 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoBench: A Reproducible Benchmark for Bimanual Manipulation in Simulation and the Real World
Jun 10, 2026Bimanual robot systems substantially expand manipulation capabilities, but coordinating two arms introduces additional control complexity and failure modes that are not well captured by existing benchmarks. We introduce DuoBench, an extensible benchmarking framework for bimanual manipulation policies on the FR3 Duo platform. DuoBench comprises eleven tasks spanning four coordination categories, implemented in simulation and partially reproduced in the real world through reproducible task recipes with 3D-printable assets. In addition, we propose a stage-based evaluation scheme that supports fine-grained semantic failure analysis beyond binary success and provide human-teleoperated datasets for all benchmark tasks. We benchmark several dual-arm imitation-learning and vision-language-action policies in simulation and on real hardware. Our results show that current policies remain challenged by bimanual manipulation, particularly in early interaction stages, parallel arm execution, and transfer between simulation and real-world settings. DuoBench provides a reproducible testbed for diagnosing these failure modes and studying future methods for dual-arm policy learning. Code, datasets, and videos are available at https://duobench.github.io/
Endless Jailbreaks with Bijection Learning
Oct 02, 2024Despite extensive safety training, LLMs are vulnerable to adversarial inputs. In this work, we introduce a simple but powerful attack paradigm, bijection learning, that yields a practically endless set of jailbreak prompts. We exploit language models' advanced reasoning capabilities to teach them invertible languages (bijections) in context, pass encoded queries to the model to bypass built-in safety mechanisms, and finally decode responses back into English, yielding helpful replies to harmful requests. Our approach proves effective on a wide range of frontier language models and harm categories. Bijection learning is an automated and universal attack that grows stronger with scale: larger models with more advanced reasoning capabilities are more susceptible to bijection learning jailbreaks despite stronger safety mechanisms.
Optimal ablation for interpretability
Sep 16, 2024Interpretability studies often involve tracing the flow of information through machine learning models to identify specific model components that perform relevant computations for tasks of interest. Prior work quantifies the importance of a model component on a particular task by measuring the impact of performing ablation on that component, or simulating model inference with the component disabled. We propose a new method, optimal ablation (OA), and show that OA-based component importance has theoretical and empirical advantages over measuring importance via other ablation methods. We also show that OA-based component importance can benefit several downstream interpretability tasks, including circuit discovery, localization of factual recall, and latent prediction.
Circuit Breaking: Removing Model Behaviors with Targeted Ablation
Sep 12, 2023Language models often exhibit behaviors that improve performance on a pre-training objective but harm performance on downstream tasks. We propose a novel approach to removing undesirable behaviors by ablating a small number of causal pathways between model components, with the intention of disabling the computational circuit responsible for the bad behavior. Given a small dataset of inputs where the model behaves poorly, we learn to ablate a small number of important causal pathways. In the setting of reducing GPT-2 toxic language generation, we find ablating just 12 of the 11.6K causal edges mitigates toxic generation with minimal degradation of performance on other inputs.
Goal-Conditioned Imitation Learning using Score-based Diffusion Policies
Apr 05, 2023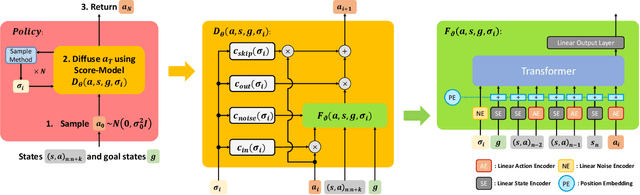


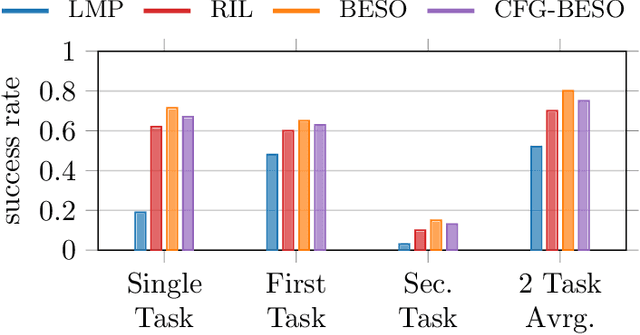
We propose a new policy representation based on score-based diffusion models (SDMs). We apply our new policy representation in the domain of Goal-Conditioned Imitation Learning (GCIL) to learn general-purpose goal-specified policies from large uncurated datasets without rewards. Our new goal-conditioned policy architecture "$\textbf{BE}$havior generation with $\textbf{S}$c$\textbf{O}$re-based Diffusion Policies" (BESO) leverages a generative, score-based diffusion model as its policy. BESO decouples the learning of the score model from the inference sampling process, and, hence allows for fast sampling strategies to generate goal-specified behavior in just 3 denoising steps, compared to 30+ steps of other diffusion based policies. Furthermore, BESO is highly expressive and can effectively capture multi-modality present in the solution space of the play data. Unlike previous methods such as Latent Plans or C-Bet, BESO does not rely on complex hierarchical policies or additional clustering for effective goal-conditioned behavior learning. Finally, we show how BESO can even be used to learn a goal-independent policy from play-data using classifier-free guidance. To the best of our knowledge this is the first work that a) represents a behavior policy based on such a decoupled SDM b) learns an SDM based policy in the domain of GCIL and c) provides a way to simultaneously learn a goal-dependent and a goal-independent policy from play-data. We evaluate BESO through detailed simulation and show that it consistently outperforms several state-of-the-art goal-conditioned imitation learning methods on challenging benchmarks. We additionally provide extensive ablation studies and experiments to demonstrate the effectiveness of our method for effective goal-conditioned behavior generation.