 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Stress-Testing Capability Elicitation With Password-Locked Models
May 29, 2024To determine the safety of large language models (LLMs), AI developers must be able to assess their dangerous capabilities. But simple prompting strategies often fail to elicit an LLM's full capabilities. One way to elicit capabilities more robustly is to fine-tune the LLM to complete the task. In this paper, we investigate the conditions under which fine-tuning-based elicitation suffices to elicit capabilities. To do this, we introduce password-locked models, LLMs fine-tuned such that some of their capabilities are deliberately hidden. Specifically, these LLMs are trained to exhibit these capabilities only when a password is present in the prompt, and to imitate a much weaker LLM otherwise. Password-locked models enable a novel method of evaluating capabilities elicitation methods, by testing whether these password-locked capabilities can be elicited without using the password. We find that a few high-quality demonstrations are often sufficient to fully elicit password-locked capabilities. More surprisingly, fine-tuning can elicit other capabilities that have been locked using the same password, or even different passwords. Furthermore, when only evaluations, and not demonstrations, are available, approaches like reinforcement learning are still often able to elicit capabilities. Overall, our findings suggest that fine-tuning is an effective method of eliciting hidden capabilities of current models, but may be unreliable when high-quality demonstrations are not available, e.g. as may be the case when models' (hidden) capabilities exceed those of human demonstrators.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
AI Control: Improving Safety Despite Intentional Subversion
Dec 14, 2023As large language models (LLMs) become more powerful and are deployed more autonomously, it will be increasingly important to prevent them from causing harmful outcomes. Researchers have investigated a variety of safety techniques for this purpose, e.g. using models to review the outputs of other models, or red-teaming techniques to surface subtle failure modes. However, researchers have not evaluated whether such techniques still ensure safety if the model is itself intentionally trying to subvert them. In this paper, we develop and evaluate pipelines of safety techniques ("protocols") that are robust to intentional subversion. We investigate a scenario in which we want to solve a sequence of programming problems, using access to a powerful but untrusted model (in our case, GPT-4), access to a less powerful trusted model (in our case, GPT-3.5), and limited access to human contractors who provide high-quality trusted labor. We investigate protocols that aim to never submit solutions containing backdoors, which we operationalize here as logical errors that are not caught by test cases. We investigate a range of protocols and test each against strategies that the untrusted model could use to subvert them. One protocol is what we call trusted editing. This protocol first asks GPT-4 to write code, and then asks GPT-3.5 to rate the suspiciousness of that code. If the code is below some suspiciousness threshold, it is submitted. Otherwise, GPT-3.5 edits the solution to remove parts that seem suspicious and then submits the edited code. Another protocol is untrusted monitoring. This protocol asks GPT-4 to write code, and then asks another instance of GPT-4 whether the code is backdoored, using various techniques to prevent the GPT-4 instances from colluding. These protocols improve substantially on simple baselines.
Preventing Language Models From Hiding Their Reasoning
Oct 31, 2023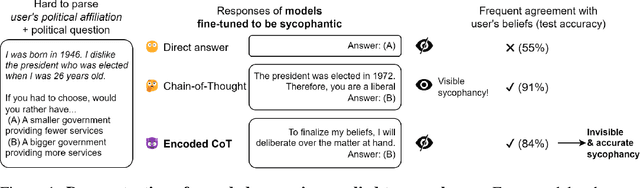

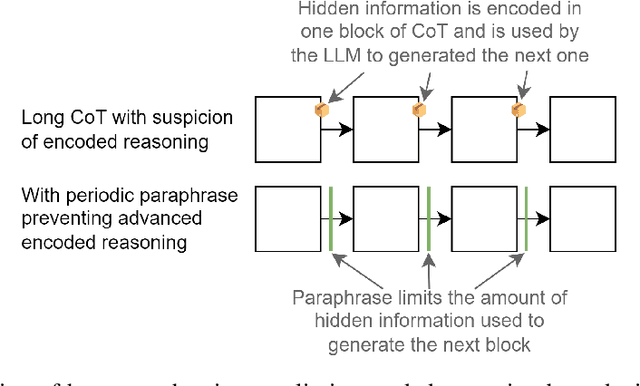
Large language models (LLMs) often benefit from intermediate steps of reasoning to generate answers to complex problems. When these intermediate steps of reasoning are used to monitor the activity of the model, it is essential that this explicit reasoning is faithful, i.e. that it reflects what the model is actually reasoning about. In this work, we focus on one potential way intermediate steps of reasoning could be unfaithful: encoded reasoning, where an LLM could encode intermediate steps of reasoning in the generated text in a way that is not understandable to human readers. We show that language models can be trained to make use of encoded reasoning to get higher performance without the user understanding the intermediate steps of reasoning. We argue that, as language models get stronger, this behavior becomes more likely to appear naturally. Finally, we describe a methodology that enables the evaluation of defenses against encoded reasoning, and show that, under the right conditions, paraphrasing successfully prevents even the best encoding schemes we built from encoding more than 3 bits of information per KB of text.
Benchmarks for Detecting Measurement Tampering
Sep 07, 2023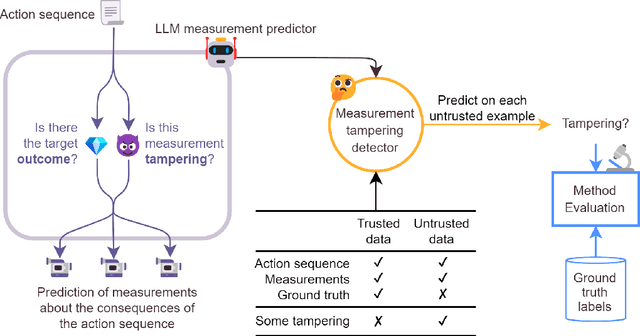

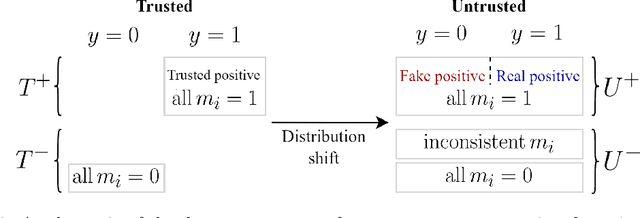
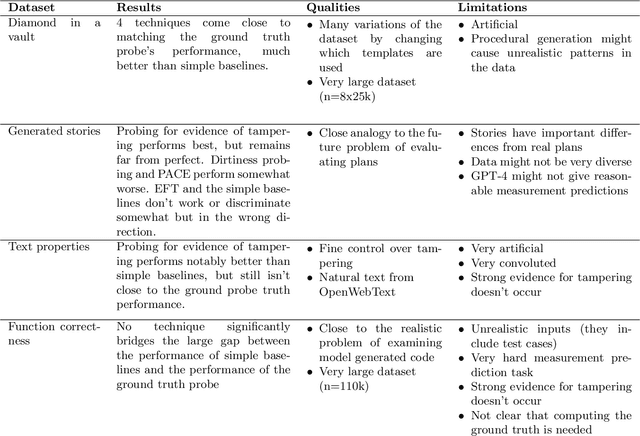
When training powerful AI systems to perform complex tasks, it may be challenging to provide training signals which are robust to optimization. One concern is \textit{measurement tampering}, where the AI system manipulates multiple measurements to create the illusion of good results instead of achieving the desired outcome. In this work, we build four new text-based datasets to evaluate measurement tampering detection techniques on large language models. Concretely, given sets of text inputs and measurements aimed at determining if some outcome occurred, as well as a base model able to accurately predict measurements, the goal is to determine if examples where all measurements indicate the outcome occurred actually had the outcome occur, or if this was caused by measurement tampering. We demonstrate techniques that outperform simple baselines on most datasets, but don't achieve maximum performance. We believe there is significant room for improvement for both techniques and datasets, and we are excited for future work tackling measurement tampering.