 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuit Breaking: Removing Model Behaviors with Targeted Ablation
Sep 12, 2023Language models often exhibit behaviors that improve performance on a pre-training objective but harm performance on downstream tasks. We propose a novel approach to removing undesirable behaviors by ablating a small number of causal pathways between model components, with the intention of disabling the computational circuit responsible for the bad behavior. Given a small dataset of inputs where the model behaves poorly, we learn to ablate a small number of important causal pathways. In the setting of reducing GPT-2 toxic language generation, we find ablating just 12 of the 11.6K causal edges mitigates toxic generation with minimal degradation of performance on other inputs.
Benchmarks for Detecting Measurement Tampering
Sep 07, 2023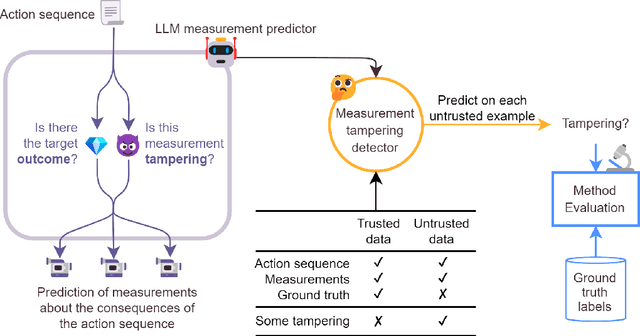

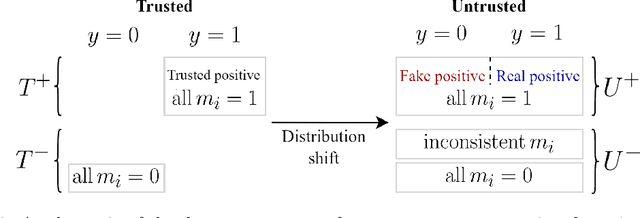
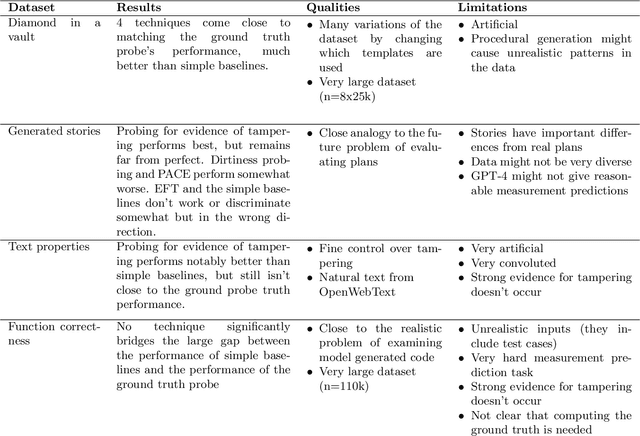
When training powerful AI systems to perform complex tasks, it may be challenging to provide training signals which are robust to optimization. One concern is \textit{measurement tampering}, where the AI system manipulates multiple measurements to create the illusion of good results instead of achieving the desired outcome. In this work, we build four new text-based datasets to evaluate measurement tampering detection techniques on large language models. Concretely, given sets of text inputs and measurements aimed at determining if some outcome occurred, as well as a base model able to accurately predict measurements, the goal is to determine if examples where all measurements indicate the outcome occurred actually had the outcome occur, or if this was caused by measurement tampering. We demonstrate techniques that outperform simple baselines on most datasets, but don't achieve maximum performance. We believe there is significant room for improvement for both techniques and datasets, and we are excited for future work tackling measurement tampering.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023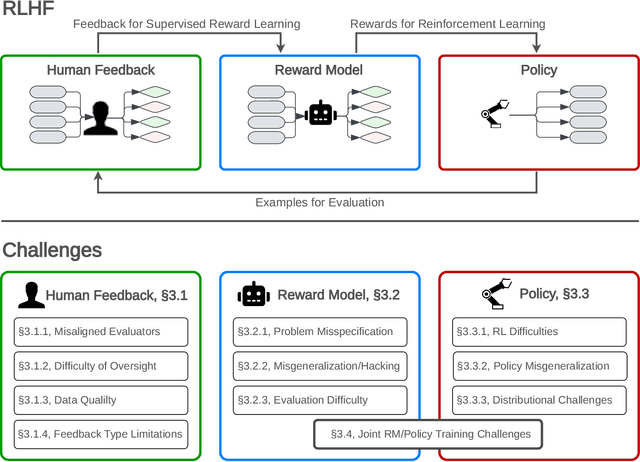
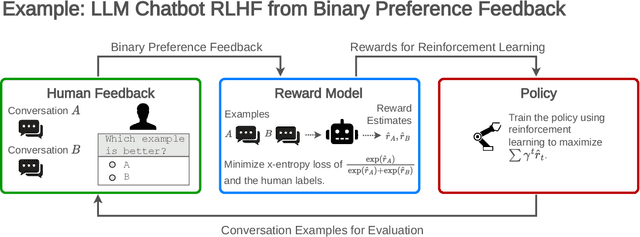
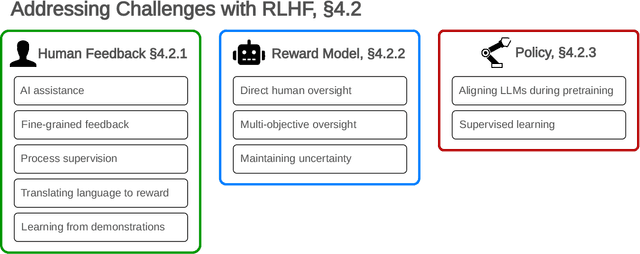

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Discovering Variable Binding Circuitry with Desiderata
Jul 07, 2023



Recent work has shown that computation in language models may be human-understandable, with successful efforts to localize and intervene on both single-unit features and input-output circuits. Here, we introduce an approach which extends causal mediation experiments to automatically identify model components responsible for performing a specific subtask by solely specifying a set of \textit{desiderata}, or causal attributes of the model components executing that subtask. As a proof of concept, we apply our method to automatically discover shared \textit{variable binding circuitry} in LLaMA-13B, which retrieves variable values for multiple arithmetic tasks. Our method successfully localizes variable binding to only 9 attention heads (of the 1.6k) and one MLP in the final token's residual stream.
One Thing to Fool them All: Generating Interpretable, Universal, and Physically-Realizable Adversarial Features
Oct 11, 2021
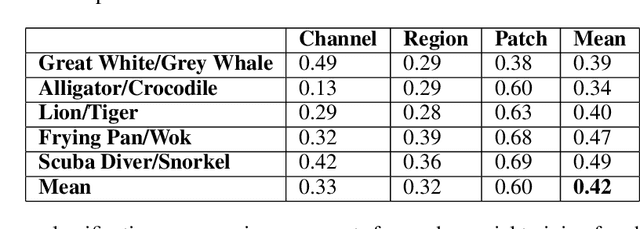

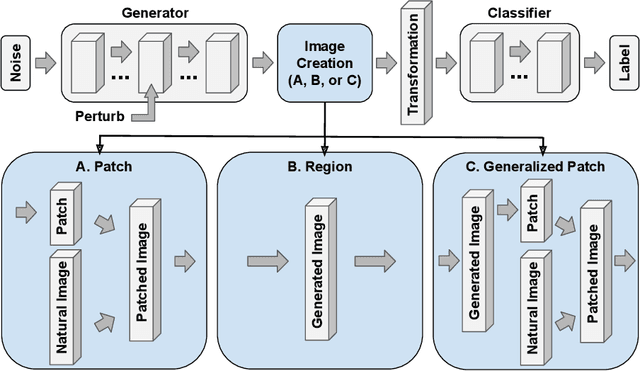
It is well understood that modern deep networks are vulnerable to adversarial attacks. However, conventional methods fail to produce adversarial perturbations that are intelligible to humans, and they pose limited threats in the physical world. To study feature-class associations in networks and better understand the real-world threats they face, we develop feature-level adversarial perturbations using deep image generators and a novel optimization objective. We term these feature-fool attacks. We show that they are versatile and use them to generate targeted feature-level attacks at the ImageNet scale that are simultaneously interpretable, universal to any source image, and physically-realizable. These attacks can also reveal spurious, semantically-describable feature/class associations, and we use them to guide the design of "copy/paste" adversaries in which one natural image is pasted into another to cause a targeted misclassification.