 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data-Driven to Purpose-Driven Artificial Intelligence: Systems Thinking for Data-Analytic Automation of Patient Care
Jun 16, 2025In this work, we reflect on the data-driven modeling paradigm that is gaining ground in AI-driven automation of patient care. We argue that the repurposing of existing real-world patient datasets for machine learning may not always represent an optimal approach to model development as it could lead to undesirable outcomes in patient care. We reflect on the history of data analysis to explain how the data-driven paradigm rose to popularity, and we envision ways in which systems thinking and clinical domain theory could complement the existing model development approaches in reaching human-centric outcomes. We call for a purpose-driven machine learning paradigm that is grounded in clinical theory and the sociotechnical realities of real-world operational contexts. We argue that understanding the utility of existing patient datasets requires looking in two directions: upstream towards the data generation, and downstream towards the automation objectives. This purpose-driven perspective to AI system development opens up new methodological opportunities and holds promise for AI automation of patient care.
From Silos to Systems: Process-Oriented Hazard Analysis for AI Systems
Oct 29, 2024
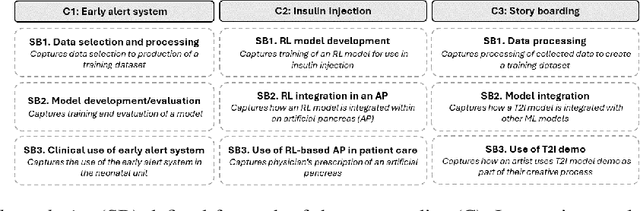
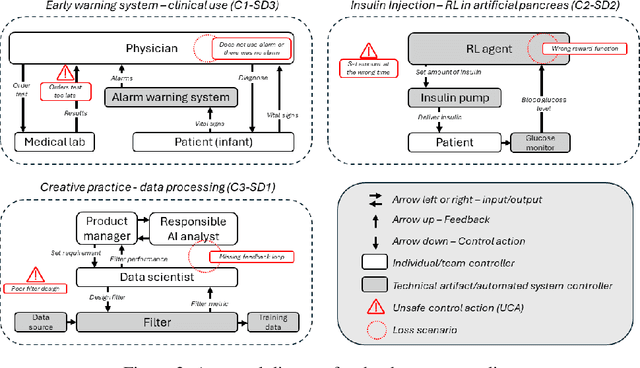
To effectively address potential harms from AI systems, it is essential to identify and mitigate system-level hazards. Current analysis approaches focus on individual components of an AI system, like training data or models, in isolation, overlooking hazards from component interactions or how they are situated within a company's development process. To this end, we draw from the established field of system safety, which considers safety as an emergent property of the entire system, not just its components. In this work, we translate System Theoretic Process Analysis (STPA) - a recognized system safety framework - for analyzing AI operation and development processes. We focus on systems that rely on machine learning algorithms and conducted STPA on three case studies involving linear regression, reinforcement learning, and transformer-based generative models. Our analysis explored how STPA's control and system-theoretic perspectives apply to AI systems and whether unique AI traits - such as model opacity, capability uncertainty, and output complexity - necessitate significant modifications to the framework. We find that the key concepts and steps of conducting an STPA readily apply, albeit with a few adaptations tailored for AI systems. We present the Process-oriented Hazard Analysis for AI Systems (PHASE) as a guideline that adapts STPA concepts for AI, making STPA-based hazard analysis more accessible. PHASE enables four key affordances for analysts responsible for managing AI system harms: 1) detection of hazards at the systems level, including those from accumulation of disparate issues; 2) explicit acknowledgment of social factors contributing to experiences of algorithmic harms; 3) creation of traceable accountability chains between harms and those who can mitigate the harm; and 4) ongoing monitoring and mitigation of new hazards.
AI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Jun 26, 2024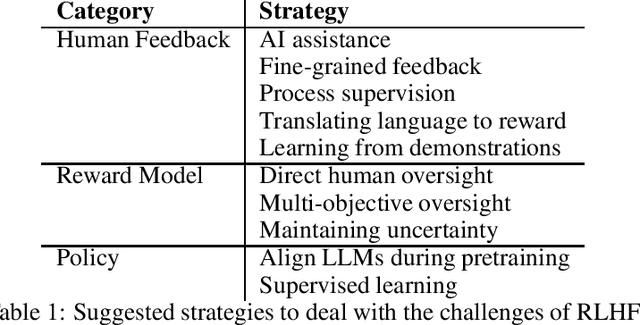
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
Hard Choices in Artificial Intelligence
Jun 10, 2021

As AI systems are integrated into high stakes social domains, researchers now examine how to design and operate them in a safe and ethical manner. However, the criteria for identifying and diagnosing safety risks in complex social contexts remain unclear and contested. In this paper, we examine the vagueness in debates about the safety and ethical behavior of AI systems. We show how this vagueness cannot be resolved through mathematical formalism alone, instead requiring deliberation about the politics of development as well as the context of deployment. Drawing from a new sociotechnical lexicon, we redefine vagueness in terms of distinct design challenges at key stages in AI system development. The resulting framework of Hard Choices in Artificial Intelligence (HCAI) empowers developers by 1) identifying points of overlap between design decisions and major sociotechnical challenges; 2) motivating the creation of stakeholder feedback channels so that safety issues can be exhaustively addressed. As such, HCAI contributes to a timely debate about the status of AI development in democratic societies, arguing that deliberation should be the goal of AI Safety, not just the procedure by which it is ensured.
Hard Choices in Artificial Intelligence: Addressing Normative Uncertainty through Sociotechnical Commitments
Nov 20, 2019As AI systems become prevalent in high stakes domains such as surveillance and healthcare, researchers now examine how to design and implement them in a safe manner. However, the potential harms caused by systems to stakeholders in complex social contexts and how to address these remains unclear. In this paper, we explain the inherent normative uncertainty in debates about the safety of AI systems. We then address this as a problem of vagueness by examining its place in the design, training, and deployment stages of AI system development. We adopt Ruth Chang's theory of intuitive comparability to illustrate the dilemmas that manifest at each stage. We then discuss how stakeholders can navigate these dilemmas by incorporating distinct forms of dissent into the development pipeline, drawing on Elizabeth Anderson's work on the epistemic powers of democratic institutions. We outline a framework of sociotechnical commitments to formal, substantive and discursive challenges that address normative uncertainty across stakeholders, and propose the cultivation of related virtues by those responsible for development.
Regression-based Inverter Control for Decentralized Optimal Power Flow and Voltage Regulation
Feb 20, 2019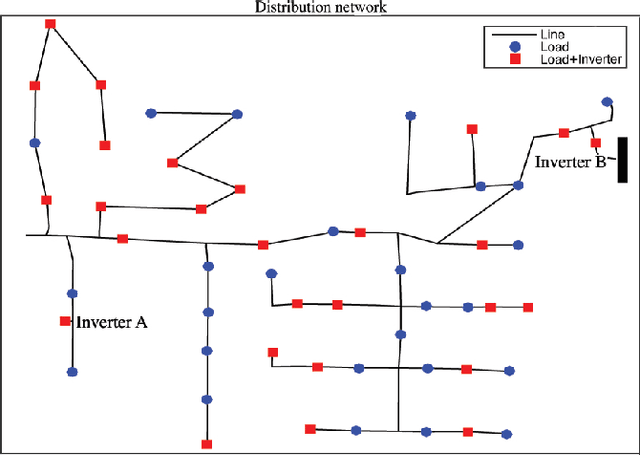
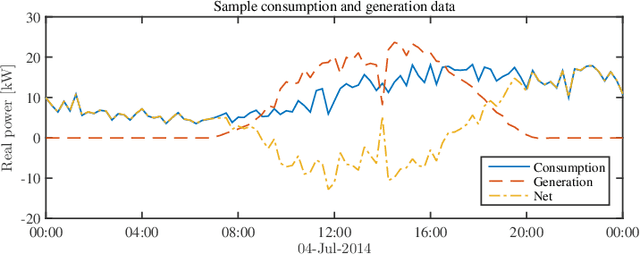
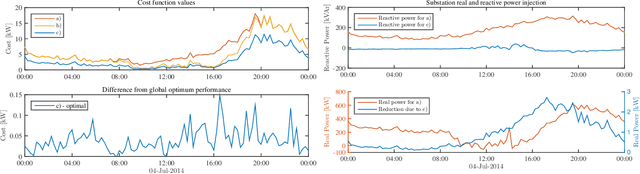
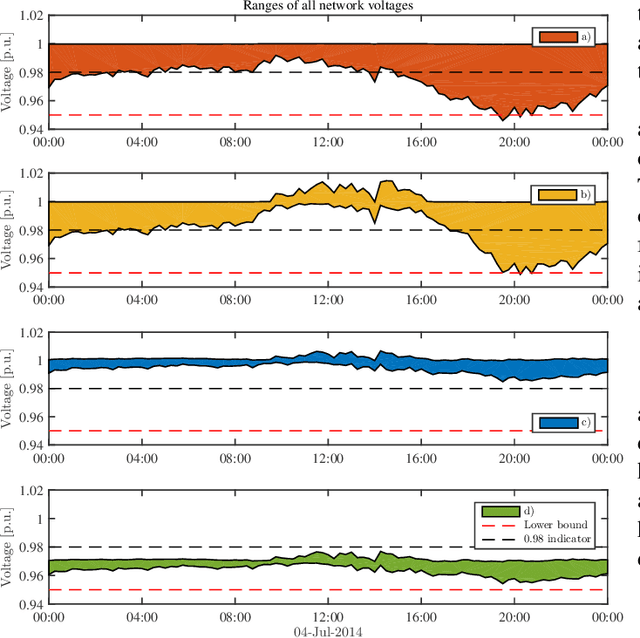
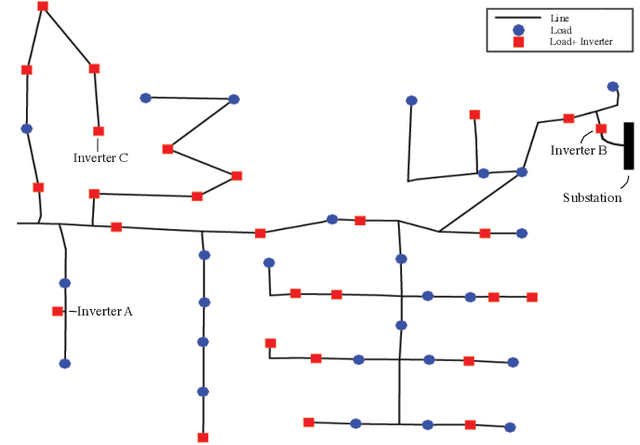
Electronic power inverters are capable of quickly delivering reactive power to maintain customer voltages within operating tolerances and to reduce system losses in distribution grids. This paper proposes a systematic and data-driven approach to determine reactive power inverter output as a function of local measurements in a manner that obtains near optimal results. First, we use a network model and historic load and generation data and do optimal power flow to compute globally optimal reactive power injections for all controllable inverters in the network. Subsequently, we use regression to find a function for each inverter that maps its local historical data to an approximation of its optimal reactive power injection. The resulting functions then serve as decentralized controllers in the participating inverters to predict the optimal injection based on a new local measurements. The method achieves near-optimal results when performing voltage- and capacity-constrained loss minimization and voltage flattening, and allows for an efficient volt-VAR optimization (VVO) scheme in which legacy control equipment collaborates with existing inverters to facilitate safe operation of distribution networks with higher levels of distributed generation.
A Broader View on Bias in Automated Decision-Making: Reflecting on Epistemology and Dynamics
Jul 06, 2018
Machine learning (ML) is increasingly deployed in real world contexts, supplying actionable insights and forming the basis of automated decision-making systems. While issues resulting from biases pre-existing in training data have been at the center of the fairness debate, these systems are also affected by technical and emergent biases, which often arise as context-specific artifacts of implementation. This position paper interprets technical bias as an epistemological problem and emergent bias as a dynamical feedback phenomenon. In order to stimulate debate on how to change machine learning practice to effectively address these issues, we explore this broader view on bias, stress the need to reflect on epistemology, and point to value-sensitive design methodologies to revisit the design and implementation process of automated decision-making systems.
Data-Driven Decentralized Optimal Power Flow
Jun 14, 2018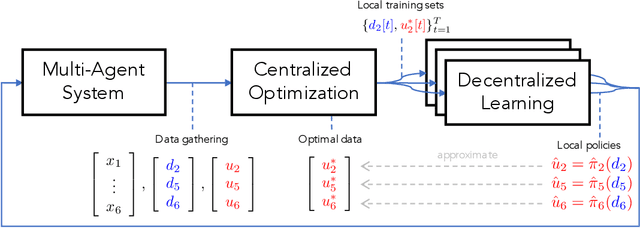
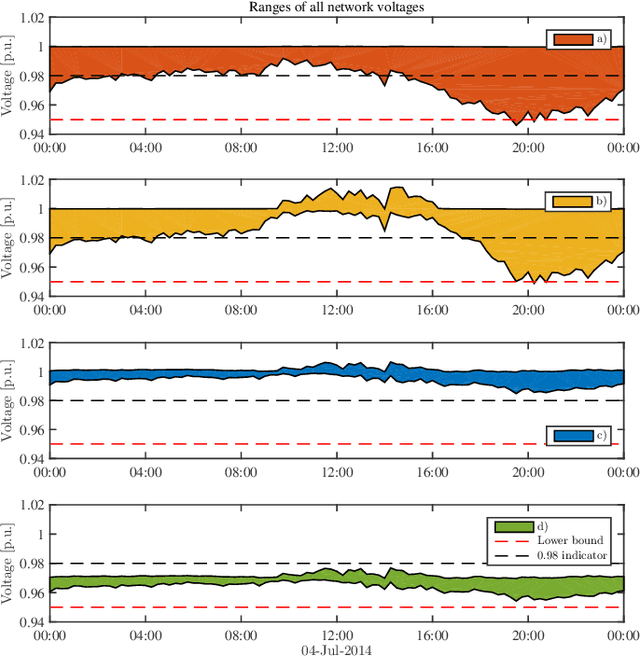
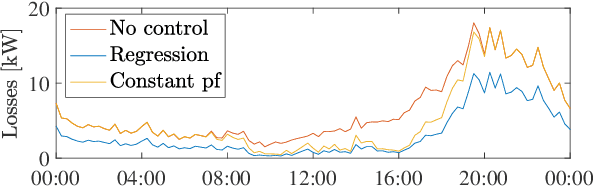
The implementation of optimal power flow (OPF) methods to perform voltage and power flow regulation in electric networks is generally believed to require communication. We consider distribution systems with multiple controllable Distributed Energy Resources (DERs) and present a data-driven approach to learn control policies for each DER to reconstruct and mimic the solution to a centralized OPF problem from solely locally available information. Collectively, all local controllers closely match the centralized OPF solution, providing near-optimal performance and satisfaction of system constraints. A rate distortion framework facilitates the analysis of how well the resulting fully decentralized control policies are able to reconstruct the OPF solution. Our methodology provides a natural extension to decide what buses a DER should communicate with to improve the reconstruction of its individual policy. The method is applied on both single- and three-phase test feeder networks using data from real loads and distributed generators. It provides a framework for Distribution System Operators to efficiently plan and operate the contributions of DERs to active distribution networks.
On Identification of Distribution Grids
Nov 05, 2017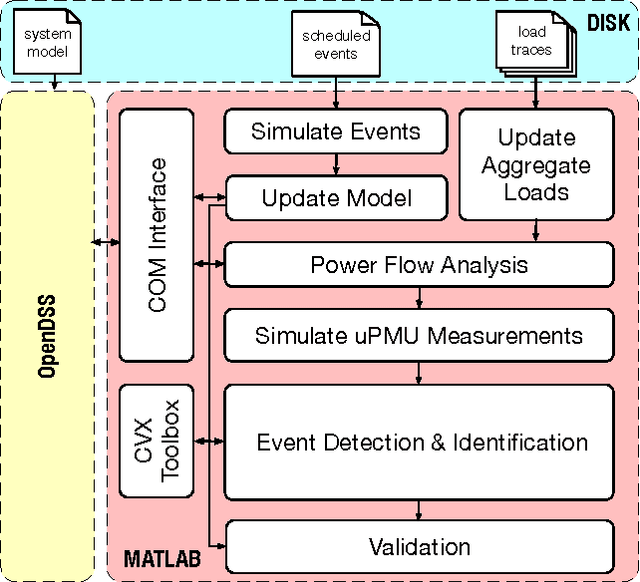
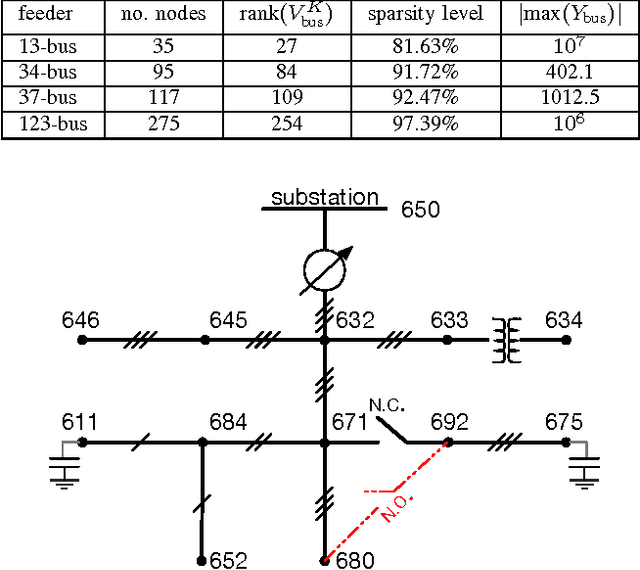
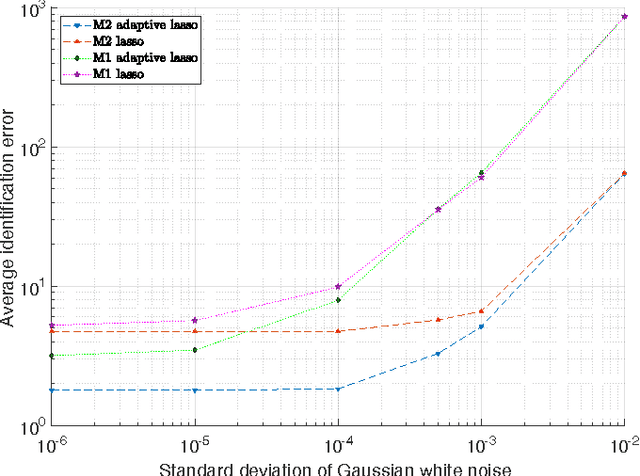
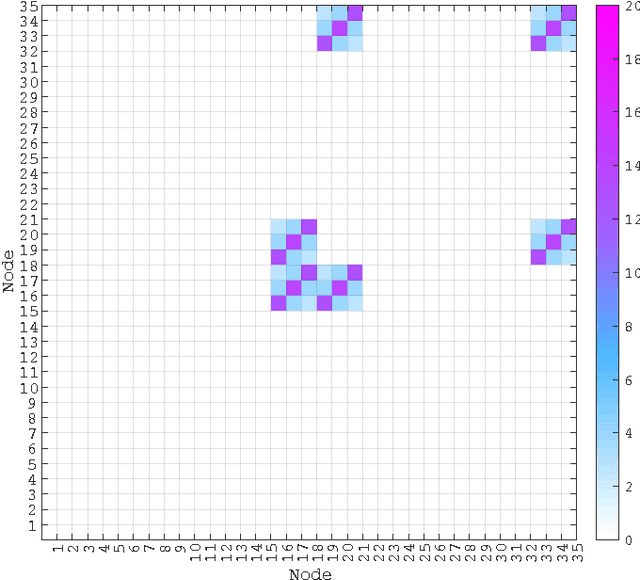
Large-scale integration of distributed energy resources into residential distribution feeders necessitates careful control of their operation through power flow analysis. While the knowledge of the distribution system model is crucial for this type of analysis, it is often unavailable or outdated. The recent introduction of synchrophasor technology in low-voltage distribution grids has created an unprecedented opportunity to learn this model from high-precision, time-synchronized measurements of voltage and current phasors at various locations. This paper focuses on joint estimation of model parameters (admittance values) and operational structure of a poly-phase distribution network from the available telemetry data via the lasso, a method for regression shrinkage and selection. We propose tractable convex programs capable of tackling the low rank structure of the distribution system and develop an online algorithm for early detection and localization of critical events that induce a change in the admittance matrix. The efficacy of these techniques is corroborated through power flow studies on four three-phase radial distribution systems serving real household demands.
Fully Decentralized Policies for Multi-Agent Systems: An Information Theoretic Approach
Jul 29, 2017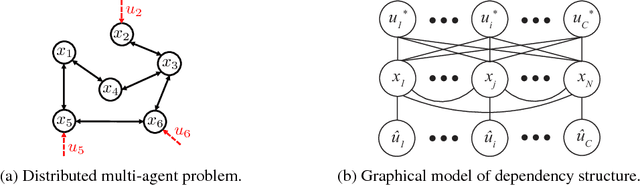



Learning cooperative policies for multi-agent systems is often challenged by partial observability and a lack of coordination. In some settings, the structure of a problem allows a distributed solution with limited communication. Here, we consider a scenario where no communication is available, and instead we learn local policies for all agents that collectively mimic the solution to a centralized multi-agent static optimization problem. Our main contribution is an information theoretic framework based on rate distortion theory which facilitates analysis of how well the resulting fully decentralized policies are able to reconstruct the optimal solution. Moreover, this framework provides a natural extension that addresses which nodes an agent should communicate with to improve the performance of its individual policy.