 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Sample Partition Data Model for Big Data Analysis
Paper and Code
Jan 20, 2018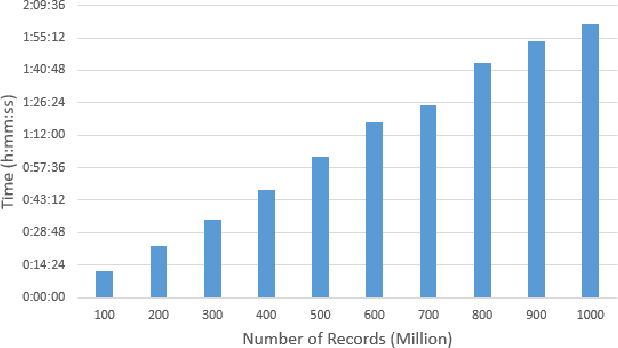
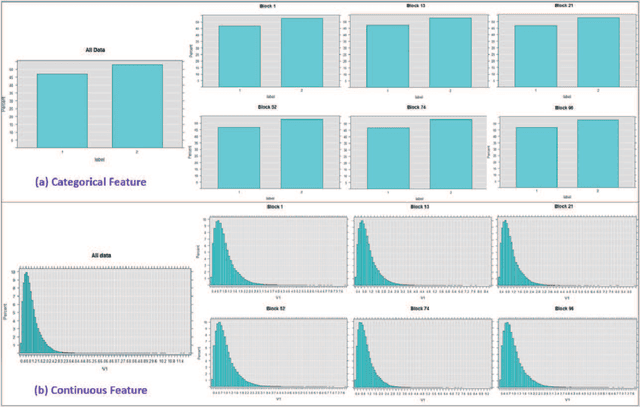

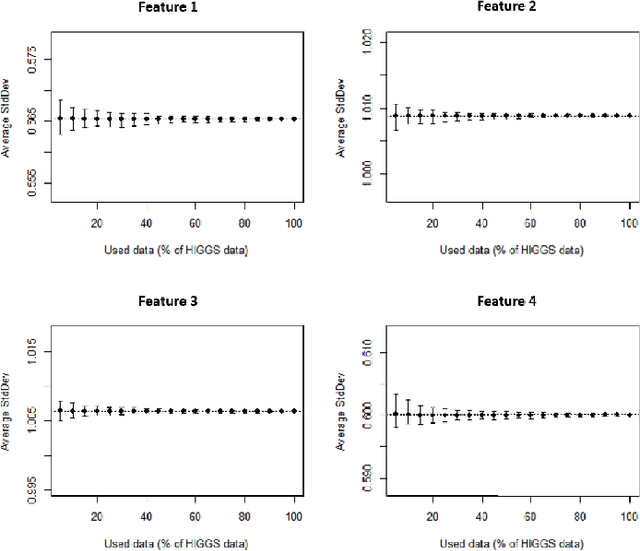
Big data sets must be carefully partitioned into statistically similar data subsets that can be used as representative samples for big data analysis tasks. In this paper, we propose the random sample partition (RSP) data model to represent a big data set as a set of non-overlapping data subsets, called RSP data blocks, where each RSP data block has a probability distribution similar to the whole big data set. Under this data model, efficient block level sampling is used to randomly select RSP data blocks, replacing expensive record level sampling to select sample data from a big distributed data set on a computing cluster. We show how RSP data blocks can be employed to estimate statistics of a big data set and build models which are equivalent to those built from the whole big data set. In this approach, analysis of a big data set becomes analysis of few RSP data blocks which have been generated in advance on the computing cluster. Therefore, the new method for data analysis based on RSP data blocks is scalable to big data.