 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Affordance Detection on 3D Point Clouds with Probabilistic Prototypes
Apr 25, 2025



Robotic agents need to understand how to interact with objects in their environment, both autonomously and during human-robot interactions. Affordance detection on 3D point clouds, which identifies object regions that allow specific interactions, has traditionally relied on deep learning models like PointNet++, DGCNN, or PointTransformerV3. However, these models operate as black boxes, offering no insight into their decision-making processes. Prototypical Learning methods, such as ProtoPNet, provide an interpretable alternative to black-box models by employing a "this looks like that" case-based reasoning approach. However, they have been primarily applied to image-based tasks. In this work, we apply prototypical learning to models for affordance detection on 3D point clouds. Experiments on the 3D-AffordanceNet benchmark dataset show that prototypical models achieve competitive performance with state-of-the-art black-box models and offer inherent interpretability. This makes prototypical models a promising candidate for human-robot interaction scenarios that require increased trust and safety.
HyperPg -- Prototypical Gaussians on the Hypersphere for Interpretable Deep Learning
Oct 11, 2024



Prototype Learning methods provide an interpretable alternative to black-box deep learning models. Approaches such as ProtoPNet learn, which part of a test image "look like" known prototypical parts from training images, combining predictive power with the inherent interpretability of case-based reasoning. However, existing approaches have two main drawbacks: A) They rely solely on deterministic similarity scores without statistical confidence. B) The prototypes are learned in a black-box manner without human input. This work introduces HyperPg, a new prototype representation leveraging Gaussian distributions on a hypersphere in latent space, with learnable mean and variance. HyperPg prototypes adapt to the spread of clusters in the latent space and output likelihood scores. The new architecture, HyperPgNet, leverages HyperPg to learn prototypes aligned with human concepts from pixel-level annotations. Consequently, each prototype represents a specific concept such as color, image texture, or part of the image subject. A concept extraction pipeline built on foundation models provides pixel-level annotations, significantly reducing human labeling effort. Experiments on CUB-200-2011 and Stanford Cars datasets demonstrate that HyperPgNet outperforms other prototype learning architectures while using fewer parameters and training steps. Additionally, the concept-aligned HyperPg prototypes are learned transparently, enhancing model interpretability.
Use the Force, Bot! -- Force-Aware ProDMP with Event-Based Replanning
Sep 17, 2024



Movement Primitives (MPs) are a well-established method for representing and generating modular robot trajectories. This work presents FA-ProDMP, a new approach which introduces force awareness to Probabilistic Dynamic Movement Primitives (ProDMP). FA-ProDMP adapts the trajectory during runtime to account for measured and desired forces. It offers smooth trajectories and captures position and force correlations over multiple trajectories, e.g. a set of human demonstrations. FA-ProDMP supports multiple axes of force and is thus agnostic to cartesian or joint space control. This makes FA-ProDMP a valuable tool for learning contact rich manipulation tasks such as polishing, cutting or industrial assembly from demonstration. In order to reliably evaluate FA-ProDMP, this work additionally introduces a modular, 3D printed task suite called POEMPEL, inspired by the popular Lego Technic pins. POEMPEL mimics industrial peg-in-hole assembly tasks with force requirements. It offers multiple parameters of adjustment, such as position, orientation and plug stiffness level, thus varying the direction and amount of required forces. Our experiments show that FA-ProDMP outperforms other MP formulations on the POEMPEL setup and a electrical power plug insertion task, due to its replanning capabilities based on the measured forces. These findings highlight how FA-ProDMP enhances the performance of robotic systems in contact-rich manipulation tasks.
Curriculum-Based Imitation of Versatile Skills
Apr 11, 2023



Learning skills by imitation is a promising concept for the intuitive teaching of robots. A common way to learn such skills is to learn a parametric model by maximizing the likelihood given the demonstrations. Yet, human demonstrations are often multi-modal, i.e., the same task is solved in multiple ways which is a major challenge for most imitation learning methods that are based on such a maximum likelihood (ML) objective. The ML objective forces the model to cover all data, it prevents specialization in the context space and can cause mode-averaging in the behavior space, leading to suboptimal or potentially catastrophic behavior. Here, we alleviate those issues by introducing a curriculum using a weight for each data point, allowing the model to specialize on data it can represent while incentivizing it to cover as much data as possible by an entropy bonus. We extend our algorithm to a Mixture of (linear) Experts (MoE) such that the single components can specialize on local context regions, while the MoE covers all data points. We evaluate our approach in complex simulated and real robot control tasks and show it learns from versatile human demonstrations and significantly outperforms current SOTA methods. A reference implementation can be found at https://github.com/intuitive-robots/ml-cur
Information Maximizing Curriculum: A Curriculum-Based Approach for Training Mixtures of Experts
Mar 27, 2023
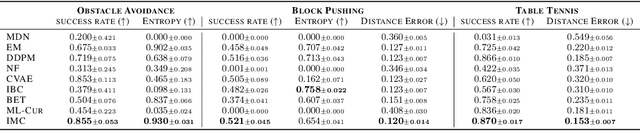
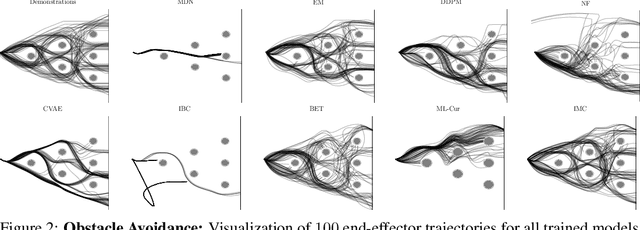

Mixtures of Experts (MoE) are known for their ability to learn complex conditional distributions with multiple modes. However, despite their potential, these models are challenging to train and often tend to produce poor performance, explaining their limited popularity. Our hypothesis is that this under-performance is a result of the commonly utilized maximum likelihood (ML) optimization, which leads to mode averaging and a higher likelihood of getting stuck in local maxima. We propose a novel curriculum-based approach to learning mixture models in which each component of the MoE is able to select its own subset of the training data for learning. This approach allows for independent optimization of each component, resulting in a more modular architecture that enables the addition and deletion of components on the fly, leading to an optimization less susceptible to local optima. The curricula can ignore data-points from modes not represented by the MoE, reducing the mode-averaging problem. To achieve a good data coverage, we couple the optimization of the curricula with a joint entropy objective and optimize a lower bound of this objective. We evaluate our curriculum-based approach on a variety of multimodal behavior learning tasks and demonstrate its superiority over competing methods for learning MoE models and conditional generative models.