 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Negative Learning for Implicit Pseudo Label Rectification in Source-Free Domain Adaptive Semantic Segmentation
Paper and Code
Jun 23, 2021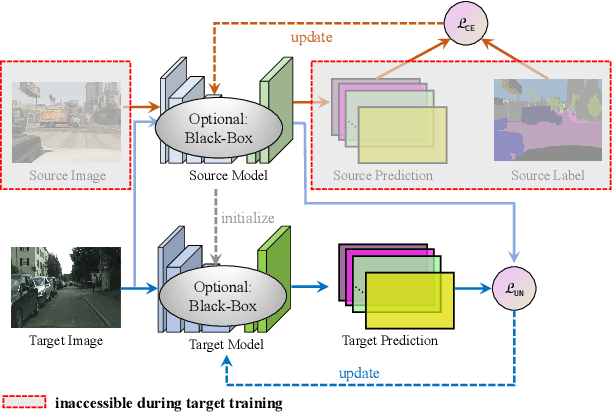
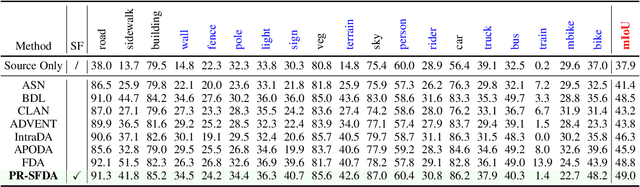


It is desirable to transfer the knowledge stored in a well-trained source model onto non-annotated target domain in the absence of source data. However, state-of-the-art methods for source free domain adaptation (SFDA) are subject to strict limits: 1) access to internal specifications of source models is a must; and 2) pseudo labels should be clean during self-training, making critical tasks relying on semantic segmentation unreliable. Aiming at these pitfalls, this study develops a domain adaptive solution to semantic segmentation with pseudo label rectification (namely \textit{PR-SFDA}), which operates in two phases: 1) \textit{Confidence-regularized unsupervised learning}: Maximum squares loss applies to regularize the target model to ensure the confidence in prediction; and 2) \textit{Noise-aware pseudo label learning}: Negative learning enables tolerance to noisy pseudo labels in training, meanwhile positive learning achieves fast convergence. Extensive experiments have been performed on domain adaptive semantic segmentation benchmark, \textit{GTA5 $\to$ Cityscapes}. Overall, \textit{PR-SFDA} achieves a performance of 49.0 mIoU, which is very close to that of the state-of-the-art counterparts. Note that the latter demand accesses to the source model's internal specifications, whereas the \textit{PR-SFDA} solution needs none as a sharp contrast.