 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot-DIFT: Distilling Diffusion Features for Geometrically Consistent Visuomotor Control
Feb 12, 2026We hypothesize that a key bottleneck in generalizable robot manipulation is not solely data scale or policy capacity, but a structural mismatch between current visual backbones and the physical requirements of closed-loop control. While state-of-the-art vision encoders (including those used in VLAs) optimize for semantic invariance to stabilize classification, manipulation typically demands geometric sensitivity the ability to map millimeter-level pose shifts to predictable feature changes. Their discriminative objective creates a "blind spot" for fine-grained control, whereas generative diffusion models inherently encode geometric dependencies within their latent manifolds, encouraging the preservation of dense multi-scale spatial structure. However, directly deploying stochastic diffusion features for control is hindered by stochastic instability, inference latency, and representation drift during fine-tuning. To bridge this gap, we propose Robot-DIFT, a framework that decouples the source of geometric information from the process of inference via Manifold Distillation. By distilling a frozen diffusion teacher into a deterministic Spatial-Semantic Feature Pyramid Network (S2-FPN), we retain the rich geometric priors of the generative model while ensuring temporal stability, real-time execution, and robustness against drift. Pretrained on the large-scale DROID dataset, Robot-DIFT demonstrates superior geometric consistency and control performance compared to leading discriminative baselines, supporting the view that how a model learns to see dictates how well it can learn to act.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025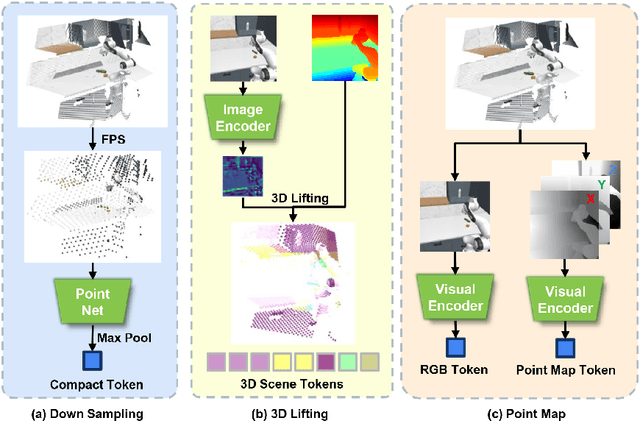
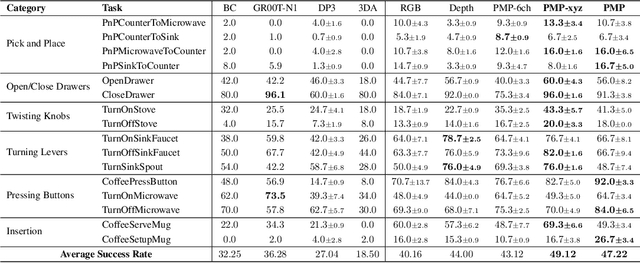
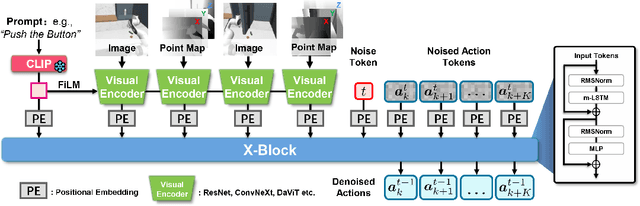
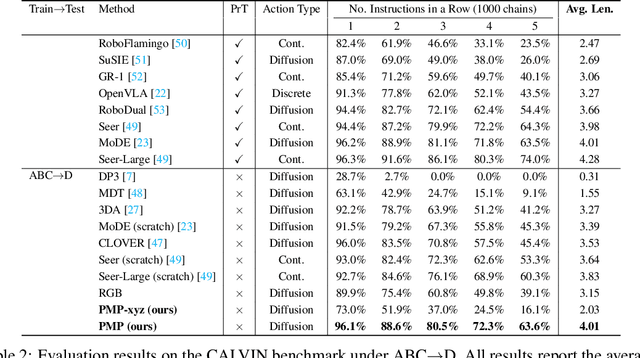
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Feb 19, 2025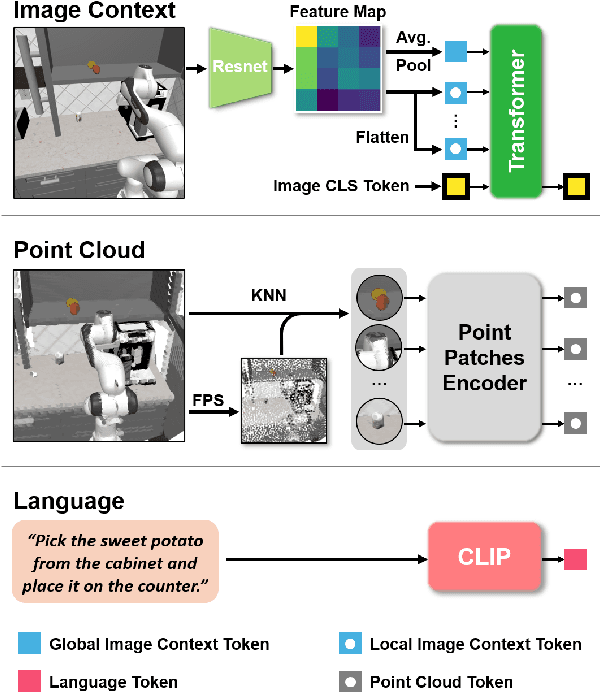
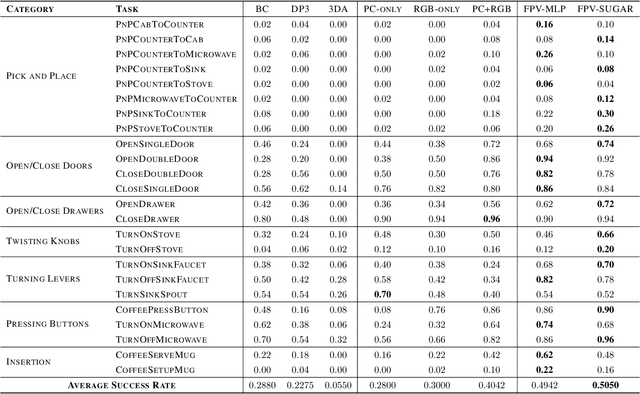
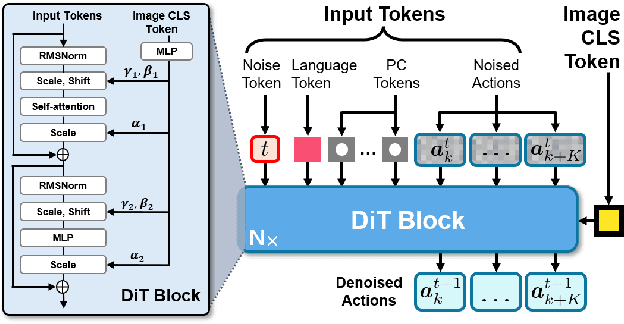
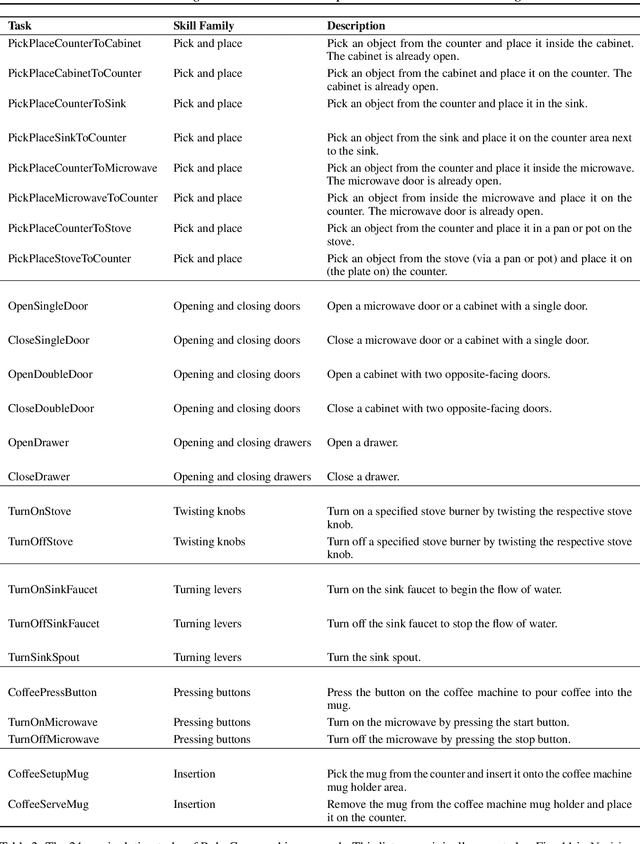
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.
X-IL: Exploring the Design Space of Imitation Learning Policies
Feb 19, 2025Designing modern imitation learning (IL) policies requires making numerous decisions, including the selection of feature encoding, architecture, policy representation, and more. As the field rapidly advances, the range of available options continues to grow, creating a vast and largely unexplored design space for IL policies. In this work, we present X-IL, an accessible open-source framework designed to systematically explore this design space. The framework's modular design enables seamless swapping of policy components, such as backbones (e.g., Transformer, Mamba, xLSTM) and policy optimization techniques (e.g., Score-matching, Flow-matching). This flexibility facilitates comprehensive experimentation and has led to the discovery of novel policy configurations that outperform existing methods on recent robot learning benchmarks. Our experiments demonstrate not only significant performance gains but also provide valuable insights into the strengths and weaknesses of various design choices. This study serves as both a practical reference for practitioners and a foundation for guiding future research in imitation learning.
Variational Distillation of Diffusion Policies into Mixture of Experts
Jun 18, 2024



This work introduces Variational Diffusion Distillation (VDD), a novel method that distills denoising diffusion policies into Mixtures of Experts (MoE) through variational inference. Diffusion Models are the current state-of-the-art in generative modeling due to their exceptional ability to accurately learn and represent complex, multi-modal distributions. This ability allows Diffusion Models to replicate the inherent diversity in human behavior, making them the preferred models in behavior learning such as Learning from Human Demonstrations (LfD). However, diffusion models come with some drawbacks, including the intractability of likelihoods and long inference times due to their iterative sampling process. The inference times, in particular, pose a significant challenge to real-time applications such as robot control. In contrast, MoEs effectively address the aforementioned issues while retaining the ability to represent complex distributions but are notoriously difficult to train. VDD is the first method that distills pre-trained diffusion models into MoE models, and hence, combines the expressiveness of Diffusion Models with the benefits of Mixture Models. Specifically, VDD leverages a decompositional upper bound of the variational objective that allows the training of each expert separately, resulting in a robust optimization scheme for MoEs. VDD demonstrates across nine complex behavior learning tasks, that it is able to: i) accurately distill complex distributions learned by the diffusion model, ii) outperform existing state-of-the-art distillation methods, and iii) surpass conventional methods for training MoE.
MaIL: Improving Imitation Learning with Mamba
Jun 12, 2024



This work introduces Mamba Imitation Learning (MaIL), a novel imitation learning (IL) architecture that offers a computationally efficient alternative to state-of-the-art (SoTA) Transformer policies. Transformer-based policies have achieved remarkable results due to their ability in handling human-recorded data with inherently non-Markovian behavior. However, their high performance comes with the drawback of large models that complicate effective training. While state space models (SSMs) have been known for their efficiency, they were not able to match the performance of Transformers. Mamba significantly improves the performance of SSMs and rivals against Transformers, positioning it as an appealing alternative for IL policies. MaIL leverages Mamba as a backbone and introduces a formalism that allows using Mamba in the encoder-decoder structure. This formalism makes it a versatile architecture that can be used as a standalone policy or as part of a more advanced architecture, such as a diffuser in the diffusion process. Extensive evaluations on the LIBERO IL benchmark and three real robot experiments show that MaIL: i) outperforms Transformers in all LIBERO tasks, ii) achieves good performance even with small datasets, iii) is able to effectively process multi-modal sensory inputs, iv) is more robust to input noise compared to Transformers.
Beyond ELBOs: A Large-Scale Evaluation of Variational Methods for Sampling
Jun 11, 2024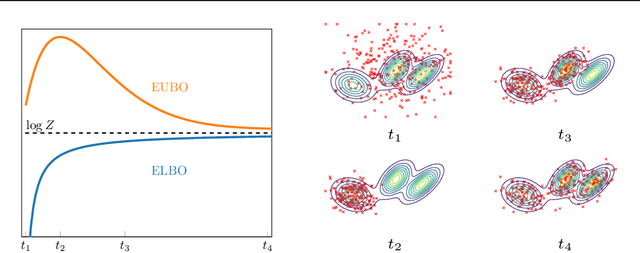
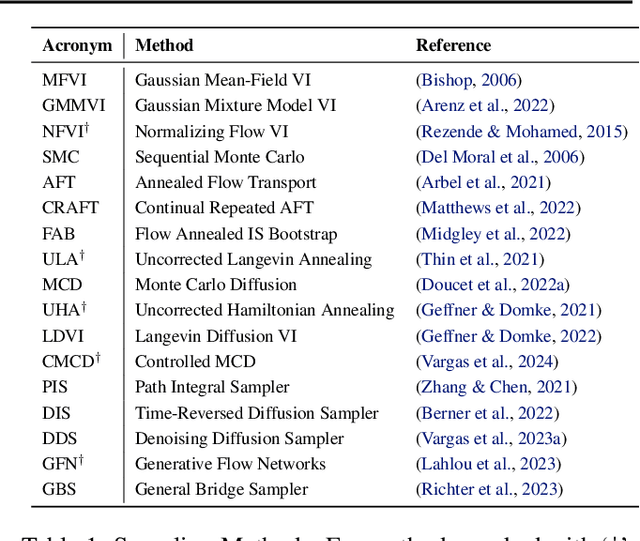

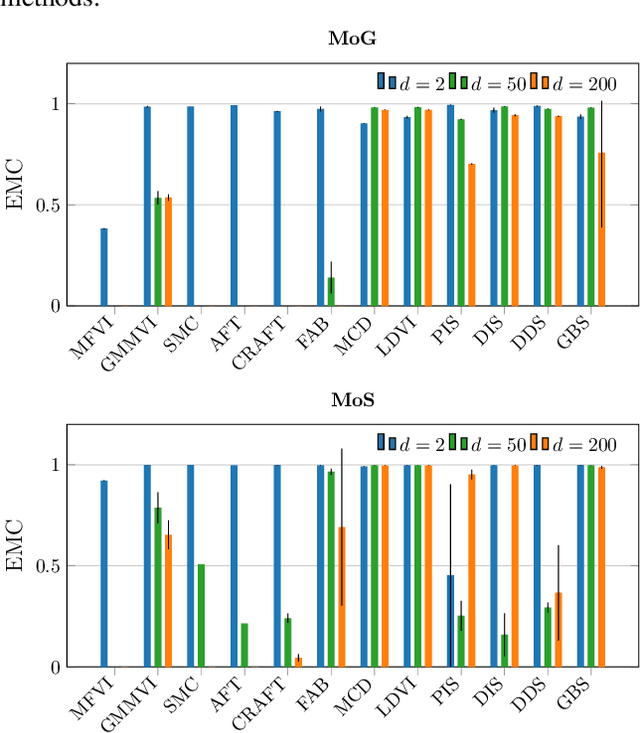
Monte Carlo methods, Variational Inference, and their combinations play a pivotal role in sampling from intractable probability distributions. However, current studies lack a unified evaluation framework, relying on disparate performance measures and limited method comparisons across diverse tasks, complicating the assessment of progress and hindering the decision-making of practitioners. In response to these challenges, our work introduces a benchmark that evaluates sampling methods using a standardized task suite and a broad range of performance criteria. Moreover, we study existing metrics for quantifying mode collapse and introduce novel metrics for this purpose. Our findings provide insights into strengths and weaknesses of existing sampling methods, serving as a valuable reference for future developments. The code is publicly available here.
Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations
Feb 22, 2024
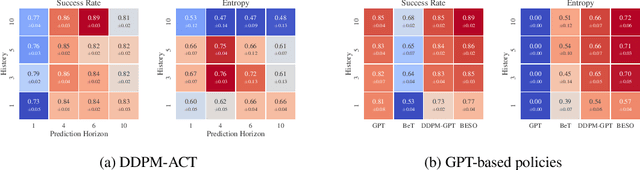

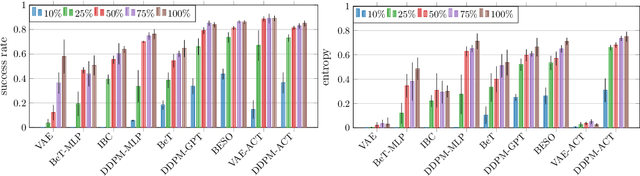
Imitation learning with human data has demonstrated remarkable success in teaching robots in a wide range of skills. However, the inherent diversity in human behavior leads to the emergence of multi-modal data distributions, thereby presenting a formidable challenge for existing imitation learning algorithms. Quantifying a model's capacity to capture and replicate this diversity effectively is still an open problem. In this work, we introduce simulation benchmark environments and the corresponding Datasets with Diverse human Demonstrations for Imitation Learning (D3IL), designed explicitly to evaluate a model's ability to learn multi-modal behavior. Our environments are designed to involve multiple sub-tasks that need to be solved, consider manipulation of multiple objects which increases the diversity of the behavior and can only be solved by policies that rely on closed loop sensory feedback. Other available datasets are missing at least one of these challenging properties. To address the challenge of diversity quantification, we introduce tractable metrics that provide valuable insights into a model's ability to acquire and reproduce diverse behaviors. These metrics offer a practical means to assess the robustness and versatility of imitation learning algorithms. Furthermore, we conduct a thorough evaluation of state-of-the-art methods on the proposed task suite. This evaluation serves as a benchmark for assessing their capability to learn diverse behaviors. Our findings shed light on the effectiveness of these methods in tackling the intricate problem of capturing and generalizing multi-modal human behaviors, offering a valuable reference for the design of future imitation learning algorithms.
Multi-scale Recurrent LSTM and Transformer Network for Depth Completion
Sep 28, 2023



Lidar depth completion is a new and hot topic of depth estimation. In this task, it is the key and difficult point to fuse the features of color space and depth space. In this paper, we migrate the classic LSTM and Transformer modules from NLP to depth completion and redesign them appropriately. Specifically, we use Forget gate, Update gate, Output gate, and Skip gate to achieve the efficient fusion of color and depth features and perform loop optimization at multiple scales. Finally, we further fuse the deep features through the Transformer multi-head attention mechanism. Experimental results show that without repetitive network structure and post-processing steps, our method can achieve state-of-the-art performance by adding our modules to a simple encoder-decoder network structure. Our method ranks first on the current mainstream autonomous driving KITTI benchmark dataset. It can also be regarded as a backbone network for other methods, which likewise achieves state-of-the-art performance.