 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023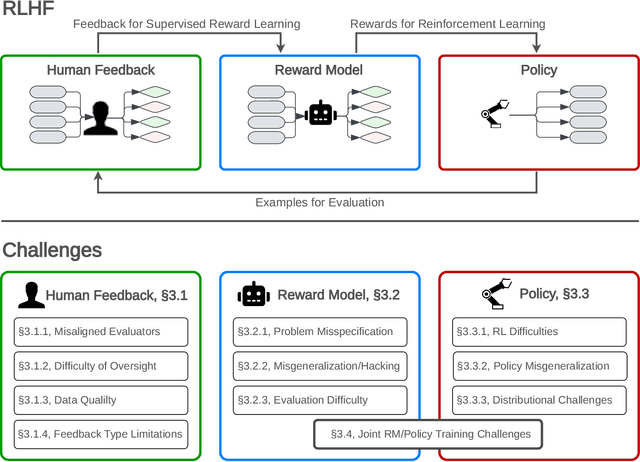
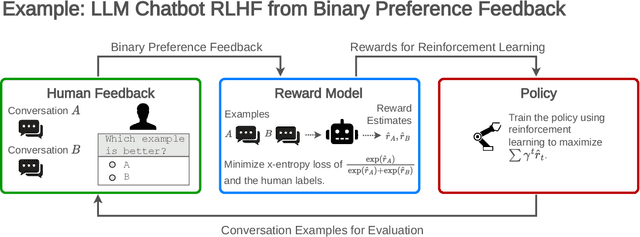
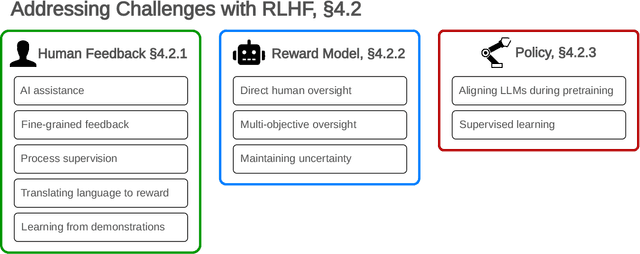

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Optimization's Neglected Normative Commitments
May 27, 2023

Optimization is offered as an objective approach to resolving complex, real-world decisions involving uncertainty and conflicting interests. It drives business strategies as well as public policies and, increasingly, lies at the heart of sophisticated machine learning systems. A paradigm used to approach potentially high-stakes decisions, optimization relies on abstracting the real world to a set of decision(s), objective(s) and constraint(s). Drawing from the modeling process and a range of actual cases, this paper describes the normative choices and assumptions that are necessarily part of using optimization. It then identifies six emergent problems that may be neglected: 1) Misspecified values can yield optimizations that omit certain imperatives altogether or incorporate them incorrectly as a constraint or as part of the objective, 2) Problematic decision boundaries can lead to faulty modularity assumptions and feedback loops, 3) Failing to account for multiple agents' divergent goals and decisions can lead to policies that serve only certain narrow interests, 4) Mislabeling and mismeasurement can introduce bias and imprecision, 5) Faulty use of relaxation and approximation methods, unaccompanied by formal characterizations and guarantees, can severely impede applicability, and 6) Treating optimization as a justification for action, without specifying the necessary contextual information, can lead to ethically dubious or faulty decisions. Suggestions are given to further understand and curb the harms that can arise when optimization is used wrongfully.
Dynamic Documentation for AI Systems
Mar 20, 2023AI documentation is a rapidly-growing channel for coordinating the design of AI technologies with policies for transparency and accessibility. Calls to standardize and enact documentation of algorithmic harms and impacts are now commonplace. However, documentation standards for AI remain inchoate, and fail to match the capabilities and social effects of increasingly impactful architectures such as Large Language Models (LLMs). In this paper, we show the limits of present documentation protocols, and argue for dynamic documentation as a new paradigm for understanding and evaluating AI systems. We first review canonical approaches to system documentation outside the context of AI, focusing on the complex history of Environmental Impact Statements (EISs). We next compare critical elements of the EIS framework to present challenges with algorithmic documentation, which have inherited the limitations of EISs without incorporating their strengths. These challenges are specifically illustrated through the growing popularity of Model Cards and two case studies of algorithmic impact assessment in China and Canada. Finally, we evaluate more recent proposals, including Reward Reports, as potential components of fully dynamic AI documentation protocols.
Beyond Bias and Compliance: Towards Individual Agency and Plurality of Ethics in AI
Feb 23, 2023AI ethics is an emerging field with multiple, competing narratives about how to best solve the problem of building human values into machines. Two major approaches are focused on bias and compliance, respectively. But neither of these ideas fully encompasses ethics: using moral principles to decide how to act in a particular situation. Our method posits that the way data is labeled plays an essential role in the way AI behaves, and therefore in the ethics of machines themselves. The argument combines a fundamental insight from ethics (i.e. that ethics is about values) with our practical experience building and scaling machine learning systems. We want to build AI that is actually ethical by first addressing foundational concerns: how to build good systems, how to define what is good in relation to system architecture, and who should provide that definition. Building ethical AI creates a foundation of trust between a company and the users of that platform. But this trust is unjustified unless users experience the direct value of ethical AI. Until users have real control over how algorithms behave, something is missing in current AI solutions. This causes massive distrust in AI, and apathy towards AI ethics solutions. The scope of this paper is to propose an alternative path that allows for the plurality of values and the freedom of individual expression. Both are essential for realizing true moral character.
Reward Reports for Reinforcement Learning
Apr 25, 2022
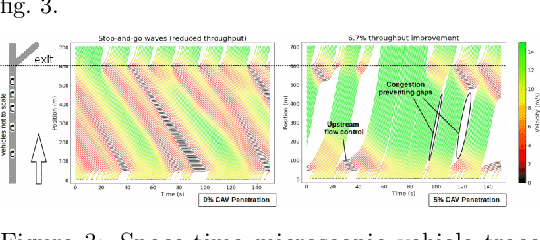
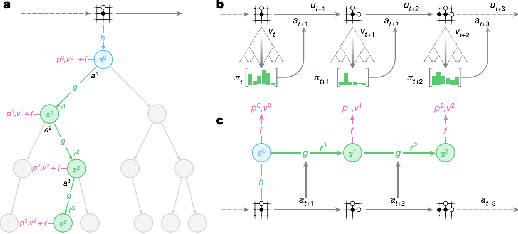

The desire to build good systems in the face of complex societal effects requires a dynamic approach towards equity and access. Recent approaches to machine learning (ML) documentation have demonstrated the promise of discursive frameworks for deliberation about these complexities. However, these developments have been grounded in a static ML paradigm, leaving the role of feedback and post-deployment performance unexamined. Meanwhile, recent work in reinforcement learning design has shown that the effects of optimization objectives on the resultant system behavior can be wide-ranging and unpredictable. In this paper we sketch a framework for documenting deployed learning systems, which we call Reward Reports. Taking inspiration from various contributions to the technical literature on reinforcement learning, we outline Reward Reports as living documents that track updates to design choices and assumptions behind what a particular automated system is optimizing for. They are intended to track dynamic phenomena arising from system deployment, rather than merely static properties of models or data. After presenting the elements of a Reward Report, we provide three examples: DeepMind's MuZero, MovieLens, and a hypothetical deployment of a Project Flow traffic control policy.
Choices, Risks, and Reward Reports: Charting Public Policy for Reinforcement Learning Systems
Feb 11, 2022In the long term, reinforcement learning (RL) is considered by many AI theorists to be the most promising path to artificial general intelligence. This places RL practitioners in a position to design systems that have never existed before and lack prior documentation in law and policy. Public agencies could intervene on complex dynamics that were previously too opaque to deliberate about, and long-held policy ambitions would finally be made tractable. In this whitepaper we illustrate this potential and how it might be technically enacted in the domains of energy infrastructure, social media recommender systems, and transportation. Alongside these unprecedented interventions come new forms of risk that exacerbate the harms already generated by standard machine learning tools. We correspondingly present a new typology of risks arising from RL design choices, falling under four categories: scoping the horizon, defining rewards, pruning information, and training multiple agents. Rather than allowing RL systems to unilaterally reshape human domains, policymakers need new mechanisms for the rule of reason, foreseeability, and interoperability that match the risks these systems pose. We argue that criteria for these choices may be drawn from emerging subfields within antitrust, tort, and administrative law. It will then be possible for courts, federal and state agencies, and non-governmental organizations to play more active roles in RL specification and evaluation. Building on the "model cards" and "datasheets" frameworks proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems. Reward Reports are living documents for proposed RL deployments that demarcate design choices.
* 60 pages
Hard Choices in Artificial Intelligence
Jun 10, 2021

As AI systems are integrated into high stakes social domains, researchers now examine how to design and operate them in a safe and ethical manner. However, the criteria for identifying and diagnosing safety risks in complex social contexts remain unclear and contested. In this paper, we examine the vagueness in debates about the safety and ethical behavior of AI systems. We show how this vagueness cannot be resolved through mathematical formalism alone, instead requiring deliberation about the politics of development as well as the context of deployment. Drawing from a new sociotechnical lexicon, we redefine vagueness in terms of distinct design challenges at key stages in AI system development. The resulting framework of Hard Choices in Artificial Intelligence (HCAI) empowers developers by 1) identifying points of overlap between design decisions and major sociotechnical challenges; 2) motivating the creation of stakeholder feedback channels so that safety issues can be exhaustively addressed. As such, HCAI contributes to a timely debate about the status of AI development in democratic societies, arguing that deliberation should be the goal of AI Safety, not just the procedure by which it is ensured.
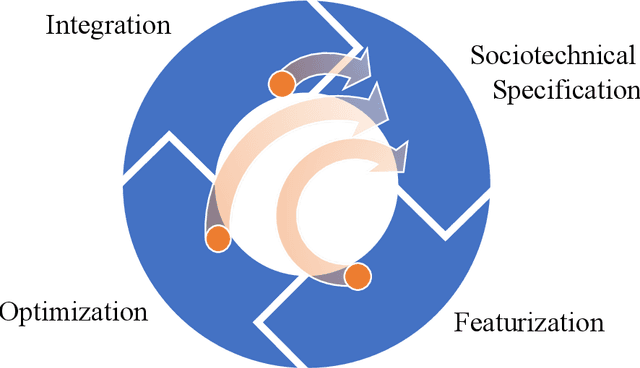
Axes for Sociotechnical Inquiry in AI Research
Apr 26, 2021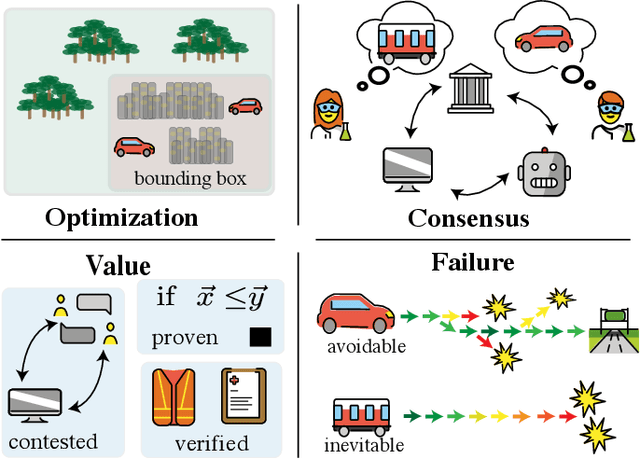
The development of artificial intelligence (AI) technologies has far exceeded the investigation of their relationship with society. Sociotechnical inquiry is needed to mitigate the harms of new technologies whose potential impacts remain poorly understood. To date, subfields of AI research develop primarily individual views on their relationship with sociotechnics, while tools for external investigation, comparison, and cross-pollination are lacking. In this paper, we propose four directions for inquiry into new and evolving areas of technological development: value--what progress and direction does a field promote, optimization--how the defined system within a problem formulation relates to broader dynamics, consensus--how agreement is achieved and who is included in building it, and failure--what methods are pursued when the problem specification is found wanting. The paper provides a lexicon for sociotechnical inquiry and illustrates it through the example of consumer drone technology.
AI Development for the Public Interest: From Abstraction Traps to Sociotechnical Risks
Feb 04, 2021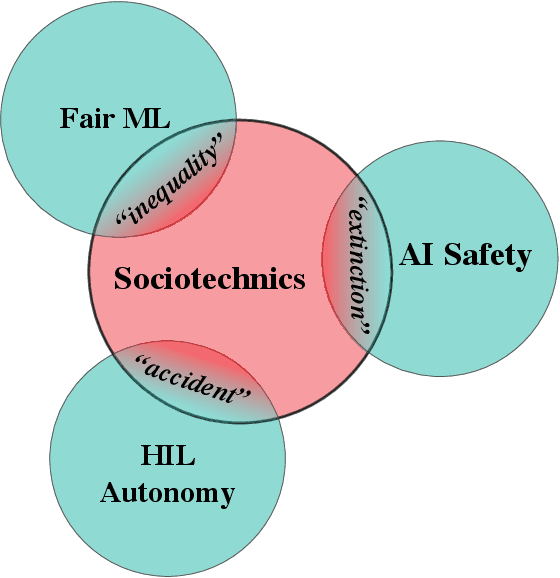
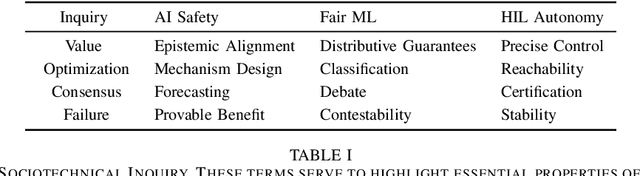
Despite interest in communicating ethical problems and social contexts within the undergraduate curriculum to advance Public Interest Technology (PIT) goals, interventions at the graduate level remain largely unexplored. This may be due to the conflicting ways through which distinct Artificial Intelligence (AI) research tracks conceive of their interface with social contexts. In this paper we track the historical emergence of sociotechnical inquiry in three distinct subfields of AI research: AI Safety, Fair Machine Learning (Fair ML) and Human-in-the-Loop (HIL) Autonomy. We show that for each subfield, perceptions of PIT stem from the particular dangers faced by past integration of technical systems within a normative social order. We further interrogate how these histories dictate the response of each subfield to conceptual traps, as defined in the Science and Technology Studies literature. Finally, through a comparative analysis of these currently siloed fields, we present a roadmap for a unified approach to sociotechnical graduate pedagogy in AI.
Hard Choices in Artificial Intelligence: Addressing Normative Uncertainty through Sociotechnical Commitments
Nov 20, 2019As AI systems become prevalent in high stakes domains such as surveillance and healthcare, researchers now examine how to design and implement them in a safe manner. However, the potential harms caused by systems to stakeholders in complex social contexts and how to address these remains unclear. In this paper, we explain the inherent normative uncertainty in debates about the safety of AI systems. We then address this as a problem of vagueness by examining its place in the design, training, and deployment stages of AI system development. We adopt Ruth Chang's theory of intuitive comparability to illustrate the dilemmas that manifest at each stage. We then discuss how stakeholders can navigate these dilemmas by incorporating distinct forms of dissent into the development pipeline, drawing on Elizabeth Anderson's work on the epistemic powers of democratic institutions. We outline a framework of sociotechnical commitments to formal, substantive and discursive challenges that address normative uncertainty across stakeholders, and propose the cultivation of related virtues by those responsible for development.