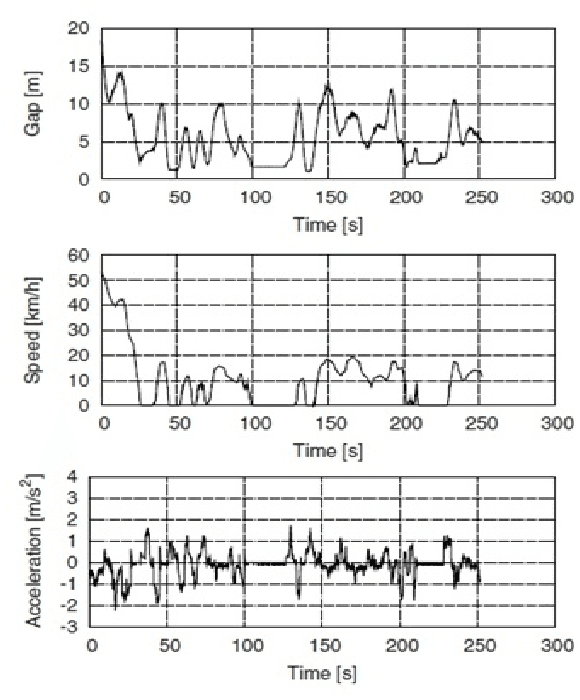


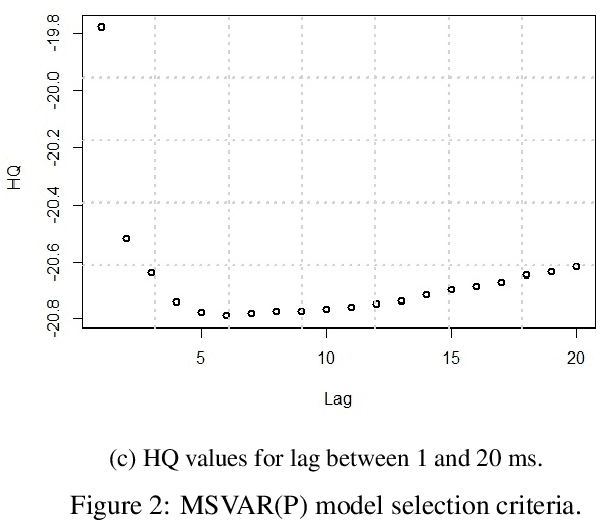
Several intelligent transportation systems focus on studying the various driver behaviors for numerous objectives. This includes the ability to analyze driver actions, sensitivity, distraction, and response time. As the data collection is one of the major concerns for learning and validating different driving situations, we present a driver behavior switching model validated by a low-cost data collection solution using smartphones. The proposed model is validated using a real dataset to predict the driver behavior in short duration periods. A literature survey on motion detection (specifically driving behavior detection using smartphones) is presented. Multiple Markov Switching Variable Auto-Regression (MSVAR) models are implemented to achieve a sophisticated fitting with the collected driver behavior data. This yields more accurate predictions not only for driver behavior but also for the entire driving situation. The performance of the presented models together with a suitable model selection criteria is also presented. The proposed driver behavior prediction framework can potentially be used in accident prediction and driver safety systems.
Generative Neural Network based Spectrum Sharing using Linear Sum Assignment Problems
Oct 12, 2019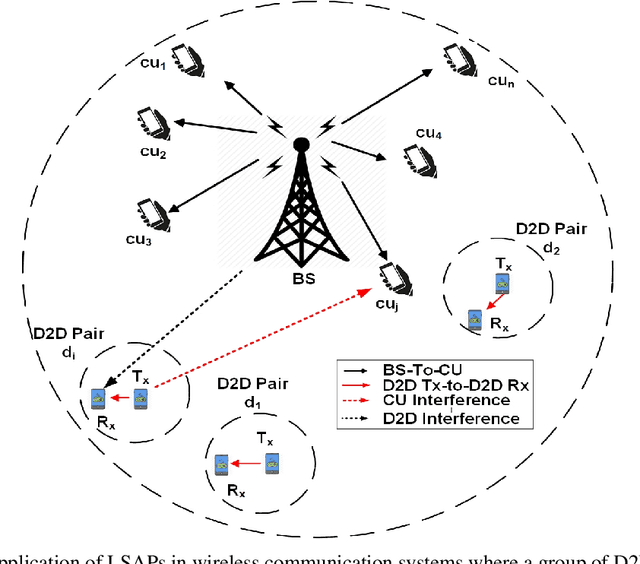

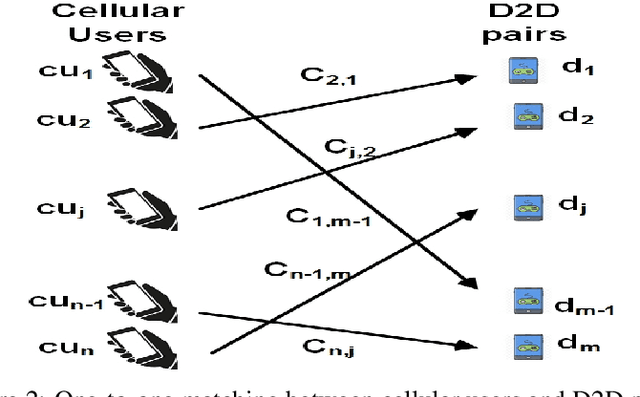

Spectrum management and resource allocation (RA) problems are challenging and critical in a vast number of research areas such as wireless communications and computer networks. The traditional approaches for solving such problems usually consume time and memory, especially for large size problems. Recently different machine learning approaches have been considered as potential promising techniques for combinatorial optimization problems, especially the generative model of the deep neural networks. In this work, we propose a resource allocation deep autoencoder network, as one of the promising generative models, for enabling spectrum sharing in underlay device-to-device (D2D) communication by solving linear sum assignment problems (LSAPs). Specifically, we investigate the performance of three different architectures for the conditional variational autoencoders (CVAE). The three proposed architecture are the convolutional neural network (CVAE-CNN) autoencoder, the feed-forward neural network (CVAE-FNN) autoencoder, and the hybrid (H-CVAE) autoencoder. The simulation results show that the proposed approach could be used as a replacement of the conventional RA techniques, such as the Hungarian algorithm, due to its ability to find solutions of LASPs of different sizes with high accuracy and very fast execution time. Moreover, the simulation results reveal that the accuracy of the proposed hybrid autoencoder architecture outperforms the other proposed architectures and the state-of-the-art DNN techniques.