 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR$^2$Seg: Decomposed Two-Stage Rollouts for Efficient Reasoning Segmentation in Multimodal Large Language Models
Jan 15, 2026Reasoning segmentation is an emerging vision-language task that requires reasoning over intricate text queries to precisely segment objects. However, existing methods typically suffer from overthinking, generating verbose reasoning chains that interfere with object localization in multimodal large language models (MLLMs). To address this issue, we propose DR$^2$Seg, a self-rewarding framework that improves both reasoning efficiency and segmentation accuracy without requiring extra thinking supervision. DR$^2$Seg employs a two-stage rollout strategy that decomposes reasoning segmentation into multimodal reasoning and referring segmentation. In the first stage, the model generates a self-contained description that explicitly specifies the target object. In the second stage, this description replaces the original complex query to verify its self-containment. Based on this design, two self-rewards are introduced to strengthen goal-oriented reasoning and suppress redundant thinking. Extensive experiments across MLLMs of varying scales and segmentation models demonstrate that DR$^2$Seg consistently improves reasoning efficiency and overall segmentation performance.
Unified Coding for Both Human Perception and Generalized Machine Analytics with CLIP Supervision
Jan 08, 2025



The image compression model has long struggled with adaptability and generalization, as the decoded bitstream typically serves only human or machine needs and fails to preserve information for unseen visual tasks. Therefore, this paper innovatively introduces supervision obtained from multimodal pre-training models and incorporates adaptive multi-objective optimization tailored to support both human visual perception and machine vision simultaneously with a single bitstream, denoted as Unified and Generalized Image Coding for Machine (UG-ICM). Specifically, to get rid of the reliance between compression models with downstream task supervision, we introduce Contrastive Language-Image Pre-training (CLIP) models into the training constraint for improved generalization. Global-to-instance-wise CLIP supervision is applied to help obtain hierarchical semantics that make models more generalizable for the tasks relying on the information of different granularity. Furthermore, for supporting both human and machine visions with only a unifying bitstream, we incorporate a conditional decoding strategy that takes as conditions human or machine preferences, enabling the bitstream to be decoded into different versions for corresponding preferences. As such, our proposed UG-ICM is fully trained in a self-supervised manner, i.e., without awareness of any specific downstream models and tasks. The extensive experiments have shown that the proposed UG-ICM is capable of achieving remarkable improvements in various unseen machine analytics tasks, while simultaneously providing perceptually satisfying images.
Sliced Maximal Information Coefficient: A Training-Free Approach for Image Quality Assessment Enhancement
Aug 19, 2024
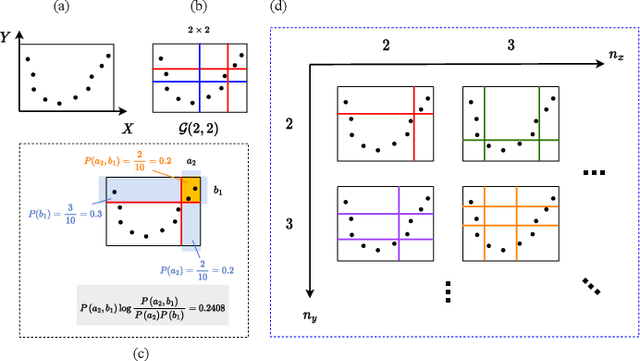
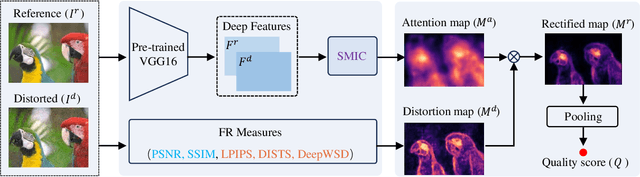
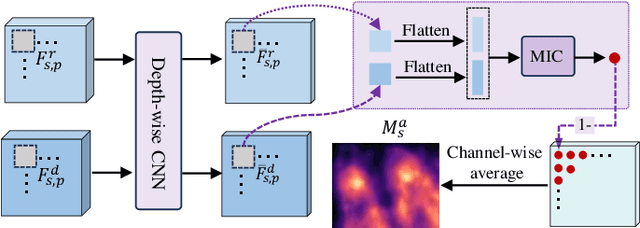
Full-reference image quality assessment (FR-IQA) models generally operate by measuring the visual differences between a degraded image and its reference. However, existing FR-IQA models including both the classical ones (eg, PSNR and SSIM) and deep-learning based measures (eg, LPIPS and DISTS) still exhibit limitations in capturing the full perception characteristics of the human visual system (HVS). In this paper, instead of designing a new FR-IQA measure, we aim to explore a generalized human visual attention estimation strategy to mimic the process of human quality rating and enhance existing IQA models. In particular, we model human attention generation by measuring the statistical dependency between the degraded image and the reference image. The dependency is captured in a training-free manner by our proposed sliced maximal information coefficient and exhibits surprising generalization in different IQA measures. Experimental results verify the performance of existing IQA models can be consistently improved when our attention module is incorporated. The source code is available at https://github.com/KANGX99/SMIC.
Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement
Jul 18, 2024Occupancy prediction plays a pivotal role in autonomous driving (AD) due to the fine-grained geometric perception and general object recognition capabilities. However, existing methods often incur high computational costs, which contradicts the real-time demands of AD. To this end, we first evaluate the speed and memory usage of most public available methods, aiming to redirect the focus from solely prioritizing accuracy to also considering efficiency. We then identify a core challenge in achieving both fast and accurate performance: \textbf{the strong coupling between geometry and semantic}. To address this issue, 1) we propose a Geometric-Semantic Dual-Branch Network (GSDBN) with a hybrid BEV-Voxel representation. In the BEV branch, a BEV-level temporal fusion module and a U-Net encoder is introduced to extract dense semantic features. In the voxel branch, a large-kernel re-parameterized 3D convolution is proposed to refine sparse 3D geometry and reduce computation. Moreover, we propose a novel BEV-Voxel lifting module that projects BEV features into voxel space for feature fusion of the two branches. In addition to the network design, 2) we also propose a Geometric-Semantic Decoupled Learning (GSDL) strategy. This strategy initially learns semantics with accurate geometry using ground-truth depth, and then gradually mixes predicted depth to adapt the model to the predicted geometry. Extensive experiments on the widely-used Occ3D-nuScenes benchmark demonstrate the superiority of our method, which achieves a 39.4 mIoU with 20.0 FPS. This result is $\sim 3 \times$ faster and +1.9 mIoU higher compared to FB-OCC, the winner of CVPR2023 3D Occupancy Prediction Challenge. Our code will be made open-source.
USD: Unknown Sensitive Detector Empowered by Decoupled Objectness and Segment Anything Model
Jun 04, 2023



Open World Object Detection (OWOD) is a novel and challenging computer vision task that enables object detection with the ability to detect unknown objects. Existing methods typically estimate the object likelihood with an additional objectness branch, but ignore the conflict in learning objectness and classification boundaries, which oppose each other on the semantic manifold and training objective. To address this issue, we propose a simple yet effective learning strategy, namely Decoupled Objectness Learning (DOL), which divides the learning of these two boundaries into suitable decoder layers. Moreover, detecting unknown objects comprehensively requires a large amount of annotations, but labeling all unknown objects is both difficult and expensive. Therefore, we propose to take advantage of the recent Large Vision Model (LVM), specifically the Segment Anything Model (SAM), to enhance the detection of unknown objects. Nevertheless, the output results of SAM contain noise, including backgrounds and fragments, so we introduce an Auxiliary Supervision Framework (ASF) that uses a pseudo-labeling and a soft-weighting strategies to alleviate the negative impact of noise. Extensive experiments on popular benchmarks, including Pascal VOC and MS COCO, demonstrate the effectiveness of our approach. Our proposed Unknown Sensitive Detector (USD) outperforms the recent state-of-the-art methods in terms of Unknown Recall, achieving significant improvements of 14.3\%, 15.5\%, and 8.9\% on the M-OWODB, and 27.1\%, 29.1\%, and 25.1\% on the S-OWODB.
Pseudo-label Correction and Learning For Semi-Supervised Object Detection
Mar 06, 2023



Pseudo-Labeling has emerged as a simple yet effective technique for semi-supervised object detection (SSOD). However, the inevitable noise problem in pseudo-labels significantly degrades the performance of SSOD methods. Recent advances effectively alleviate the classification noise in SSOD, while the localization noise which is a non-negligible part of SSOD is not well-addressed. In this paper, we analyse the localization noise from the generation and learning phases, and propose two strategies, namely pseudo-label correction and noise-unaware learning. For pseudo-label correction, we introduce a multi-round refining method and a multi-vote weighting method. The former iteratively refines the pseudo boxes to improve the stability of predictions, while the latter smoothly self-corrects pseudo boxes by weighing the scores of surrounding jittered boxes. For noise-unaware learning, we introduce a loss weight function that is negatively correlated with the Intersection over Union (IoU) in the regression task, which pulls the predicted boxes closer to the object and improves localization accuracy. Our proposed method, Pseudo-label Correction and Learning (PCL), is extensively evaluated on the MS COCO and PASCAL VOC benchmarks. On MS COCO, PCL outperforms the supervised baseline by 12.16, 12.11, and 9.57 mAP and the recent SOTA (SoftTeacher) by 3.90, 2.54, and 2.43 mAP under 1\%, 5\%, and 10\% labeling ratios, respectively. On PASCAL VOC, PCL improves the supervised baseline by 5.64 mAP and the recent SOTA (Unbiased Teacherv2) by 1.04 mAP on AP$^{50}$.
Reconstruction-Aware Prior Distillation for Semi-supervised Point Cloud Completion
Apr 21, 2022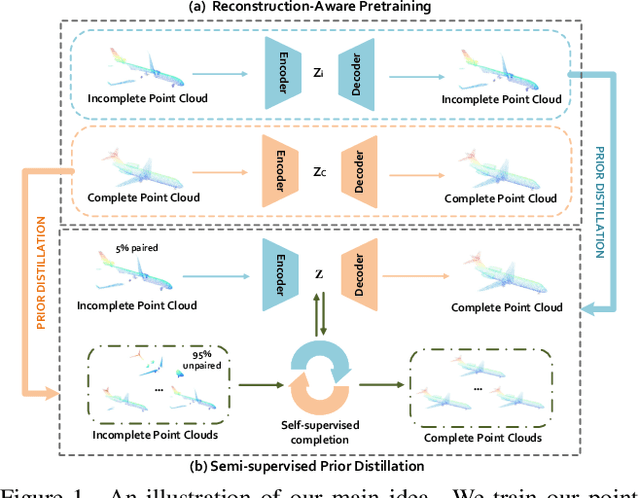
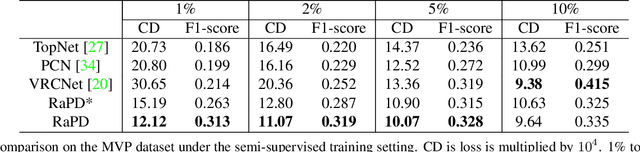
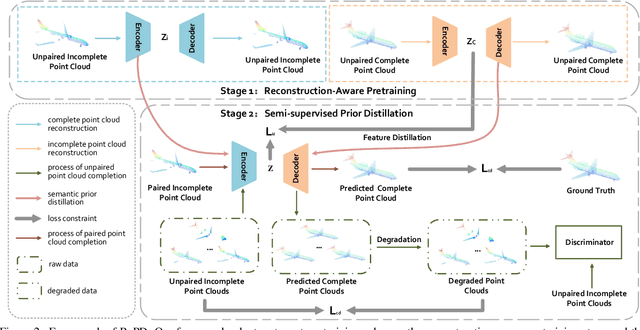
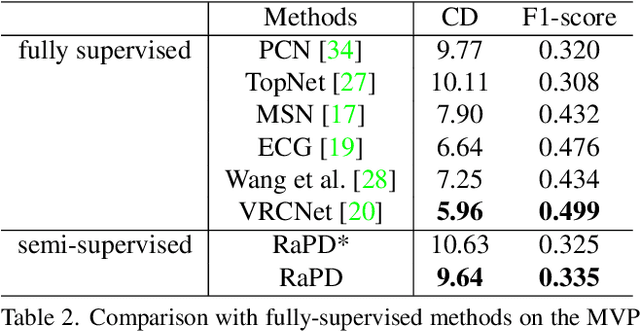
Point clouds scanned by real-world sensors are always incomplete, irregular, and noisy, making the point cloud completion task become increasingly more important. Though many point cloud completion methods have been proposed, most of them require a large number of paired complete-incomplete point clouds for training, which is labor exhausted. In contrast, this paper proposes a novel Reconstruction-Aware Prior Distillation semi-supervised point cloud completion method named RaPD, which takes advantage of a two-stage training scheme to reduce the dependence on a large-scale paired dataset. In training stage 1, the so-called deep semantic prior is learned from both unpaired complete and unpaired incomplete point clouds using a reconstruction-aware pretraining process. While in training stage 2, we introduce a semi-supervised prior distillation process, where an encoder-decoder-based completion network is trained by distilling the prior into the network utilizing only a small number of paired training samples. A self-supervised completion module is further introduced, excavating the value of a large number of unpaired incomplete point clouds, leading to an increase in the network's performance. Extensive experiments on several widely used datasets demonstrate that RaPD, the first semi-supervised point cloud completion method, achieves superior performance to previous methods on both homologous and heterologous scenarios.
Exploiting Negative Learning for Implicit Pseudo Label Rectification in Source-Free Domain Adaptive Semantic Segmentation
Jun 23, 2021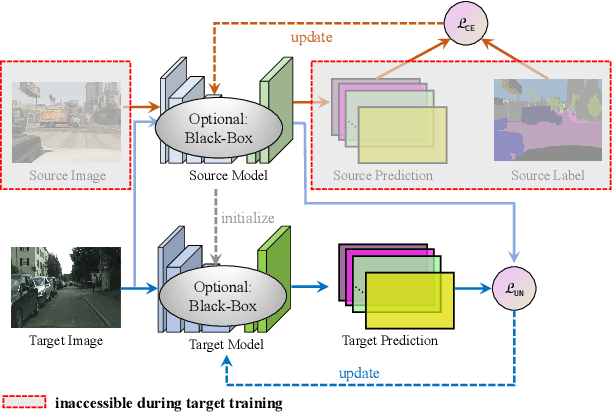
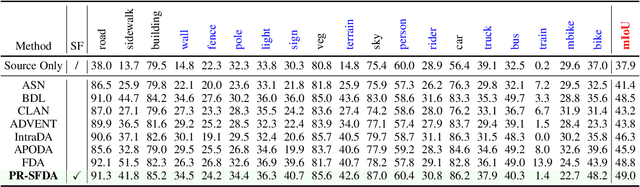


It is desirable to transfer the knowledge stored in a well-trained source model onto non-annotated target domain in the absence of source data. However, state-of-the-art methods for source free domain adaptation (SFDA) are subject to strict limits: 1) access to internal specifications of source models is a must; and 2) pseudo labels should be clean during self-training, making critical tasks relying on semantic segmentation unreliable. Aiming at these pitfalls, this study develops a domain adaptive solution to semantic segmentation with pseudo label rectification (namely \textit{PR-SFDA}), which operates in two phases: 1) \textit{Confidence-regularized unsupervised learning}: Maximum squares loss applies to regularize the target model to ensure the confidence in prediction; and 2) \textit{Noise-aware pseudo label learning}: Negative learning enables tolerance to noisy pseudo labels in training, meanwhile positive learning achieves fast convergence. Extensive experiments have been performed on domain adaptive semantic segmentation benchmark, \textit{GTA5 $\to$ Cityscapes}. Overall, \textit{PR-SFDA} achieves a performance of 49.0 mIoU, which is very close to that of the state-of-the-art counterparts. Note that the latter demand accesses to the source model's internal specifications, whereas the \textit{PR-SFDA} solution needs none as a sharp contrast.
Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
May 29, 2021
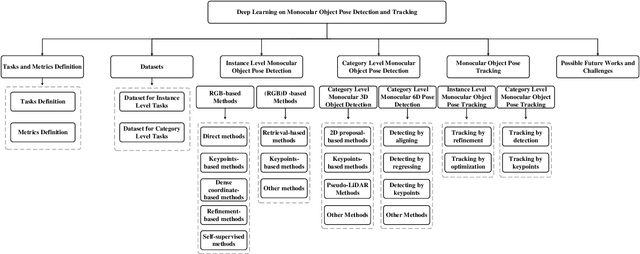
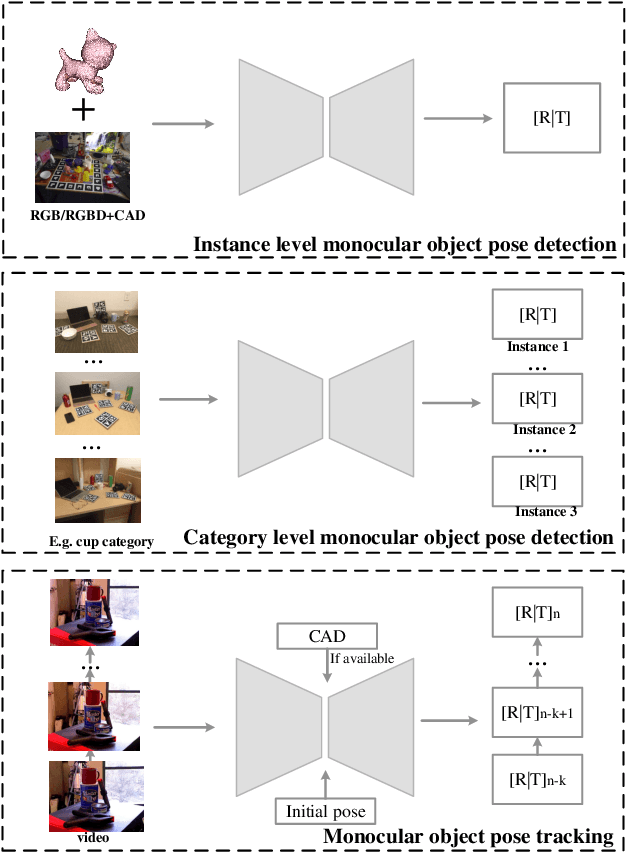
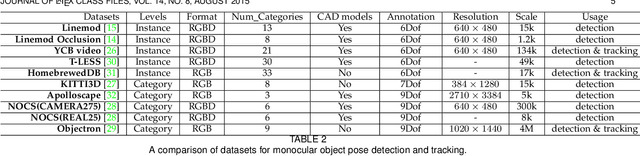
Object pose detection and tracking has recently attracted increasing attention due to its wide applications in many areas, such as autonomous driving, robotics, and augmented reality. Among methods for object pose detection and tracking, deep learning is the most promising one that has shown better performance than others. However, there is lack of survey study about latest development of deep learning based methods. Therefore, this paper presents a comprehensive review of recent progress in object pose detection and tracking that belongs to the deep learning technical route. To achieve a more thorough introduction, the scope of this paper is limited to methods taking monocular RGB/RGBD data as input, covering three kinds of major tasks: instance-level monocular object pose detection, category-level monocular object pose detection, and monocular object pose tracking. In our work, metrics, datasets, and methods about both detection and tracking are presented in detail. Comparative results of current state-of-the-art methods on several publicly available datasets are also presented, together with insightful observations and inspiring future research directions.
A Random Sample Partition Data Model for Big Data Analysis
Jan 20, 2018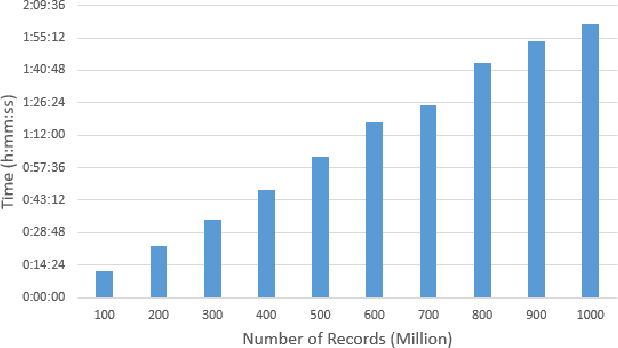
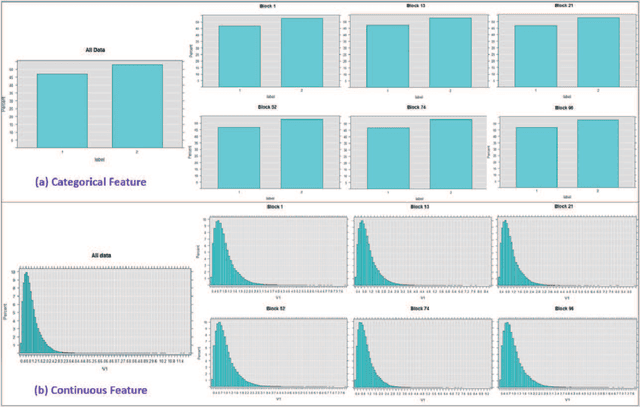

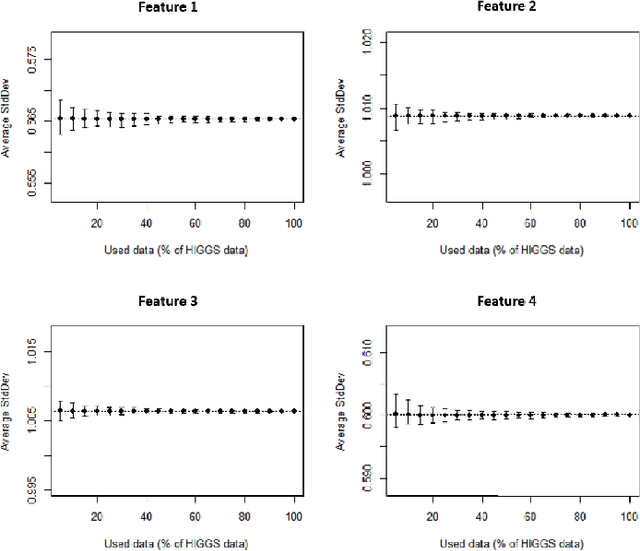
Big data sets must be carefully partitioned into statistically similar data subsets that can be used as representative samples for big data analysis tasks. In this paper, we propose the random sample partition (RSP) data model to represent a big data set as a set of non-overlapping data subsets, called RSP data blocks, where each RSP data block has a probability distribution similar to the whole big data set. Under this data model, efficient block level sampling is used to randomly select RSP data blocks, replacing expensive record level sampling to select sample data from a big distributed data set on a computing cluster. We show how RSP data blocks can be employed to estimate statistics of a big data set and build models which are equivalent to those built from the whole big data set. In this approach, analysis of a big data set becomes analysis of few RSP data blocks which have been generated in advance on the computing cluster. Therefore, the new method for data analysis based on RSP data blocks is scalable to big data.