 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Statistical Effect of Rubric Modifications on Human-Autorater Agreement
May 07, 2026Autoraters, also referred to as LLM-as-judges, are increasingly used for evaluation and automated content moderation. However, there is limited statistical analysis of how modifications in a rubric presented to both humans and autoraters affect their score agreement. Rubrics that ask for an overall or \emph{holistic} judgment - for example, rating the ``quality'' of an essay - may be inconsistently interpreted due to the complexity or subjectivity of the criteria. Conversely, rubrics can ask for \emph{analytic} judgments, which decompose assessment criteria - for example, ``quality'' into ``fluency'' and ``organization''. While these rubrics can be edited to improve the individual accuracy of both human and automated scoring, this approach may result in disagreement between the two scores, or with the associated holistic judgment. Designing and deploying reliable autoraters requires understanding not just the relationship between human and autorater annotations but how that relationship changes as holistic or analytic judgments are elicited. The results indicate that rubric edits providing representative examples and additional context, and reducing positional bias in the rubric increased human-autorater agreement, while higher rubric complexity and conservative aggregation methods tended to decrease it. The findings from the automatic essay scoring and instruction-following evaluation domains suggest that practitioners should carefully analyze domain- and rubric-specific performance to move towards higher human-autorater agreement.
A Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
Harm Amplification in Text-to-Image Models
Feb 01, 2024



Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by first introducing a formal definition for this phenomenon, termed harm amplification. We further contribute to the field by developing methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Safety and Fairness for Content Moderation in Generative Models
Jun 09, 2023



With significant advances in generative AI, new technologies are rapidly being deployed with generative components. Generative models are typically trained on large datasets, resulting in model behaviors that can mimic the worst of the content in the training data. Responsible deployment of generative technologies requires content moderation strategies, such as safety input and output filters. Here, we provide a theoretical framework for conceptualizing responsible content moderation of text-to-image generative technologies, including a demonstration of how to empirically measure the constructs we enumerate. We define and distinguish the concepts of safety, fairness, and metric equity, and enumerate example harms that can come in each domain. We then provide a demonstration of how the defined harms can be quantified. We conclude with a summary of how the style of harms quantification we demonstrate enables data-driven content moderation decisions.
AI's Regimes of Representation: A Community-centered Study of Text-to-Image Models in South Asia
May 19, 2023



This paper presents a community-centered study of cultural limitations of text-to-image (T2I) models in the South Asian context. We theorize these failures using scholarship on dominant media regimes of representations and locate them within participants' reporting of their existing social marginalizations. We thus show how generative AI can reproduce an outsiders gaze for viewing South Asian cultures, shaped by global and regional power inequities. By centering communities as experts and soliciting their perspectives on T2I limitations, our study adds rich nuance into existing evaluative frameworks and deepens our understanding of the culturally-specific ways AI technologies can fail in non-Western and Global South settings. We distill lessons for responsible development of T2I models, recommending concrete pathways forward that can allow for recognition of structural inequalities.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
From plane crashes to algorithmic harm: applicability of safety engineering frameworks for responsible ML
Oct 06, 2022
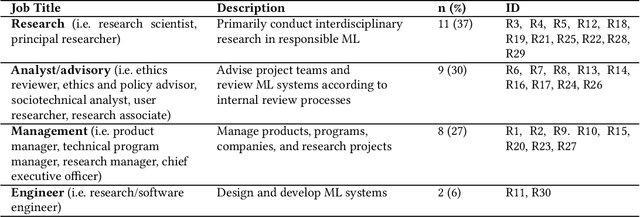
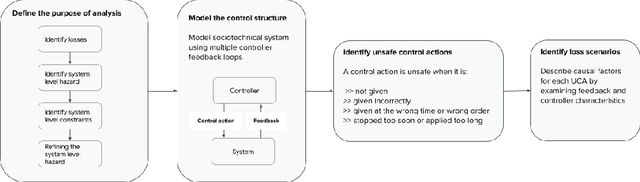
Inappropriate design and deployment of machine learning (ML) systems leads to negative downstream social and ethical impact -- described here as social and ethical risks -- for users, society and the environment. Despite the growing need to regulate ML systems, current processes for assessing and mitigating risks are disjointed and inconsistent. We interviewed 30 industry practitioners on their current social and ethical risk management practices, and collected their first reactions on adapting safety engineering frameworks into their practice -- namely, System Theoretic Process Analysis (STPA) and Failure Mode and Effects Analysis (FMEA). Our findings suggest STPA/FMEA can provide appropriate structure toward social and ethical risk assessment and mitigation processes. However, we also find nontrivial challenges in integrating such frameworks in the fast-paced culture of the ML industry. We call on the ML research community to strengthen existing frameworks and assess their efficacy, ensuring that ML systems are safer for all people.