 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Silos to Systems: Process-Oriented Hazard Analysis for AI Systems
Paper and Code
Oct 29, 2024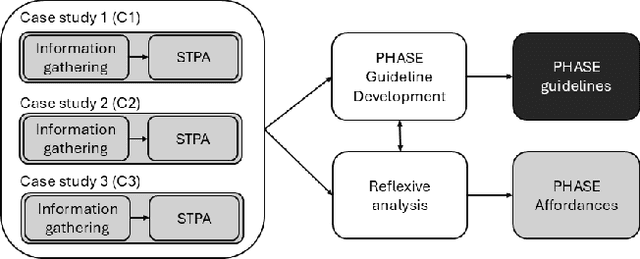
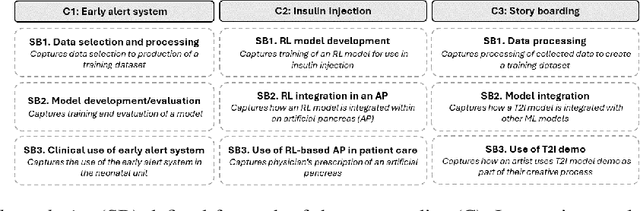
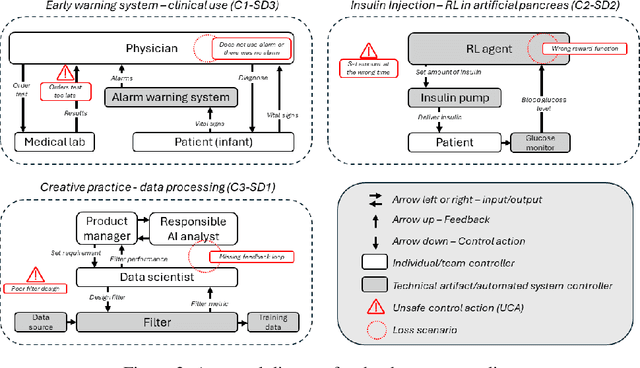
To effectively address potential harms from AI systems, it is essential to identify and mitigate system-level hazards. Current analysis approaches focus on individual components of an AI system, like training data or models, in isolation, overlooking hazards from component interactions or how they are situated within a company's development process. To this end, we draw from the established field of system safety, which considers safety as an emergent property of the entire system, not just its components. In this work, we translate System Theoretic Process Analysis (STPA) - a recognized system safety framework - for analyzing AI operation and development processes. We focus on systems that rely on machine learning algorithms and conducted STPA on three case studies involving linear regression, reinforcement learning, and transformer-based generative models. Our analysis explored how STPA's control and system-theoretic perspectives apply to AI systems and whether unique AI traits - such as model opacity, capability uncertainty, and output complexity - necessitate significant modifications to the framework. We find that the key concepts and steps of conducting an STPA readily apply, albeit with a few adaptations tailored for AI systems. We present the Process-oriented Hazard Analysis for AI Systems (PHASE) as a guideline that adapts STPA concepts for AI, making STPA-based hazard analysis more accessible. PHASE enables four key affordances for analysts responsible for managing AI system harms: 1) detection of hazards at the systems level, including those from accumulation of disparate issues; 2) explicit acknowledgment of social factors contributing to experiences of algorithmic harms; 3) creation of traceable accountability chains between harms and those who can mitigate the harm; and 4) ongoing monitoring and mitigation of new hazards.