 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarm Amplification in Text-to-Image Models
Feb 01, 2024



Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by first introducing a formal definition for this phenomenon, termed harm amplification. We further contribute to the field by developing methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Beyond the Surface: A Global-Scale Analysis of Visual Stereotypes in Text-to-Image Generation
Jan 12, 2024



Recent studies have highlighted the issue of stereotypical depictions for people of different identity groups in Text-to-Image (T2I) model generations. However, these existing approaches have several key limitations, including a noticeable lack of coverage of global identity groups in their evaluation, and the range of their associated stereotypes. Additionally, they often lack a critical distinction between inherently visual stereotypes, such as `underweight' or `sombrero', and culturally dependent stereotypes like `attractive' or `terrorist'. In this work, we address these limitations with a multifaceted approach that leverages existing textual resources to ground our evaluation of geo-cultural stereotypes in the generated images from T2I models. We employ existing stereotype benchmarks to identify and evaluate visual stereotypes at a global scale, spanning 135 nationality-based identity groups. We demonstrate that stereotypical attributes are thrice as likely to be present in images of these identities as compared to other attributes. We further investigate how disparately offensive the depictions of generated images are for different nationalities. Finally, through a detailed case study, we reveal how the 'default' representations of all identity groups have a stereotypical appearance. Moreover, for the Global South, images across different attributes are visually similar, even when explicitly prompted otherwise. CONTENT WARNING: Some examples may contain offensive stereotypes.
"Is a picture of a bird a bird": Policy recommendations for dealing with ambiguity in machine vision models
Jun 27, 2023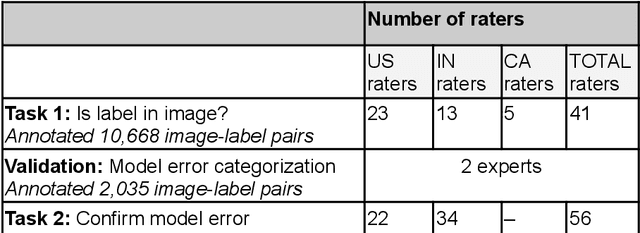
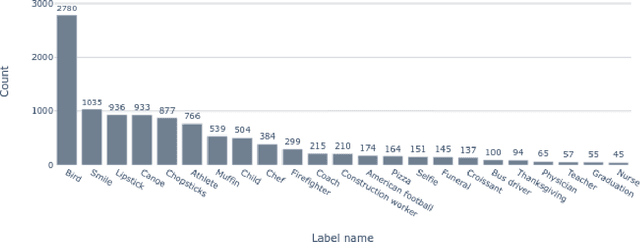


Many questions that we ask about the world do not have a single clear answer, yet typical human annotation set-ups in machine learning assume there must be a single ground truth label for all examples in every task. The divergence between reality and practice is stark, especially in cases with inherent ambiguity and where the range of different subjective judgments is wide. Here, we examine the implications of subjective human judgments in the behavioral task of labeling images used to train machine vision models. We identify three primary sources of ambiguity arising from (i) depictions of labels in the images, (ii) raters' backgrounds, and (iii) the task definition. On the basis of the empirical results, we suggest best practices for handling label ambiguity in machine learning datasets.
Safety and Fairness for Content Moderation in Generative Models
Jun 09, 2023



With significant advances in generative AI, new technologies are rapidly being deployed with generative components. Generative models are typically trained on large datasets, resulting in model behaviors that can mimic the worst of the content in the training data. Responsible deployment of generative technologies requires content moderation strategies, such as safety input and output filters. Here, we provide a theoretical framework for conceptualizing responsible content moderation of text-to-image generative technologies, including a demonstration of how to empirically measure the constructs we enumerate. We define and distinguish the concepts of safety, fairness, and metric equity, and enumerate example harms that can come in each domain. We then provide a demonstration of how the defined harms can be quantified. We conclude with a summary of how the style of harms quantification we demonstrate enables data-driven content moderation decisions.
Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.