 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
Dec 23, 2025As LLM-based judges become integral to industry applications, obtaining well-calibrated uncertainty estimates efficiently has become critical for production deployment. However, existing techniques, such as verbalized confidence and multi-generation methods, are often either poorly calibrated or computationally expensive. We introduce linear probes trained with a Brier score-based loss to provide calibrated uncertainty estimates from reasoning judges' hidden states, requiring no additional model training. We evaluate our approach on both objective tasks (reasoning, mathematics, factuality, coding) and subjective human preference judgments. Our results demonstrate that probes achieve superior calibration compared to existing methods with $\approx10$x computational savings, generalize robustly to unseen evaluation domains, and deliver higher accuracy on high-confidence predictions. However, probes produce conservative estimates that underperform on easier datasets but may benefit safety-critical deployments prioritizing low false-positive rates. Overall, our work demonstrates that interpretability-based uncertainty estimation provides a practical and scalable plug-and-play solution for LLM judges in production.
Arbiters of Ambivalence: Challenges of Using LLMs in No-Consensus Tasks
May 28, 2025The increasing use of LLMs as substitutes for humans in ``aligning'' LLMs has raised questions about their ability to replicate human judgments and preferences, especially in ambivalent scenarios where humans disagree. This study examines the biases and limitations of LLMs in three roles: answer generator, judge, and debater. These roles loosely correspond to previously described alignment frameworks: preference alignment (judge) and scalable oversight (debater), with the answer generator reflecting the typical setting with user interactions. We develop a ``no-consensus'' benchmark by curating examples that encompass a variety of a priori ambivalent scenarios, each presenting two possible stances. Our results show that while LLMs can provide nuanced assessments when generating open-ended answers, they tend to take a stance on no-consensus topics when employed as judges or debaters. These findings underscore the necessity for more sophisticated methods for aligning LLMs without human oversight, highlighting that LLMs cannot fully capture human disagreement even on topics where humans themselves are divided.
Chained Tuning Leads to Biased Forgetting
Dec 21, 2024



Large language models (LLMs) are often fine-tuned for use on downstream tasks, though this can degrade capabilities learned during previous training. This phenomenon, often referred to as catastrophic forgetting, has important potential implications for the safety of deployed models. In this work, we first show that models trained on downstream tasks forget their safety tuning to a greater extent than models trained in the opposite order.Second, we show that forgetting disproportionately impacts safety information about certain groups. To quantify this phenomenon, we define a new metric we term biased forgetting. We conduct a systematic evaluation of the effects of task ordering on forgetting and apply mitigations that can help the model recover from the forgetting observed. We hope our findings can better inform methods for chaining the finetuning of LLMs in continual learning settings to enable training of safer and less toxic models.
RealSeal: Revolutionizing Media Authentication with Real-Time Realism Scoring
Nov 26, 2024
The growing threat of deepfakes and manipulated media necessitates a radical rethinking of media authentication. Existing methods for watermarking synthetic data fall short, as they can be easily removed or altered, and current deepfake detection algorithms do not achieve perfect accuracy. Provenance techniques, which rely on metadata to verify content origin, fail to address the fundamental problem of staged or fake media. This paper introduces a groundbreaking paradigm shift in media authentication by advocating for the watermarking of real content at its source, as opposed to watermarking synthetic data. Our innovative approach employs multisensory inputs and machine learning to assess the realism of content in real-time and across different contexts. We propose embedding a robust realism score within the image metadata, fundamentally transforming how images are trusted and circulated. By combining established principles of human reasoning about reality, rooted in firmware and hardware security, with the sophisticated reasoning capabilities of contemporary machine learning systems, we develop a holistic approach that analyzes information from multiple perspectives. This ambitious, blue sky approach represents a significant leap forward in the field, pushing the boundaries of media authenticity and trust. By embracing cutting-edge advancements in technology and interdisciplinary research, we aim to establish a new standard for verifying the authenticity of digital media.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024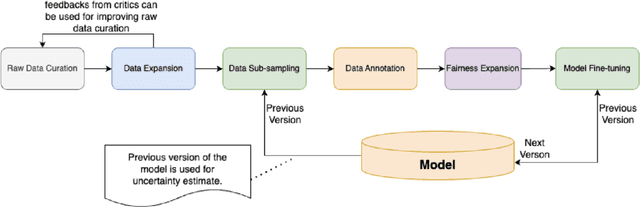
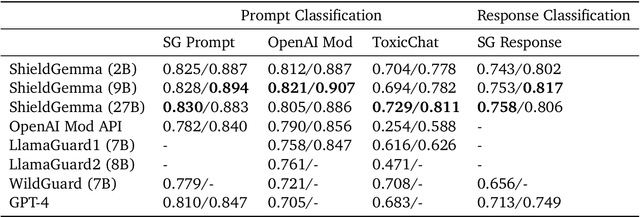

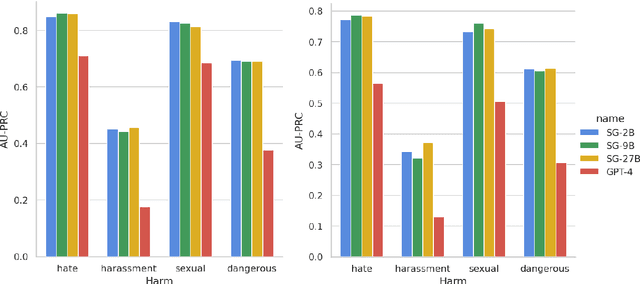
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-powered Applications
Nov 29, 2023Adversarial testing of large language models (LLMs) is crucial for their safe and responsible deployment. We introduce a novel approach for automated generation of adversarial evaluation datasets to test the safety of LLM generations on new downstream applications. We call it AI-assisted Red-Teaming (AART) - an automated alternative to current manual red-teaming efforts. AART offers a data generation and augmentation pipeline of reusable and customizable recipes that reduce human effort significantly and enable integration of adversarial testing earlier in new product development. AART generates evaluation datasets with high diversity of content characteristics critical for effective adversarial testing (e.g. sensitive and harmful concepts, specific to a wide range of cultural and geographic regions and application scenarios). The data generation is steered by AI-assisted recipes to define, scope and prioritize diversity within the application context. This feeds into a structured LLM-generation process that scales up evaluation priorities. Compared to some state-of-the-art tools, AART shows promising results in terms of concept coverage and data quality.
Safety and Fairness for Content Moderation in Generative Models
Jun 09, 2023



With significant advances in generative AI, new technologies are rapidly being deployed with generative components. Generative models are typically trained on large datasets, resulting in model behaviors that can mimic the worst of the content in the training data. Responsible deployment of generative technologies requires content moderation strategies, such as safety input and output filters. Here, we provide a theoretical framework for conceptualizing responsible content moderation of text-to-image generative technologies, including a demonstration of how to empirically measure the constructs we enumerate. We define and distinguish the concepts of safety, fairness, and metric equity, and enumerate example harms that can come in each domain. We then provide a demonstration of how the defined harms can be quantified. We conclude with a summary of how the style of harms quantification we demonstrate enables data-driven content moderation decisions.