 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift Q-Learning
May 29, 2026Offline reinforcement learning requires improving a policy from fixed data while avoiding out-of-distribution actions with unreliable value estimates. Diffusion and flow policies handle this trade-off by modeling the behavior distribution to regularize the RL objective, but they require iterative denoising, solver integrations, and in more efficient variants, distillation or other approximations at inference. We propose DriftQL, which combines a drift-based behavioral regularizer with critic-driven policy improvement. The value signal biases the policy toward high-value regions of the data support, while attraction and repulsion together keep generated actions near the data and prevent collapse onto a single mode. DriftQL is implemented as a single network with a unified training objective and generates actions in a single forward pass. On D4RL and OGBench, DriftQL consistently outperforms diffusion and flow methods, advancing the state of the art. Under degraded data quality, where the baselines visibly struggle, DriftQL remains close to its clean-data performance, positioning it as a promising alternative to diffusion and flow-based methods while maintaining the simplicity and efficiency of deterministic approaches. Project page: https://driftql.github.io/
Toward Hardware-Agnostic Quadrupedal World Models via Morphology Conditioning
Apr 09, 2026World models promise a paradigm shift in robotics, where an agent learns the underlying physics of its environment once to enable efficient planning and behavior learning. However, current world models are often hardware-locked specialists: a model trained on a Boston Dynamics Spot robot fails catastrophically on a Unitree Go1 due to the mismatch in kinematic and dynamic properties, as the model overfits to specific embodiment constraints rather than capturing the universal locomotion dynamics. Consequently, a slight change in actuator dynamics or limb length necessitates training a new model from scratch. In this work, we take a step towards a framework for training a generalizable Quadrupedal World Model (QWM) that disentangles environmental dynamics from robot morphology. We address the limitations of implicit system identification, where treating static physical properties (like mass or limb length) as latent variables to be inferred from motion history creates an adaptation lag that can compromise zero-shot safety and efficiency. Instead, we explicitly condition the generative dynamics on the robot's engineering specifications. By integrating a physical morphology encoder and a reward normalizer, we enable the model to serve as a neural simulator capable of generalizing across morphologies. This capability unlocks zero-shot control across a range of embodiments. We introduce, for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion. While we carefully study the limitations of our method, QWM operates as a distribution-bounded interpolator within the quadrupedal morphology family rather than a universal physics engine, this work represents a significant step toward morphology-conditioned world models for legged locomotion.
SLowRL: Safe Low-Rank Adaptation Reinforcement Learning for Locomotion
Mar 17, 2026Sim-to-real transfer of locomotion policies often leads to performance degradation due to the inevitable sim-to-real gap. Naively fine-tuning these policies directly on hardware is problematic, as it poses risks of mechanical failure and suffers from high sample inefficiency. In this paper, we address the challenge of safely and efficiently fine-tuning reinforcement learning (RL) policies for dynamic locomotion tasks. Specifically, we focus on fine-tuning policies learned in simulation directly on hardware, while explicitly enforcing safety constraints. In doing so, we introduce SLowRL, a framework that combines Low-Rank Adaptation (LoRA) with training-time safety enforcement via a recovery policy. We evaluate our method both in simulation and on a real Unitree Go2 quadruped robot for jump and trot tasks. Experimental results show that our method achieves a $46.5\%$ reduction in fine-tuning time and near-zero safety violations compared to standard proximal policy optimization (PPO) baselines. Notably, we find that a rank-1 adaptation alone is sufficient to recover pre-trained performance in the real world, while maintaining stable and safe real-world fine-tuning. These results demonstrate the practicality of safe, efficient fine-tuning for dynamic real-world robotic applications.
Tactile Modality Fusion for Vision-Language-Action Models
Mar 15, 2026We propose TacFiLM, a lightweight modality-fusion approach that integrates visual-tactile signals into vision-language-action (VLA) models. While recent advances in VLA models have introduced robot policies that are both generalizable and semantically grounded, these models mainly rely on vision-based perception. Vision alone, however, cannot capture the complex interaction dynamics that occur during contact-rich manipulation, including contact forces, surface friction, compliance, and shear. While recent attempts to integrate tactile signals into VLA models often increase complexity through token concatenation or large-scale pretraining, the heavy computational demands of behavioural models necessitate more lightweight fusion strategies. To address these challenges, TacFiLM outlines a post-training finetuning approach that conditions intermediate visual features on pretrained tactile representations using feature-wise linear modulation (FiLM). Experimental results on insertion tasks demonstrate consistent improvements in success rate, direct insertion performance, completion time, and force stability across both in-distribution and out-of-distribution tasks. Together, these results support our method as an effective approach to integrating tactile signals into VLA models, improving contact-rich manipulation behaviours.
Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
Jan 02, 2026Diffusion policies have emerged as powerful generative models for offline policy learning, whose sampling process can be rigorously characterized by a score function guiding a Stochastic Differential Equation (SDE). However, the same score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs solver and score-matching errors, large data requirements, and inconsistencies in action generation. While less critical in image generation, these inaccuracies compound and lead to failure in continuous control settings. We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the diffusion sampling dynamics. Contraction pulls nearby flows closer to enhance robustness against solver and score-matching errors while reducing unwanted action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and computational cost. We evaluate CDPs for offline learning by conducting extensive experiments in simulation and real-world settings. Across benchmarks, CDPs often outperform baseline policies, with pronounced benefits under data scarcity.
Safe Domain Randomization via Uncertainty-Aware Out-of-Distribution Detection and Policy Adaptation
Jul 08, 2025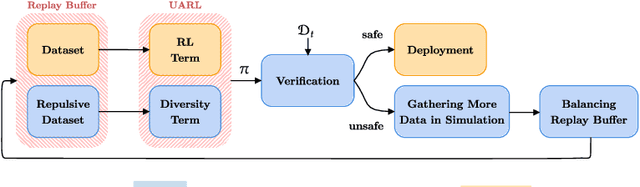
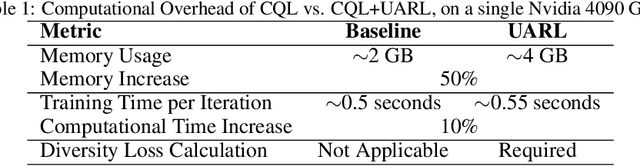


Deploying reinforcement learning (RL) policies in real-world involves significant challenges, including distribution shifts, safety concerns, and the impracticality of direct interactions during policy refinement. Existing methods, such as domain randomization (DR) and off-dynamics RL, enhance policy robustness by direct interaction with the target domain, an inherently unsafe practice. We propose Uncertainty-Aware RL (UARL), a novel framework that prioritizes safety during training by addressing Out-Of-Distribution (OOD) detection and policy adaptation without requiring direct interactions in target domain. UARL employs an ensemble of critics to quantify policy uncertainty and incorporates progressive environmental randomization to prepare the policy for diverse real-world conditions. By iteratively refining over high-uncertainty regions of the state space in simulated environments, UARL enhances robust generalization to the target domain without explicitly training on it. We evaluate UARL on MuJoCo benchmarks and a quadrupedal robot, demonstrating its effectiveness in reliable OOD detection, improved performance, and enhanced sample efficiency compared to baselines.
Contractive Dynamical Imitation Policies for Efficient Out-of-Sample Recovery
Dec 10, 2024Imitation learning is a data-driven approach to learning policies from expert behavior, but it is prone to unreliable outcomes in out-of-sample (OOS) regions. While previous research relying on stable dynamical systems guarantees convergence to a desired state, it often overlooks transient behavior. We propose a framework for learning policies using modeled by contractive dynamical systems, ensuring that all policy rollouts converge regardless of perturbations, and in turn, enable efficient OOS recovery. By leveraging recurrent equilibrium networks and coupling layers, the policy structure guarantees contractivity for any parameter choice, which facilitates unconstrained optimization. Furthermore, we provide theoretical upper bounds for worst-case and expected loss terms, rigorously establishing the reliability of our method in deployment. Empirically, we demonstrate substantial OOS performance improvements in robotics manipulation and navigation tasks in simulation.
Single-Shot Learning of Stable Dynamical Systems for Long-Horizon Manipulation Tasks
Oct 01, 2024Mastering complex sequential tasks continues to pose a significant challenge in robotics. While there has been progress in learning long-horizon manipulation tasks, most existing approaches lack rigorous mathematical guarantees for ensuring reliable and successful execution. In this paper, we extend previous work on learning long-horizon tasks and stable policies, focusing on improving task success rates while reducing the amount of training data needed. Our approach introduces a novel method that (1) segments long-horizon demonstrations into discrete steps defined by waypoints and subgoals, and (2) learns globally stable dynamical system policies to guide the robot to each subgoal, even in the face of sensory noise and random disturbances. We validate our approach through both simulation and real-world experiments, demonstrating effective transfer from simulation to physical robotic platforms. Code is available at https://github.com/Alestaubin/stable-imitation-policy-with-waypoints
Globally Stable Neural Imitation Policies
Mar 07, 2024



Imitation learning presents an effective approach to alleviate the resource-intensive and time-consuming nature of policy learning from scratch in the solution space. Even though the resulting policy can mimic expert demonstrations reliably, it often lacks predictability in unexplored regions of the state-space, giving rise to significant safety concerns in the face of perturbations. To address these challenges, we introduce the Stable Neural Dynamical System (SNDS), an imitation learning regime which produces a policy with formal stability guarantees. We deploy a neural policy architecture that facilitates the representation of stability based on Lyapunov theorem, and jointly train the policy and its corresponding Lyapunov candidate to ensure global stability. We validate our approach by conducting extensive experiments in simulation and successfully deploying the trained policies on a real-world manipulator arm. The experimental results demonstrate that our method overcomes the instability, accuracy, and computational intensity problems associated with previous imitation learning methods, making our method a promising solution for stable policy learning in complex planning scenarios.
Learning Lyapunov-Stable Polynomial Dynamical Systems Through Imitation
Oct 31, 2023



Imitation learning is a paradigm to address complex motion planning problems by learning a policy to imitate an expert's behavior. However, relying solely on the expert's data might lead to unsafe actions when the robot deviates from the demonstrated trajectories. Stability guarantees have previously been provided utilizing nonlinear dynamical systems, acting as high-level motion planners, in conjunction with the Lyapunov stability theorem. Yet, these methods are prone to inaccurate policies, high computational cost, sample inefficiency, or quasi stability when replicating complex and highly nonlinear trajectories. To mitigate this problem, we present an approach for learning a globally stable nonlinear dynamical system as a motion planning policy. We model the nonlinear dynamical system as a parametric polynomial and learn the polynomial's coefficients jointly with a Lyapunov candidate. To showcase its success, we compare our method against the state of the art in simulation and conduct real-world experiments with the Kinova Gen3 Lite manipulator arm. Our experiments demonstrate the sample efficiency and reproduction accuracy of our method for various expert trajectories, while remaining stable in the face of perturbations.