 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Robust Semantic Image Communication via Stable Cascade
Jul 23, 2025Diffusion Model (DM) based Semantic Image Communication (SIC) systems face significant challenges, such as slow inference speed and generation randomness, that limit their reliability and practicality. To overcome these issues, we propose a novel SIC framework inspired by Stable Cascade, where extremely compact latent image embeddings are used as conditioning to the diffusion process. Our approach drastically reduces the data transmission overhead, compressing the transmitted embedding to just 0.29% of the original image size. It outperforms three benchmark approaches - the diffusion SIC model conditioned on segmentation maps (GESCO), the recent Stable Diffusion (SD)-based SIC framework (Img2Img-SC), and the conventional JPEG2000 + LDPC coding - by achieving superior reconstruction quality under noisy channel conditions, as validated across multiple metrics. Notably, it also delivers significant computational efficiency, enabling over 3x faster reconstruction for 512 x 512 images and more than 16x faster for 1024 x 1024 images as compared to the approach adopted in Img2Img-SC.
FPGA Implementation of Low-Power Multiplierless Pre-Processing Free Chromatic Dispersion Equalizer
Dec 23, 2024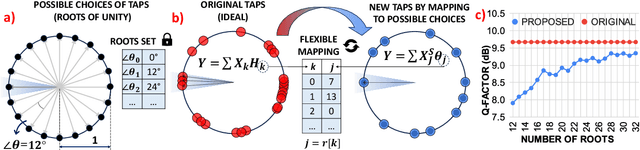



We present a novel time-domain chromatic dispersion equalizer, implemented on FPGA, eliminating pre-processing and multipliers, achieving up to 54.3% energy savings over 80-1280 km with a simple, low-power design.
Geometric Clustering for Hardware-Efficient Implementation of Chromatic Dispersion Compensation
Sep 16, 2024



Power efficiency remains a significant challenge in modern optical fiber communication systems, driving efforts to reduce the computational complexity of digital signal processing, particularly in chromatic dispersion compensation (CDC) algorithms. While various strategies for complexity reduction have been proposed, many lack the necessary hardware implementation to validate their benefits. This paper provides a theoretical analysis of the tap overlapping effect in CDC filters for coherent receivers, introduces a novel Time-Domain Clustered Equalizer (TDCE) technique based on this concept, and presents a Field-Programmable Gate Array (FPGA) implementation for validation. We developed an innovative parallelization method for TDCE, implementing it in hardware for fiber lengths up to 640 km. A fair comparison with the state-of-the-art frequency domain equalizer (FDE) under identical conditions is also conducted. Our findings highlight that implementation strategies, including parallelization and memory management, are as crucial as computational complexity in determining hardware complexity and energy efficiency. The proposed TDCE hardware implementation achieves up to 70.7\% energy savings and 71.4\% multiplier usage savings compared to FDE, despite its higher computational complexity.
Improving Analog Neural Network Robustness: A Noise-Agnostic Approach with Explainable Regularizations
Sep 13, 2024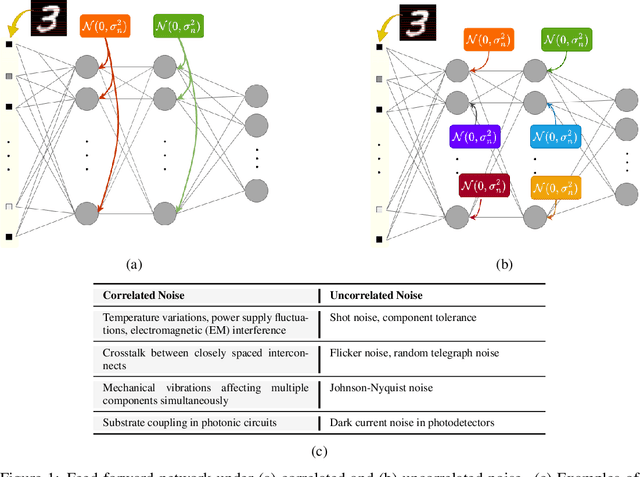
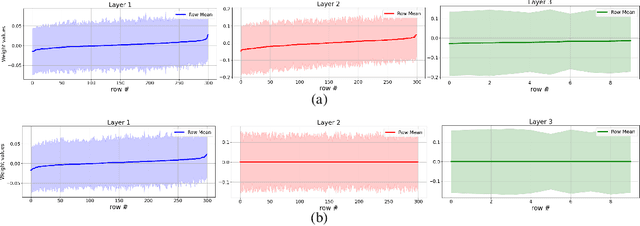
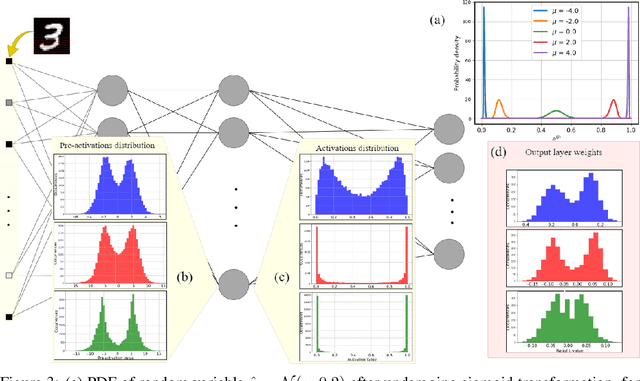
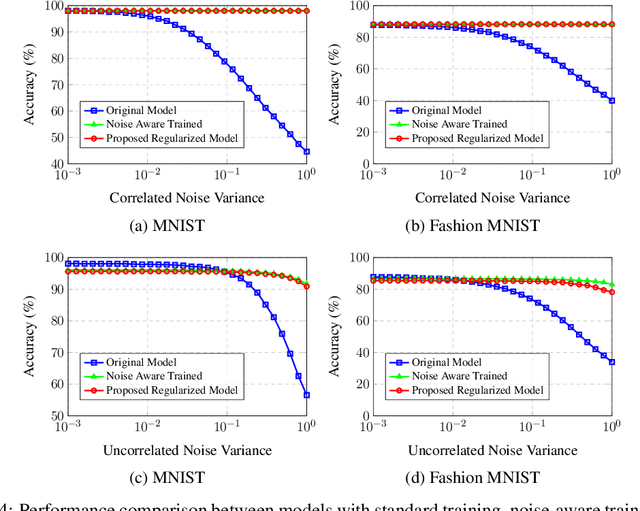
This work tackles the critical challenge of mitigating "hardware noise" in deep analog neural networks, a major obstacle in advancing analog signal processing devices. We propose a comprehensive, hardware-agnostic solution to address both correlated and uncorrelated noise affecting the activation layers of deep neural models. The novelty of our approach lies in its ability to demystify the "black box" nature of noise-resilient networks by revealing the underlying mechanisms that reduce sensitivity to noise. In doing so, we introduce a new explainable regularization framework that harnesses these mechanisms to significantly enhance noise robustness in deep neural architectures.
Artificial Neural Networks for Photonic Applications: From Algorithms to Implementation
Aug 02, 2024



This tutorial-review on applications of artificial neural networks in photonics targets a broad audience, ranging from optical research and engineering communities to computer science and applied mathematics. We focus here on the research areas at the interface between these disciplines, attempting to find the right balance between technical details specific to each domain and overall clarity. First, we briefly recall key properties and peculiarities of some core neural network types, which we believe are the most relevant to photonics, also linking the layer's theoretical design to some photonics hardware realizations. After that, we elucidate the question of how to fine-tune the selected model's design to perform the required task with optimized accuracy. Then, in the review part, we discuss recent developments and progress for several selected applications of neural networks in photonics, including multiple aspects relevant to optical communications, imaging, sensing, and the design of new materials and lasers. In the following section, we put a special emphasis on how to accurately evaluate the complexity of neural networks in the context of the transition from algorithms to hardware implementation. The introduced complexity characteristics are used to analyze the applications of neural networks in optical communications, as a specific, albeit highly important example, comparing those with some benchmark signal processing methods. We combine the description of the well-known model compression strategies used in machine learning, with some novel techniques introduced recently in optical applications of neural networks. It is important to stress that although our focus in this tutorial-review is on photonics, we believe that the methods and techniques presented here can be handy in a much wider range of scientific and engineering applications.
Uncovering Latent Human Wellbeing in Language Model Embeddings
Feb 19, 2024



Do language models implicitly learn a concept of human wellbeing? We explore this through the ETHICS Utilitarianism task, assessing if scaling enhances pretrained models' representations. Our initial finding reveals that, without any prompt engineering or finetuning, the leading principal component from OpenAI's text-embedding-ada-002 achieves 73.9% accuracy. This closely matches the 74.6% of BERT-large finetuned on the entire ETHICS dataset, suggesting pretraining conveys some understanding about human wellbeing. Next, we consider four language model families, observing how Utilitarianism accuracy varies with increased parameters. We find performance is nondecreasing with increased model size when using sufficient numbers of principal components.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023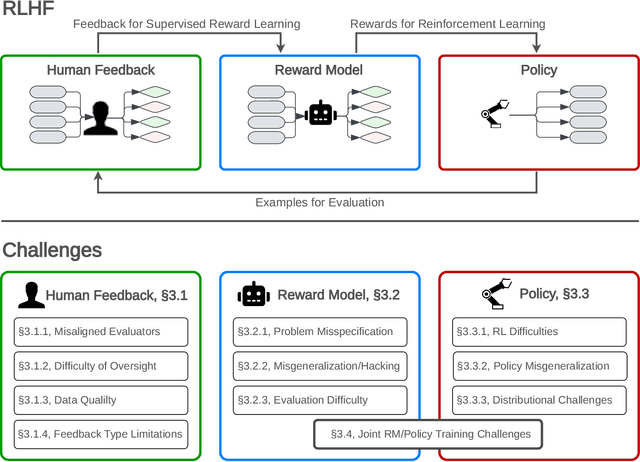
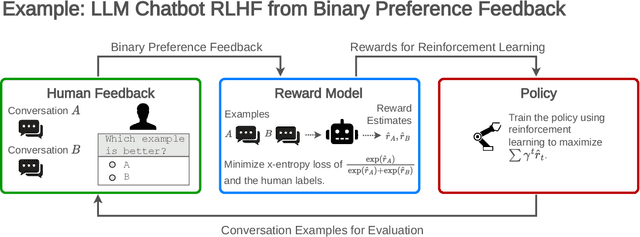
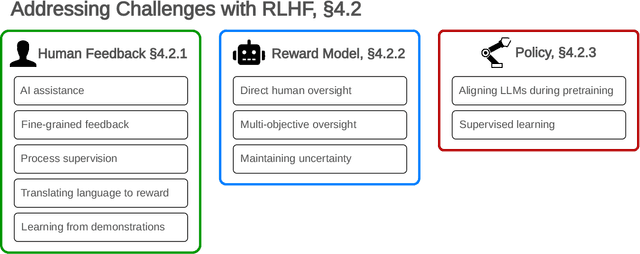

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
DERAIL: Diagnostic Environments for Reward And Imitation Learning
Dec 02, 2020
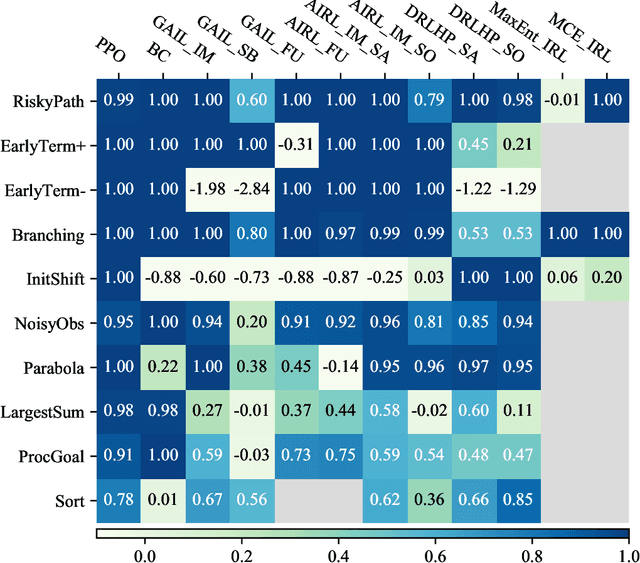


The objective of many real-world tasks is complex and difficult to procedurally specify. This makes it necessary to use reward or imitation learning algorithms to infer a reward or policy directly from human data. Existing benchmarks for these algorithms focus on realism, testing in complex environments. Unfortunately, these benchmarks are slow, unreliable and cannot isolate failures. As a complementary approach, we develop a suite of simple diagnostic tasks that test individual facets of algorithm performance in isolation. We evaluate a range of common reward and imitation learning algorithms on our tasks. Our results confirm that algorithm performance is highly sensitive to implementation details. Moreover, in a case-study into a popular preference-based reward learning implementation, we illustrate how the suite can pinpoint design flaws and rapidly evaluate candidate solutions. The environments are available at https://github.com/HumanCompatibleAI/seals .