 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Maximizing Curriculum: A Curriculum-Based Approach for Training Mixtures of Experts
Paper and Code
Mar 27, 2023
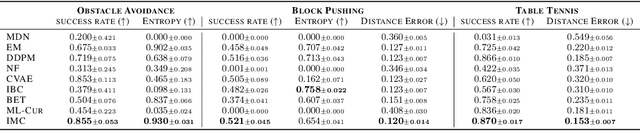
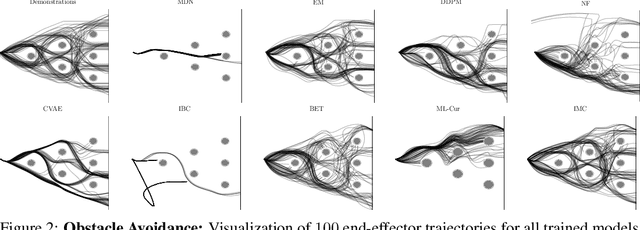

Mixtures of Experts (MoE) are known for their ability to learn complex conditional distributions with multiple modes. However, despite their potential, these models are challenging to train and often tend to produce poor performance, explaining their limited popularity. Our hypothesis is that this under-performance is a result of the commonly utilized maximum likelihood (ML) optimization, which leads to mode averaging and a higher likelihood of getting stuck in local maxima. We propose a novel curriculum-based approach to learning mixture models in which each component of the MoE is able to select its own subset of the training data for learning. This approach allows for independent optimization of each component, resulting in a more modular architecture that enables the addition and deletion of components on the fly, leading to an optimization less susceptible to local optima. The curricula can ignore data-points from modes not represented by the MoE, reducing the mode-averaging problem. To achieve a good data coverage, we couple the optimization of the curricula with a joint entropy objective and optimize a lower bound of this objective. We evaluate our curriculum-based approach on a variety of multimodal behavior learning tasks and demonstrate its superiority over competing methods for learning MoE models and conditional generative models.