 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.
Efficient Full Image Interactive Segmentation by Leveraging Within-image Appearance Similarity
Jul 16, 2020
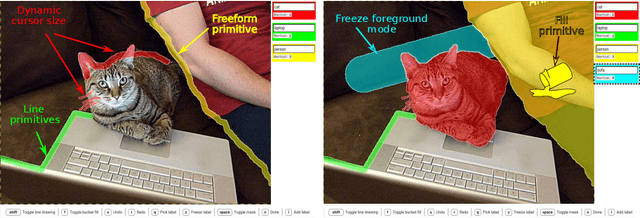

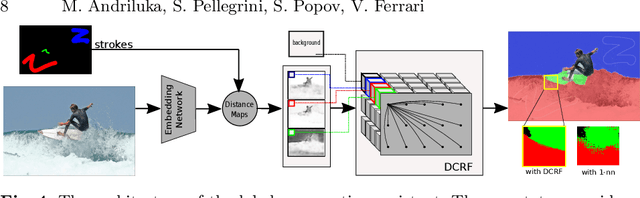
We propose a new approach to interactive full-image semantic segmentation which enables quickly collecting training data for new datasets with previously unseen semantic classes (A demo is available at https://youtu.be/yUk8D5gEX-o). We leverage a key observation: propagation from labeled to unlabeled pixels does not necessarily require class-specific knowledge, but can be done purely based on appearance similarity within an image. We build on this observation and propose an approach capable of jointly propagating pixel labels from multiple classes without having explicit class-specific appearance models. To enable long-range propagation, our approach first globally measures appearance similarity between labeled and unlabeled pixels across the entire image. Then it locally integrates per-pixel measurements which improves the accuracy at boundaries and removes noisy label switches in homogeneous regions. We also design an efficient manual annotation interface that extends the traditional polygon drawing tools with a suite of additional convenient features (and add automatic propagation to it). Experiments with human annotators on the COCO Panoptic Challenge dataset show that the combination of our better manual interface and our novel automatic propagation mechanism leads to reducing annotation time by more than factor of 2x compared to polygon drawing. We also test our method on the ADE-20k and Fashionista datasets without making any dataset-specific adaptation nor retraining our model, demonstrating that it can generalize to new datasets and visual classes.