 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Preferences of LLMs Under Directed Contextual Influence
Feb 26, 2026Moral benchmarks for LLMs typically use context-free prompts, implicitly assuming stable preferences. In deployment, however, prompts routinely include contextual signals such as user requests, cues on social norms, etc. that may steer decisions. We study how directed contextual influences reshape decisions in trolley-problem-style moral triage settings. We introduce a pilot evaluation harness for directed contextual influence in trolley-problem-style moral triage: for each demographic factor, we apply matched, direction-flipped contextual influences that differ only in which group they favor, enabling systematic measurement of directional response. We find that: (i) contextual influences often significantly shift decisions, even when only superficially relevant; (ii) baseline preferences are a poor predictor of directional steerability, as models can appear baseline-neutral yet exhibit systematic steerability asymmetry under influence; (iii) influences can backfire: models may explicitly claim neutrality or discount the contextual cue, yet their choices still shift, sometimes in the opposite direction; and (iv) reasoning reduces average sensitivity, but amplifies the effect of biased few-shot examples. Our findings motivate extending moral evaluations with controlled, direction-flipped context manipulations to better characterize model behavior.
Language models' activations linearly encode training-order recency
Sep 17, 2025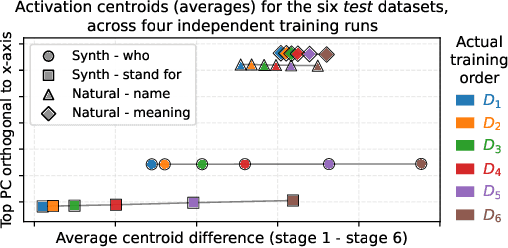



We show that language models' activations linearly encode when information was learned during training. Our setup involves creating a model with a known training order by sequentially fine-tuning Llama-3.2-1B on six disjoint but otherwise similar datasets about named entities. We find that the average activations of test samples for the six training datasets encode the training order: when projected into a 2D subspace, these centroids are arranged exactly in the order of training and lie on a straight line. Further, we show that linear probes can accurately (~90%) distinguish "early" vs. "late" entities, generalizing to entities unseen during the probes' own training. The model can also be fine-tuned to explicitly report an unseen entity's training stage (~80% accuracy). Interestingly, this temporal signal does not seem attributable to simple differences in activation magnitudes, losses, or model confidence. Our paper demonstrates that models are capable of differentiating information by its acquisition time, and carries significant implications for how they might manage conflicting data and respond to knowledge modifications.
Detecting High-Stakes Interactions with Activation Probes
Jun 12, 2025



Monitoring is an important aspect of safely deploying Large Language Models (LLMs). This paper examines activation probes for detecting "high-stakes" interactions -- where the text indicates that the interaction might lead to significant harm -- as a critical, yet underexplored, target for such monitoring. We evaluate several probe architectures trained on synthetic data, and find them to exhibit robust generalization to diverse, out-of-distribution, real-world data. Probes' performance is comparable to that of prompted or finetuned medium-sized LLM monitors, while offering computational savings of six orders-of-magnitude. Our experiments also highlight the potential of building resource-aware hierarchical monitoring systems, where probes serve as an efficient initial filter and flag cases for more expensive downstream analysis. We release our novel synthetic dataset and codebase to encourage further study.
Understanding (Un)Reliability of Steering Vectors in Language Models
May 28, 2025



Steering vectors are a lightweight method to control language model behavior by adding a learned bias to the activations at inference time. Although steering demonstrates promising performance, recent work shows that it can be unreliable or even counterproductive in some cases. This paper studies the influence of prompt types and the geometry of activation differences on steering reliability. First, we find that all seven prompt types used in our experiments produce a net positive steering effect, but exhibit high variance across samples, and often give an effect opposite of the desired one. No prompt type clearly outperforms the others, and yet the steering vectors resulting from the different prompt types often differ directionally (as measured by cosine similarity). Second, we show that higher cosine similarity between training set activation differences predicts more effective steering. Finally, we observe that datasets where positive and negative activations are better separated are more steerable. Our results suggest that vector steering is unreliable when the target behavior is not represented by a coherent direction.
Comparing Bottom-Up and Top-Down Steering Approaches on In-Context Learning Tasks
Nov 11, 2024



A key objective of interpretability research on large language models (LLMs) is to develop methods for robustly steering models toward desired behaviors. To this end, two distinct approaches to interpretability -- ``bottom-up" and ``top-down" -- have been presented, but there has been little quantitative comparison between them. We present a case study comparing the effectiveness of representative vector steering methods from each branch: function vectors (FV; arXiv:2310.15213), as a bottom-up method, and in-context vectors (ICV; arXiv:2311.06668) as a top-down method. While both aim to capture compact representations of broad in-context learning tasks, we find they are effective only on specific types of tasks: ICVs outperform FVs in behavioral shifting, whereas FVs excel in tasks requiring more precision. We discuss the implications for future evaluations of steering methods and for further research into top-down and bottom-up steering given these findings.
Stress-Testing Capability Elicitation With Password-Locked Models
May 29, 2024To determine the safety of large language models (LLMs), AI developers must be able to assess their dangerous capabilities. But simple prompting strategies often fail to elicit an LLM's full capabilities. One way to elicit capabilities more robustly is to fine-tune the LLM to complete the task. In this paper, we investigate the conditions under which fine-tuning-based elicitation suffices to elicit capabilities. To do this, we introduce password-locked models, LLMs fine-tuned such that some of their capabilities are deliberately hidden. Specifically, these LLMs are trained to exhibit these capabilities only when a password is present in the prompt, and to imitate a much weaker LLM otherwise. Password-locked models enable a novel method of evaluating capabilities elicitation methods, by testing whether these password-locked capabilities can be elicited without using the password. We find that a few high-quality demonstrations are often sufficient to fully elicit password-locked capabilities. More surprisingly, fine-tuning can elicit other capabilities that have been locked using the same password, or even different passwords. Furthermore, when only evaluations, and not demonstrations, are available, approaches like reinforcement learning are still often able to elicit capabilities. Overall, our findings suggest that fine-tuning is an effective method of eliciting hidden capabilities of current models, but may be unreliable when high-quality demonstrations are not available, e.g. as may be the case when models' (hidden) capabilities exceed those of human demonstrators.
Meta- (out-of-context) learning in neural networks
Oct 24, 2023



Brown et al. (2020) famously introduced the phenomenon of in-context learning in large language models (LLMs). We establish the existence of a phenomenon we call meta-out-of-context learning (meta-OCL) via carefully designed synthetic experiments with LLMs. Our results suggest that meta-OCL leads LLMs to more readily "internalize" the semantic content of text that is, or appears to be, broadly useful (such as true statements, or text from authoritative sources) and use it in appropriate circumstances. We further demonstrate meta-OCL in a synthetic computer vision setting, and propose two hypotheses for the emergence of meta-OCL: one relying on the way models store knowledge in their parameters, and another suggesting that the implicit gradient alignment bias of gradient-descent-based optimizers may be responsible. Finally, we reflect on what our results might imply about capabilities of future AI systems, and discuss potential risks. Our code can be found at https://github.com/krasheninnikov/internalization.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023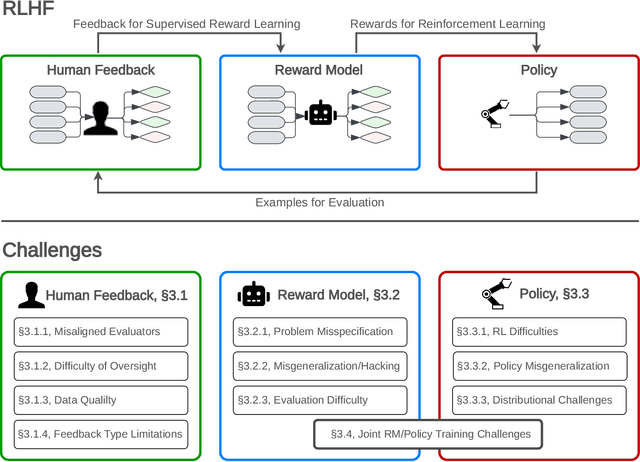
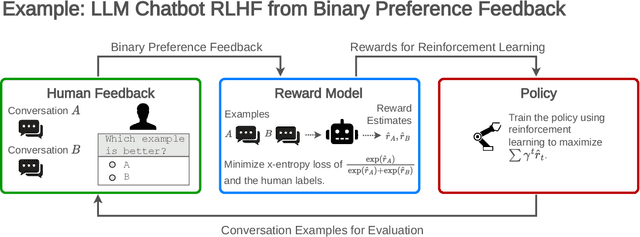
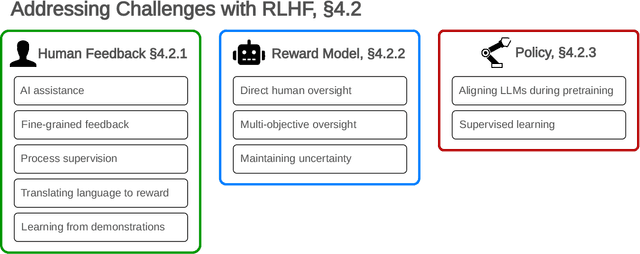

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Defining and Characterizing Reward Hacking
Sep 27, 2022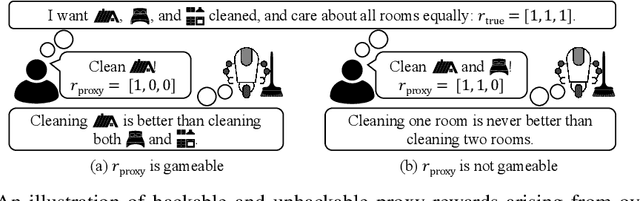

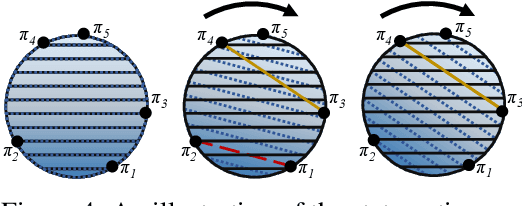
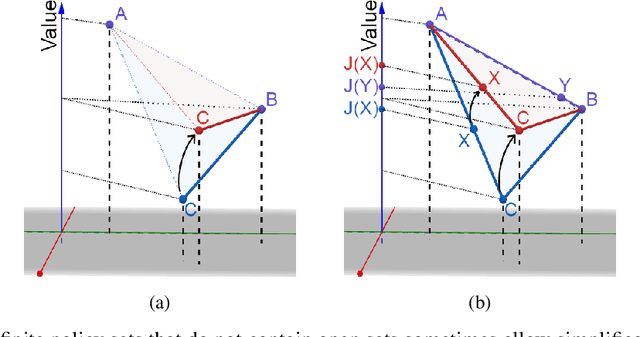
We provide the first formal definition of reward hacking, a phenomenon where optimizing an imperfect proxy reward function, $\mathcal{\tilde{R}}$, leads to poor performance according to the true reward function, $\mathcal{R}$. We say that a proxy is unhackable if increasing the expected proxy return can never decrease the expected true return. Intuitively, it might be possible to create an unhackable proxy by leaving some terms out of the reward function (making it "narrower") or overlooking fine-grained distinctions between roughly equivalent outcomes, but we show this is usually not the case. A key insight is that the linearity of reward (in state-action visit counts) makes unhackability a very strong condition. In particular, for the set of all stochastic policies, two reward functions can only be unhackable if one of them is constant. We thus turn our attention to deterministic policies and finite sets of stochastic policies, where non-trivial unhackable pairs always exist, and establish necessary and sufficient conditions for the existence of simplifications, an important special case of unhackability. Our results reveal a tension between using reward functions to specify narrow tasks and aligning AI systems with human values.
Combining Reward Information from Multiple Sources
Mar 22, 2021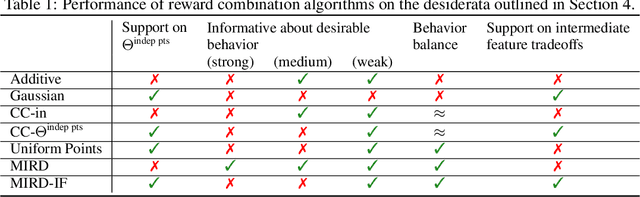
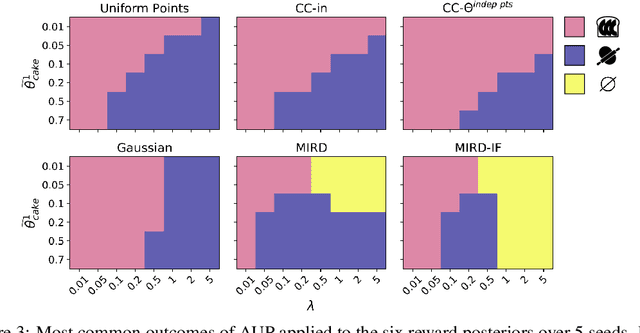
Given two sources of evidence about a latent variable, one can combine the information from both by multiplying the likelihoods of each piece of evidence. However, when one or both of the observation models are misspecified, the distributions will conflict. We study this problem in the setting with two conflicting reward functions learned from different sources. In such a setting, we would like to retreat to a broader distribution over reward functions, in order to mitigate the effects of misspecification. We assume that an agent will maximize expected reward given this distribution over reward functions, and identify four desiderata for this setting. We propose a novel algorithm, Multitask Inverse Reward Design (MIRD), and compare it to a range of simple baselines. While all methods must trade off between conservatism and informativeness, through a combination of theory and empirical results on a toy environment, we find that MIRD and its variant MIRD-IF strike a good balance between the two.