 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Neural Network based Spectrum Sharing using Linear Sum Assignment Problems
Oct 12, 2019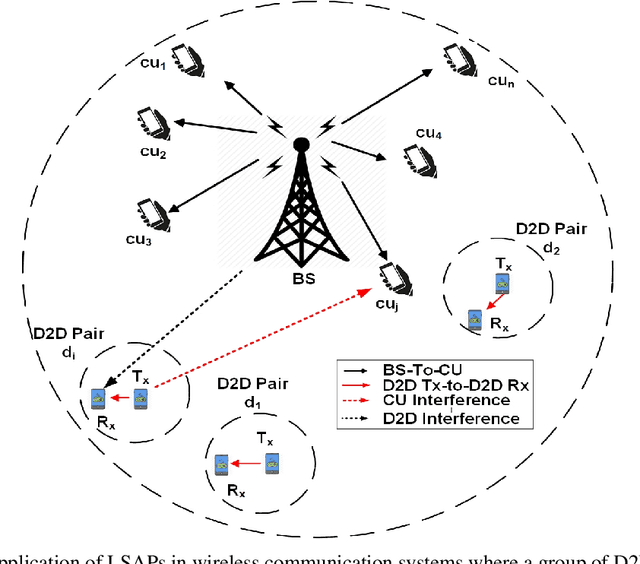

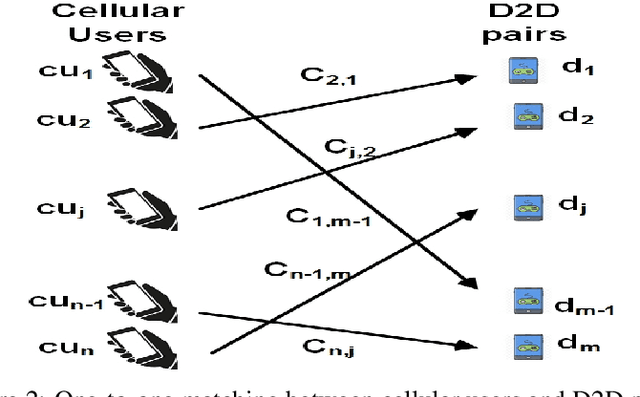

Spectrum management and resource allocation (RA) problems are challenging and critical in a vast number of research areas such as wireless communications and computer networks. The traditional approaches for solving such problems usually consume time and memory, especially for large size problems. Recently different machine learning approaches have been considered as potential promising techniques for combinatorial optimization problems, especially the generative model of the deep neural networks. In this work, we propose a resource allocation deep autoencoder network, as one of the promising generative models, for enabling spectrum sharing in underlay device-to-device (D2D) communication by solving linear sum assignment problems (LSAPs). Specifically, we investigate the performance of three different architectures for the conditional variational autoencoders (CVAE). The three proposed architecture are the convolutional neural network (CVAE-CNN) autoencoder, the feed-forward neural network (CVAE-FNN) autoencoder, and the hybrid (H-CVAE) autoencoder. The simulation results show that the proposed approach could be used as a replacement of the conventional RA techniques, such as the Hungarian algorithm, due to its ability to find solutions of LASPs of different sizes with high accuracy and very fast execution time. Moreover, the simulation results reveal that the accuracy of the proposed hybrid autoencoder architecture outperforms the other proposed architectures and the state-of-the-art DNN techniques.
A Random Sample Partition Data Model for Big Data Analysis
Jan 20, 2018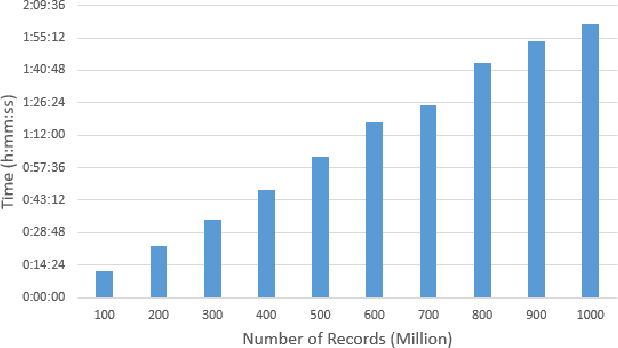
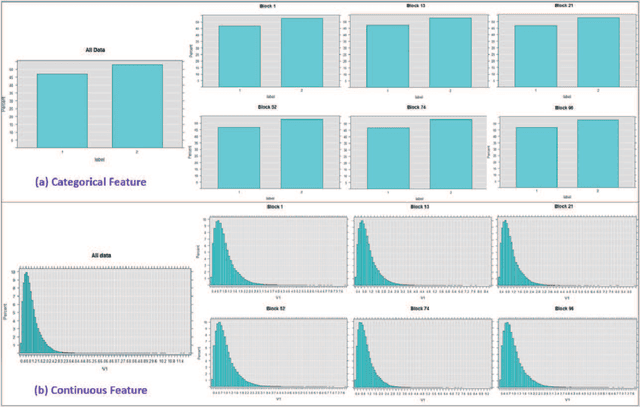

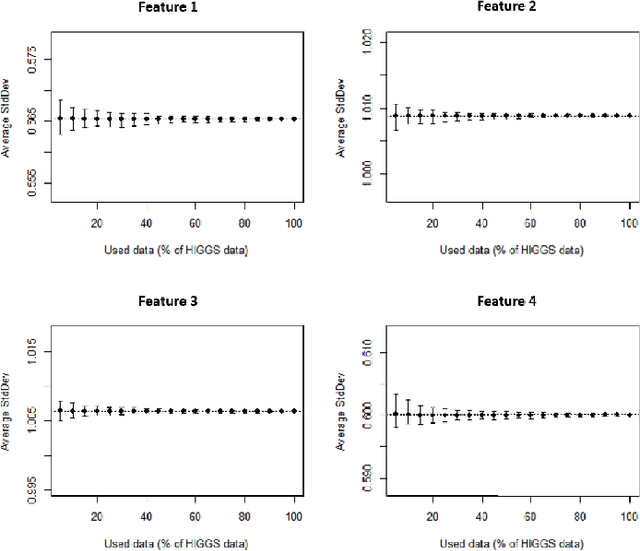
Big data sets must be carefully partitioned into statistically similar data subsets that can be used as representative samples for big data analysis tasks. In this paper, we propose the random sample partition (RSP) data model to represent a big data set as a set of non-overlapping data subsets, called RSP data blocks, where each RSP data block has a probability distribution similar to the whole big data set. Under this data model, efficient block level sampling is used to randomly select RSP data blocks, replacing expensive record level sampling to select sample data from a big distributed data set on a computing cluster. We show how RSP data blocks can be employed to estimate statistics of a big data set and build models which are equivalent to those built from the whole big data set. In this approach, analysis of a big data set becomes analysis of few RSP data blocks which have been generated in advance on the computing cluster. Therefore, the new method for data analysis based on RSP data blocks is scalable to big data.
Clustering Categorical Data Streams
Dec 13, 2004

The data stream model has been defined for new classes of applications involving massive data being generated at a fast pace. Web click stream analysis and detection of network intrusions are two examples. Cluster analysis on data streams becomes more difficult, because the data objects in a data stream must be accessed in order and can be read only once or few times with limited resources. Recently, a few clustering algorithms have been developed for analyzing numeric data streams. However, to our knowledge to date, no algorithm exists for clustering categorical data streams. In this paper, we propose an efficient clustering algorithm for analyzing categorical data streams. It has been proved that the proposed algorithm uses small memory footprints. We provide empirical analysis on the performance of the algorithm in clustering both synthetic and real data streams