 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Usage of Generative AI Models in Student Learning Activities for Software Programming
Nov 17, 2025The rise of Generative AI (GenAI) tools like ChatGPT has created new opportunities and challenges for computing education. Existing research has primarily focused on GenAI's ability to complete educational tasks and its impact on student performance, often overlooking its effects on knowledge gains. In this study, we investigate how GenAI assistance compares to conventional online resources in supporting knowledge gains across different proficiency levels. We conducted a controlled user experiment with 24 undergraduate students of two different levels of programming experience (beginner, intermediate) to examine how students interact with ChatGPT while solving programming tasks. We analyzed task performance, conceptual understanding, and interaction behaviors. Our findings reveal that generating complete solutions with GenAI significantly improves task performance, especially for beginners, but does not consistently result in knowledge gains. Importantly, usage strategies differ by experience: beginners tend to rely heavily on GenAI toward task completion often without knowledge gain in the process, while intermediates adopt more selective approaches. We find that both over-reliance and minimal use result in weaker knowledge gains overall. Based on our results, we call on students and educators to adopt GenAI as a learning rather than a problem solving tool. Our study highlights the urgent need for guidance when integrating GenAI into programming education to foster deeper understanding.
Opening the Scope of Openness in AI
May 09, 2025


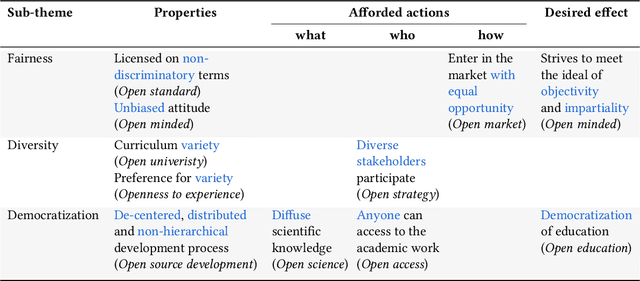
The concept of openness in AI has so far been heavily inspired by the definition and community practice of open source software. This positions openness in AI as having positive connotations; it introduces assumptions of certain advantages, such as collaborative innovation and transparency. However, the practices and benefits of open source software are not fully transferable to AI, which has its own challenges. Framing a notion of openness tailored to AI is crucial to addressing its growing societal implications, risks, and capabilities. We argue that considering the fundamental scope of openness in different disciplines will broaden discussions, introduce important perspectives, and reflect on what openness in AI should mean. Toward this goal, we qualitatively analyze 98 concepts of openness discovered from topic modeling, through which we develop a taxonomy of openness. Using this taxonomy as an instrument, we situate the current discussion on AI openness, identify gaps and highlight links with other disciplines. Our work contributes to the recent efforts in framing openness in AI by reflecting principles and practices of openness beyond open source software and calls for a more holistic view of openness in terms of actions, system properties, and ethical objectives.
From Silos to Systems: Process-Oriented Hazard Analysis for AI Systems
Oct 29, 2024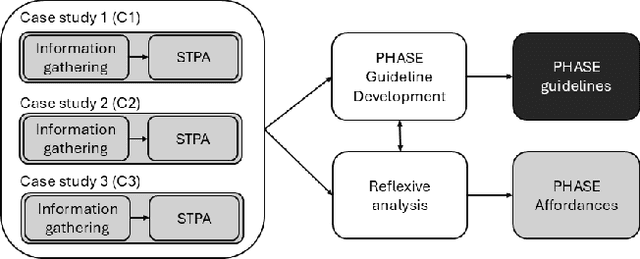
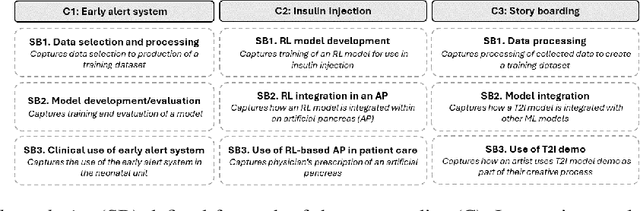
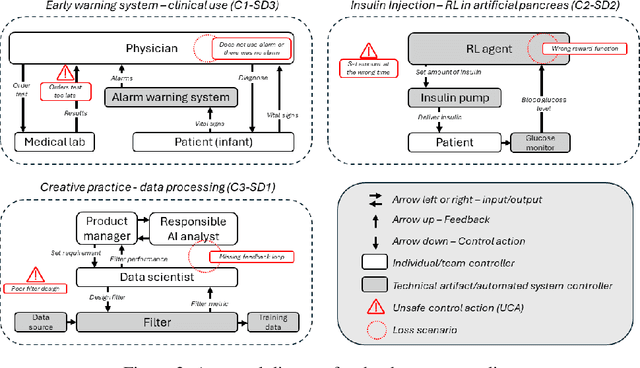
To effectively address potential harms from AI systems, it is essential to identify and mitigate system-level hazards. Current analysis approaches focus on individual components of an AI system, like training data or models, in isolation, overlooking hazards from component interactions or how they are situated within a company's development process. To this end, we draw from the established field of system safety, which considers safety as an emergent property of the entire system, not just its components. In this work, we translate System Theoretic Process Analysis (STPA) - a recognized system safety framework - for analyzing AI operation and development processes. We focus on systems that rely on machine learning algorithms and conducted STPA on three case studies involving linear regression, reinforcement learning, and transformer-based generative models. Our analysis explored how STPA's control and system-theoretic perspectives apply to AI systems and whether unique AI traits - such as model opacity, capability uncertainty, and output complexity - necessitate significant modifications to the framework. We find that the key concepts and steps of conducting an STPA readily apply, albeit with a few adaptations tailored for AI systems. We present the Process-oriented Hazard Analysis for AI Systems (PHASE) as a guideline that adapts STPA concepts for AI, making STPA-based hazard analysis more accessible. PHASE enables four key affordances for analysts responsible for managing AI system harms: 1) detection of hazards at the systems level, including those from accumulation of disparate issues; 2) explicit acknowledgment of social factors contributing to experiences of algorithmic harms; 3) creation of traceable accountability chains between harms and those who can mitigate the harm; and 4) ongoing monitoring and mitigation of new hazards.
Improving Reinforcement Learning Training Regimes for Social Robot Navigation
Aug 29, 2023

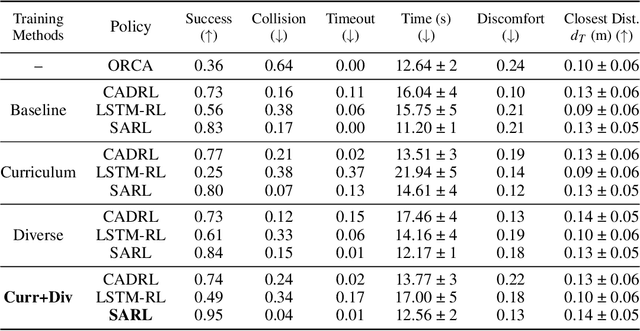

In order for autonomous mobile robots to navigate in human spaces, they must abide by our social norms. Reinforcement learning (RL) has emerged as an effective method to train robot navigation policies that are able to respect these norms. However, a large portion of existing work in the field conducts both RL training and testing in simplistic environments. This limits the generalization potential of these models to unseen environments, and the meaningfulness of their reported results. We propose a method to improve the generalization performance of RL social navigation methods using curriculum learning. By employing multiple environment types and by modeling pedestrians using multiple dynamics models, we are able to progressively diversify and escalate difficulty in training. Our results show that the use of curriculum learning in training can be used to achieve better generalization performance than previous training methods. We also show that results presented in many existing state-of-the art RL social navigation works do not evaluate their methods outside of their training environments, and thus do not reflect their policies' failure to adequately generalize to out-of-distribution scenarios. In response, we validate our training approach on larger and more crowded testing environments than those used in training, allowing for more meaningful measurements of model performance.
From plane crashes to algorithmic harm: applicability of safety engineering frameworks for responsible ML
Oct 06, 2022
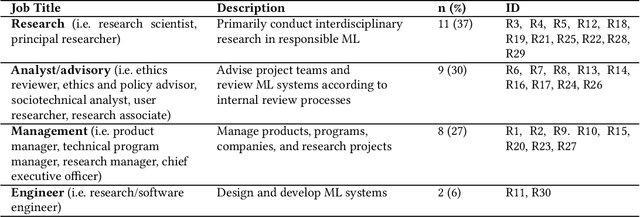
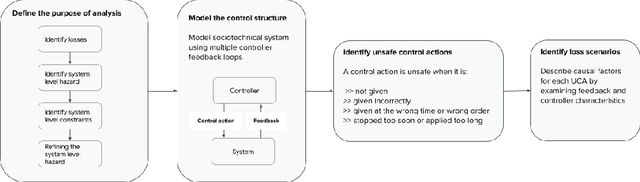
Inappropriate design and deployment of machine learning (ML) systems leads to negative downstream social and ethical impact -- described here as social and ethical risks -- for users, society and the environment. Despite the growing need to regulate ML systems, current processes for assessing and mitigating risks are disjointed and inconsistent. We interviewed 30 industry practitioners on their current social and ethical risk management practices, and collected their first reactions on adapting safety engineering frameworks into their practice -- namely, System Theoretic Process Analysis (STPA) and Failure Mode and Effects Analysis (FMEA). Our findings suggest STPA/FMEA can provide appropriate structure toward social and ethical risk assessment and mitigation processes. However, we also find nontrivial challenges in integrating such frameworks in the fast-paced culture of the ML industry. We call on the ML research community to strengthen existing frameworks and assess their efficacy, ensuring that ML systems are safer for all people.