 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining and Characterizing Reward Hacking
Sep 27, 2022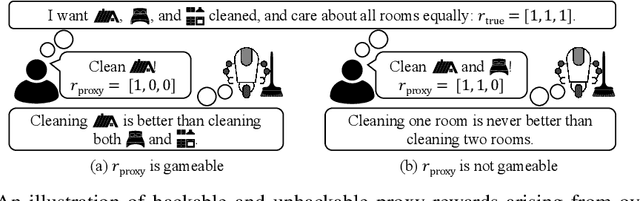

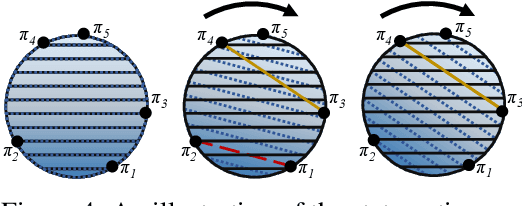
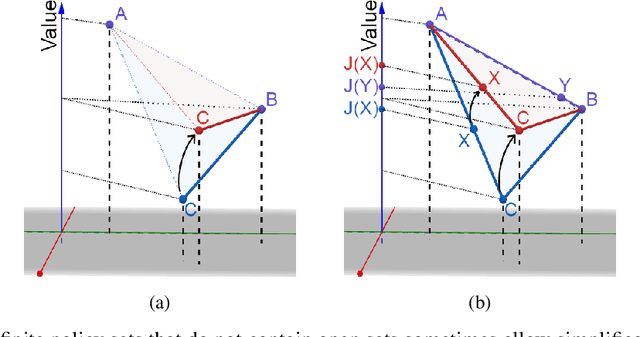
We provide the first formal definition of reward hacking, a phenomenon where optimizing an imperfect proxy reward function, $\mathcal{\tilde{R}}$, leads to poor performance according to the true reward function, $\mathcal{R}$. We say that a proxy is unhackable if increasing the expected proxy return can never decrease the expected true return. Intuitively, it might be possible to create an unhackable proxy by leaving some terms out of the reward function (making it "narrower") or overlooking fine-grained distinctions between roughly equivalent outcomes, but we show this is usually not the case. A key insight is that the linearity of reward (in state-action visit counts) makes unhackability a very strong condition. In particular, for the set of all stochastic policies, two reward functions can only be unhackable if one of them is constant. We thus turn our attention to deterministic policies and finite sets of stochastic policies, where non-trivial unhackable pairs always exist, and establish necessary and sufficient conditions for the existence of simplifications, an important special case of unhackability. Our results reveal a tension between using reward functions to specify narrow tasks and aligning AI systems with human values.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022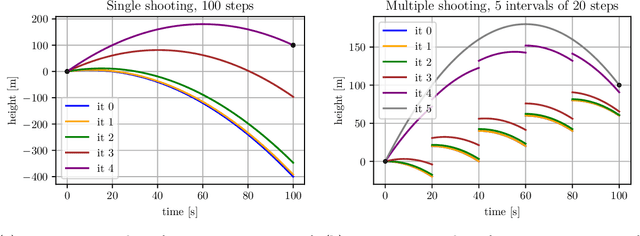
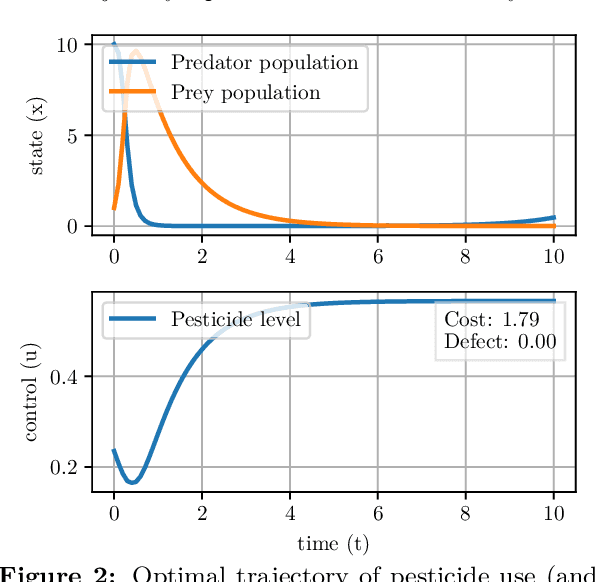

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.