 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Neural Physics Simulation for Articulated 3D Human Pose Reconstruction
Oct 15, 2024We propose a novel neural network approach, LARP (Learned Articulated Rigid body Physics), to model the dynamics of articulated human motion with contact. Our goal is to develop a faster and more convenient methodological alternative to traditional physics simulators for use in computer vision tasks such as human motion reconstruction from video. To that end we introduce a training procedure and model components that support the construction of a recurrent neural architecture to accurately simulate articulated rigid body dynamics. Our neural architecture supports features typically found in traditional physics simulators, such as modeling of joint motors, variable dimensions of body parts, contact between body parts and objects, and is an order of magnitude faster than traditional systems when multiple simulations are run in parallel. To demonstrate the value of LARP we use it as a drop-in replacement for a state of the art classical non-differentiable simulator in an existing video-based reconstruction framework and show comparative or better 3D human pose reconstruction accuracy.
Transformer-Based Learned Optimization
Dec 02, 2022



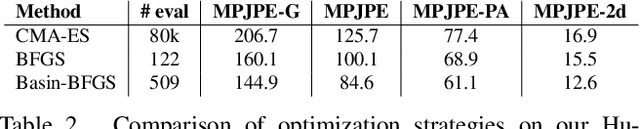
In this paper, we propose a new approach to learned optimization. As common in the literature, we represent the computation of the update step of the optimizer with a neural network. The parameters of the optimizer are then learned on a set of training optimization tasks, in order to perform minimisation efficiently. Our main innovation is to propose a new neural network architecture for the learned optimizer inspired by the classic BFGS algorithm. As in BFGS, we estimate a preconditioning matrix as a sum of rank-one updates but use a transformer-based neural network to predict these updates jointly with the step length and direction. In contrast to several recent learned optimization approaches, our formulation allows for conditioning across different dimensions of the parameter space of the target problem while remaining applicable to optimization tasks of variable dimensionality without retraining. We demonstrate the advantages of our approach on a benchmark composed of objective functions traditionally used for evaluation of optimization algorithms, as well as on the real world-task of physics-based reconstruction of articulated 3D human motion.
Trajectory Optimization for Physics-Based Reconstruction of 3d Human Pose from Monocular Video
May 24, 2022



We focus on the task of estimating a physically plausible articulated human motion from monocular video. Existing approaches that do not consider physics often produce temporally inconsistent output with motion artifacts, while state-of-the-art physics-based approaches have either been shown to work only in controlled laboratory conditions or consider simplified body-ground contact limited to feet. This paper explores how these shortcomings can be addressed by directly incorporating a fully-featured physics engine into the pose estimation process. Given an uncontrolled, real-world scene as input, our approach estimates the ground-plane location and the dimensions of the physical body model. It then recovers the physical motion by performing trajectory optimization. The advantage of our formulation is that it readily generalizes to a variety of scenes that might have diverse ground properties and supports any form of self-contact and contact between the articulated body and scene geometry. We show that our approach achieves competitive results with respect to existing physics-based methods on the Human3.6M benchmark, while being directly applicable without re-training to more complex dynamic motions from the AIST benchmark and to uncontrolled internet videos.
Differentiable Dynamics for Articulated 3d Human Motion Reconstruction
May 24, 2022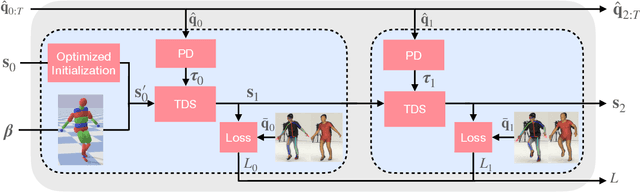

We introduce DiffPhy, a differentiable physics-based model for articulated 3d human motion reconstruction from video. Applications of physics-based reasoning in human motion analysis have so far been limited, both by the complexity of constructing adequate physical models of articulated human motion, and by the formidable challenges of performing stable and efficient inference with physics in the loop. We jointly address such modeling and inference challenges by proposing an approach that combines a physically plausible body representation with anatomical joint limits, a differentiable physics simulator, and optimization techniques that ensure good performance and robustness to suboptimal local optima. In contrast to several recent methods, our approach readily supports full-body contact including interactions with objects in the scene. Most importantly, our model connects end-to-end with images, thus supporting direct gradient-based physics optimization by means of image-based loss functions. We validate the model by demonstrating that it can accurately reconstruct physically plausible 3d human motion from monocular video, both on public benchmarks with available 3d ground-truth, and on videos from the internet.
Efficient Full Image Interactive Segmentation by Leveraging Within-image Appearance Similarity
Jul 16, 2020
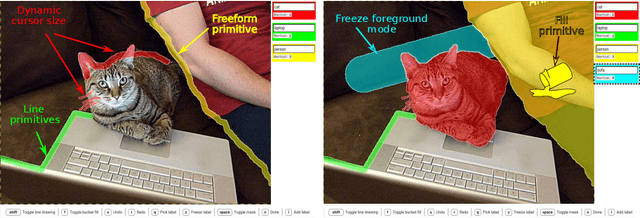

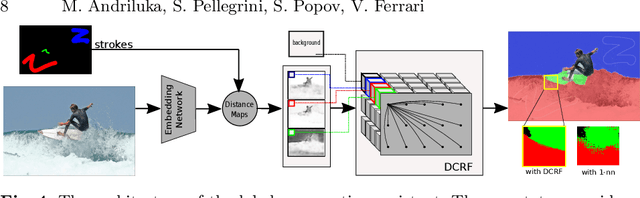
We propose a new approach to interactive full-image semantic segmentation which enables quickly collecting training data for new datasets with previously unseen semantic classes (A demo is available at https://youtu.be/yUk8D5gEX-o). We leverage a key observation: propagation from labeled to unlabeled pixels does not necessarily require class-specific knowledge, but can be done purely based on appearance similarity within an image. We build on this observation and propose an approach capable of jointly propagating pixel labels from multiple classes without having explicit class-specific appearance models. To enable long-range propagation, our approach first globally measures appearance similarity between labeled and unlabeled pixels across the entire image. Then it locally integrates per-pixel measurements which improves the accuracy at boundaries and removes noisy label switches in homogeneous regions. We also design an efficient manual annotation interface that extends the traditional polygon drawing tools with a suite of additional convenient features (and add automatic propagation to it). Experiments with human annotators on the COCO Panoptic Challenge dataset show that the combination of our better manual interface and our novel automatic propagation mechanism leads to reducing annotation time by more than factor of 2x compared to polygon drawing. We also test our method on the ADE-20k and Fashionista datasets without making any dataset-specific adaptation nor retraining our model, demonstrating that it can generalize to new datasets and visual classes.
Panoptic Image Annotation with a Collaborative Assistant
Jun 17, 2019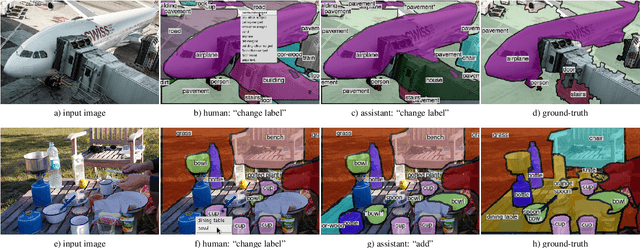
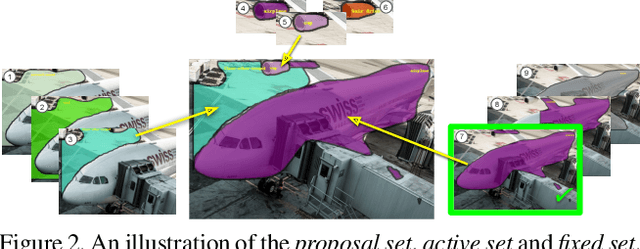
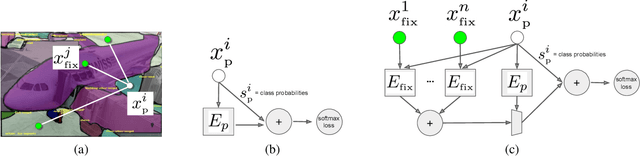
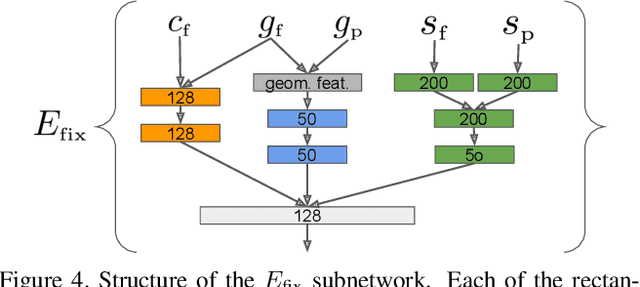
This paper aims to reduce the time to annotate images for the panoptic segmentation task, which requires annotating segmentation masks and class labels for all object instances and stuff regions. We formulate our approach as a collaborative process between an annotator and an automated assistant agent who take turns to jointly annotate an image using a predefined pool of segments. Actions performed by the annotator serve as a strong contextual signal. The assistant intelligently reacts to this signal by anticipating future actions of the annotator, which it then executes on its own. This reduces the amount of work required by the annotator. Experiments on the COCO panoptic dataset [Caesar18cvpr,Kirillov18arxiv,Lin14eccv} demonstrate that our approach is 17%-27% faster than the recent machine-assisted interface of [Andriluka18acmmm]. This corresponds to a 4x speed-up compared to the traditional manual polygon drawing [Russel08ijcv].
Fluid Annotation: A Human-Machine Collaboration Interface for Full Image Annotation
Sep 21, 2018

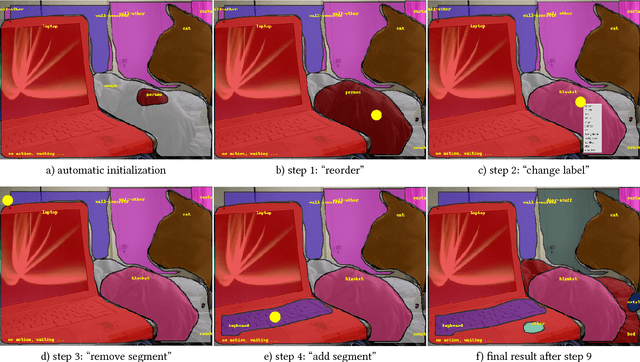
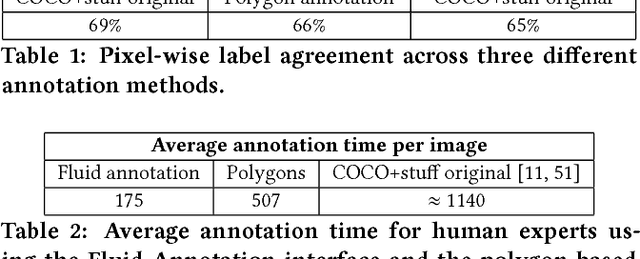
We introduce Fluid Annotation, an intuitive human-machine collaboration interface for annotating the class label and outline of every object and background region in an image. Fluid annotation is based on three principles: (I) Strong Machine-Learning aid. We start from the output of a strong neural network model, which the annotator can edit by correcting the labels of existing regions, adding new regions to cover missing objects, and removing incorrect regions. The edit operations are also assisted by the model. (II) Full image annotation in a single pass. As opposed to performing a series of small annotation tasks in isolation, we propose a unified interface for full image annotation in a single pass. (III) Empower the annotator. We empower the annotator to choose what to annotate and in which order. This enables concentrating on what the machine does not already know, i.e. putting human effort only on the errors it made. This helps using the annotation budget effectively. Through extensive experiments on the COCO+Stuff dataset, we demonstrate that Fluid Annotation leads to accurate annotations very efficiently, taking three times less annotation time than the popular LabelMe interface.
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Apr 10, 2018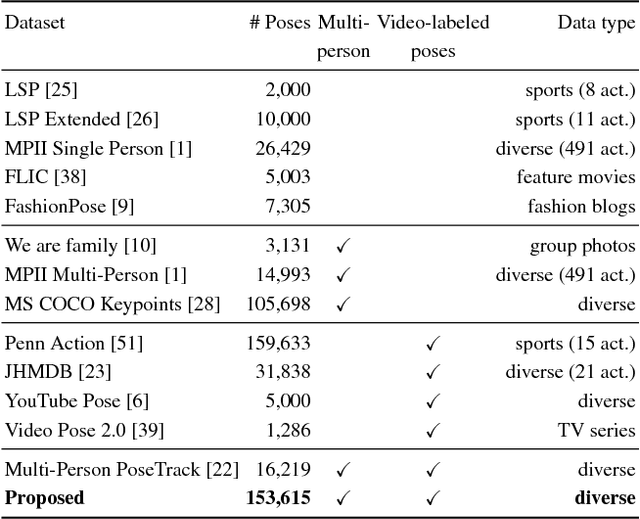


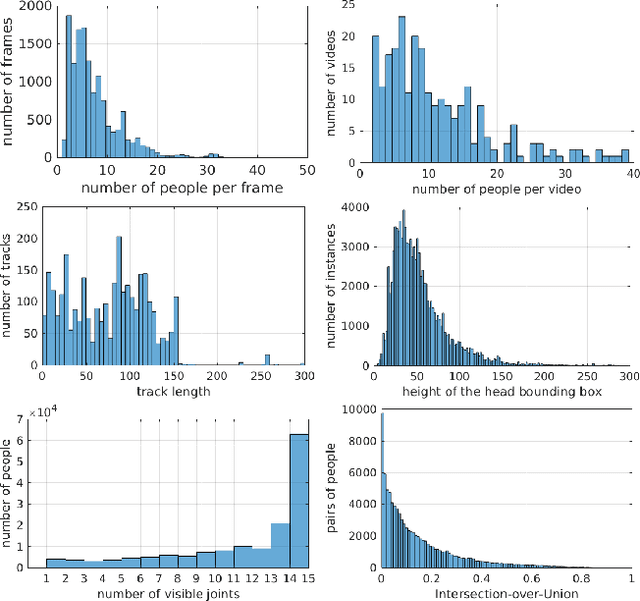
Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack", a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at https://posetrack.net.
Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos
Jun 09, 2017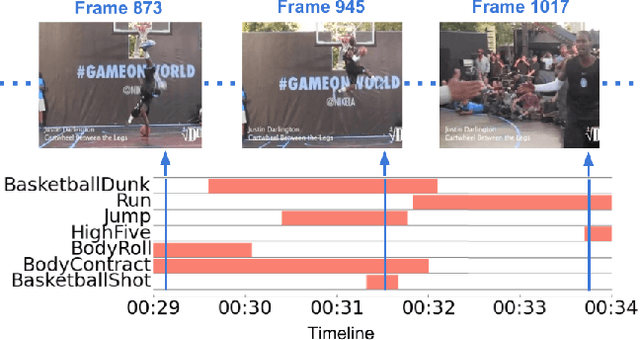
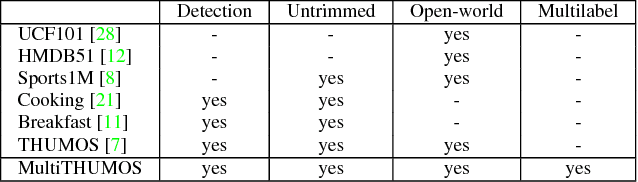

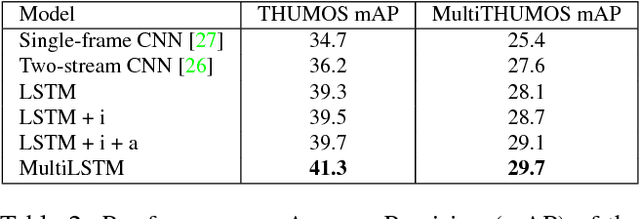
Every moment counts in action recognition. A comprehensive understanding of human activity in video requires labeling every frame according to the actions occurring, placing multiple labels densely over a video sequence. To study this problem we extend the existing THUMOS dataset and introduce MultiTHUMOS, a new dataset of dense labels over unconstrained internet videos. Modeling multiple, dense labels benefits from temporal relations within and across classes. We define a novel variant of long short-term memory (LSTM) deep networks for modeling these temporal relations via multiple input and output connections. We show that this model improves action labeling accuracy and further enables deeper understanding tasks ranging from structured retrieval to action prediction.
ArtTrack: Articulated Multi-person Tracking in the Wild
May 09, 2017
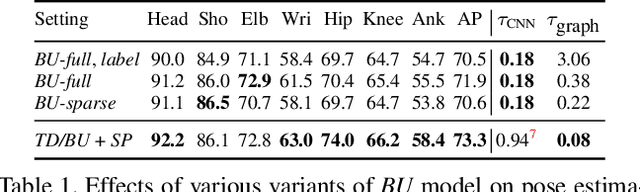
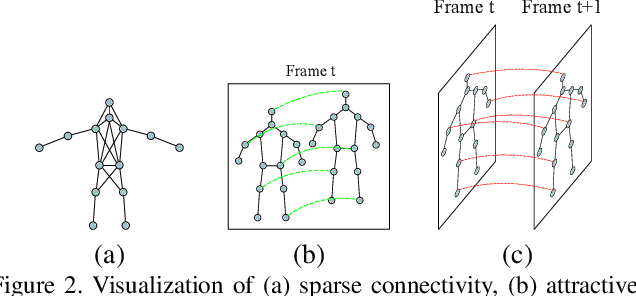
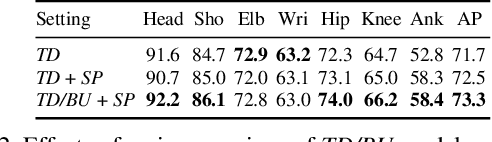
In this paper we propose an approach for articulated tracking of multiple people in unconstrained videos. Our starting point is a model that resembles existing architectures for single-frame pose estimation but is substantially faster. We achieve this in two ways: (1) by simplifying and sparsifying the body-part relationship graph and leveraging recent methods for faster inference, and (2) by offloading a substantial share of computation onto a feed-forward convolutional architecture that is able to detect and associate body joints of the same person even in clutter. We use this model to generate proposals for body joint locations and formulate articulated tracking as spatio-temporal grouping of such proposals. This allows to jointly solve the association problem for all people in the scene by propagating evidence from strong detections through time and enforcing constraints that each proposal can be assigned to one person only. We report results on a public MPII Human Pose benchmark and on a new MPII Video Pose dataset of image sequences with multiple people. We demonstrate that our model achieves state-of-the-art results while using only a fraction of time and is able to leverage temporal information to improve state-of-the-art for crowded scenes.