 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Image Annotation with a Collaborative Assistant
Jun 17, 2019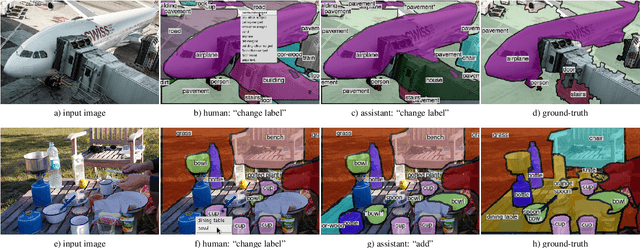
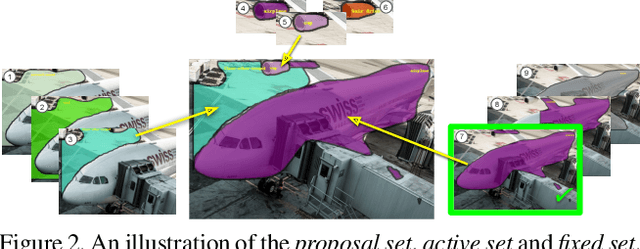
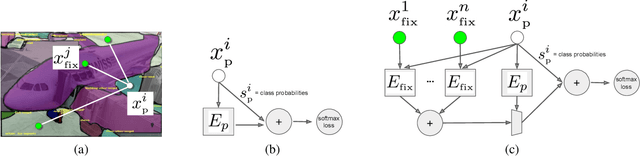
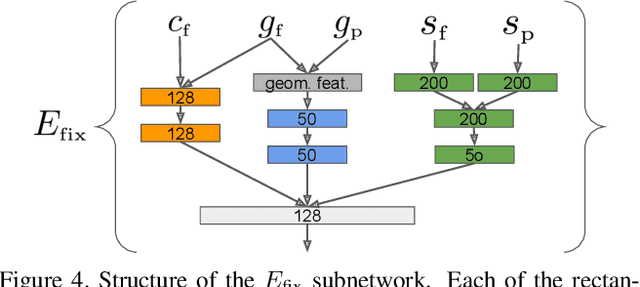
This paper aims to reduce the time to annotate images for the panoptic segmentation task, which requires annotating segmentation masks and class labels for all object instances and stuff regions. We formulate our approach as a collaborative process between an annotator and an automated assistant agent who take turns to jointly annotate an image using a predefined pool of segments. Actions performed by the annotator serve as a strong contextual signal. The assistant intelligently reacts to this signal by anticipating future actions of the annotator, which it then executes on its own. This reduces the amount of work required by the annotator. Experiments on the COCO panoptic dataset [Caesar18cvpr,Kirillov18arxiv,Lin14eccv} demonstrate that our approach is 17%-27% faster than the recent machine-assisted interface of [Andriluka18acmmm]. This corresponds to a 4x speed-up compared to the traditional manual polygon drawing [Russel08ijcv].
Interactive Full Image Segmentation
Dec 05, 2018
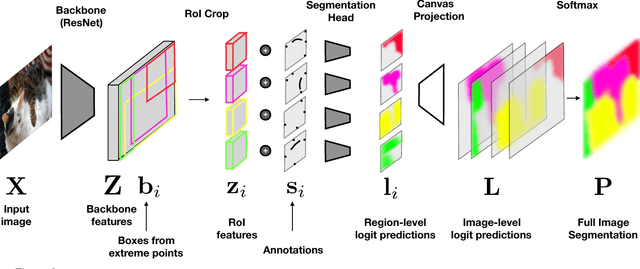

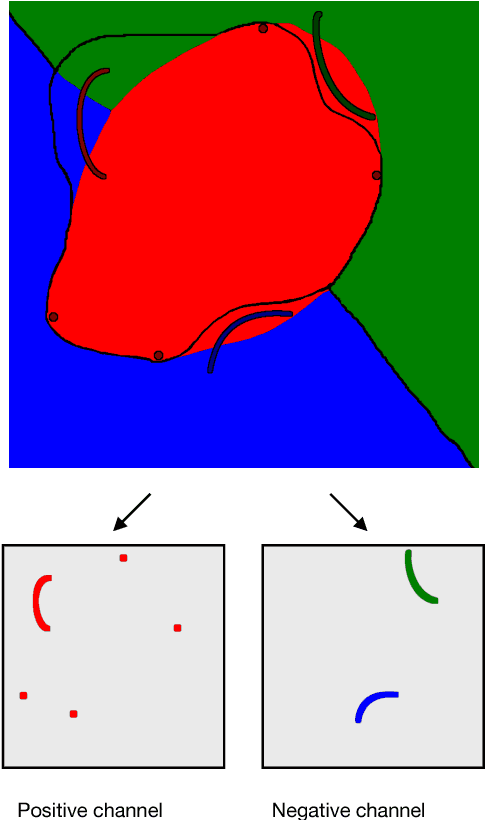
We address the task of interactive full image annotation, where the goal is to produce accurate segmentations for all object and stuff regions in an image. To this end we propose an interactive, scribble-based annotation framework which operates on the whole image to produce segmentations for all regions. This enables the annotator to focus on the largest errors made by the machine across the whole image, and to share corrections across nearby regions. Furthermore, we adapt Mask-RCNN into a fast interactive segmentation framework and introduce a new instance-aware loss measured at the pixel-level in the full image canvas, which lets predictions for nearby regions properly compete. Finally, we compare to interactive single object segmentation on the on the COCO panoptic dataset. We demonstrate that, at a budget of four extreme clicks and four corrective scribbles per region, our interactive full image segmentation approach leads to a 5% IoU gain, reaching 90% IoU.
Fluid Annotation: A Human-Machine Collaboration Interface for Full Image Annotation
Sep 21, 2018

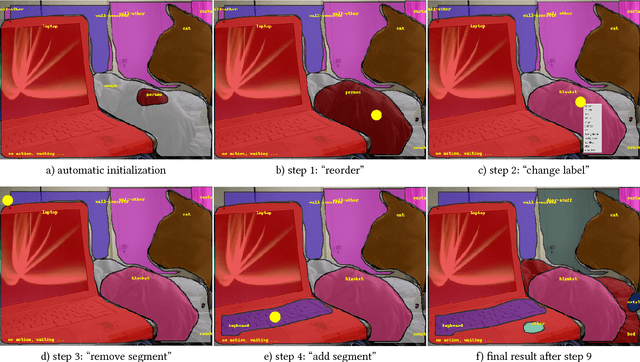
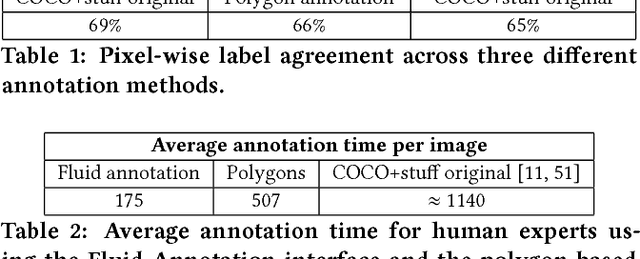
We introduce Fluid Annotation, an intuitive human-machine collaboration interface for annotating the class label and outline of every object and background region in an image. Fluid annotation is based on three principles: (I) Strong Machine-Learning aid. We start from the output of a strong neural network model, which the annotator can edit by correcting the labels of existing regions, adding new regions to cover missing objects, and removing incorrect regions. The edit operations are also assisted by the model. (II) Full image annotation in a single pass. As opposed to performing a series of small annotation tasks in isolation, we propose a unified interface for full image annotation in a single pass. (III) Empower the annotator. We empower the annotator to choose what to annotate and in which order. This enables concentrating on what the machine does not already know, i.e. putting human effort only on the errors it made. This helps using the annotation budget effectively. Through extensive experiments on the COCO+Stuff dataset, we demonstrate that Fluid Annotation leads to accurate annotations very efficiently, taking three times less annotation time than the popular LabelMe interface.
Extreme clicking for efficient object annotation
Aug 09, 2017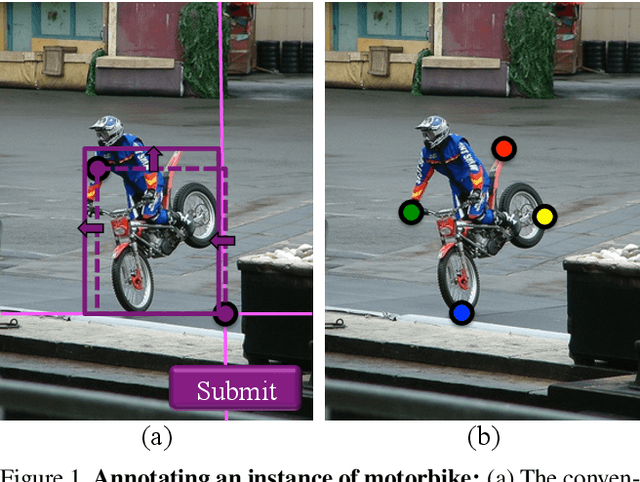
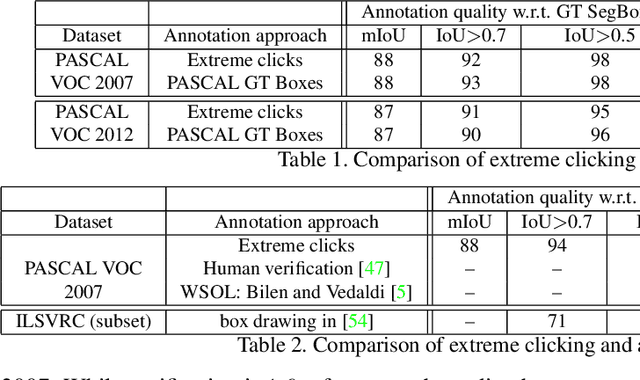
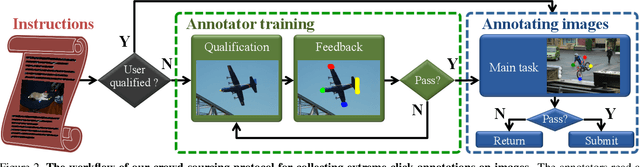
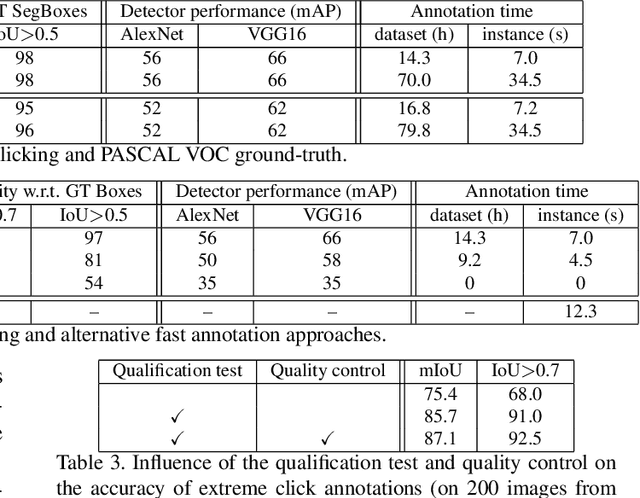
Manually annotating object bounding boxes is central to building computer vision datasets, and it is very time consuming (annotating ILSVRC [53] took 35s for one high-quality box [62]). It involves clicking on imaginary corners of a tight box around the object. This is difficult as these corners are often outside the actual object and several adjustments are required to obtain a tight box. We propose extreme clicking instead: we ask the annotator to click on four physical points on the object: the top, bottom, left- and right-most points. This task is more natural and these points are easy to find. We crowd-source extreme point annotations for PASCAL VOC 2007 and 2012 and show that (1) annotation time is only 7s per box, 5x faster than the traditional way of drawing boxes [62]; (2) the quality of the boxes is as good as the original ground-truth drawn the traditional way; (3) detectors trained on our annotations are as accurate as those trained on the original ground-truth. Moreover, our extreme clicking strategy not only yields box coordinates, but also four accurate boundary points. We show (4) how to incorporate them into GrabCut to obtain more accurate segmentations than those delivered when initializing it from bounding boxes; (5) semantic segmentations models trained on these segmentations outperform those trained on segmentations derived from bounding boxes.
Training object class detectors with click supervision
May 19, 2017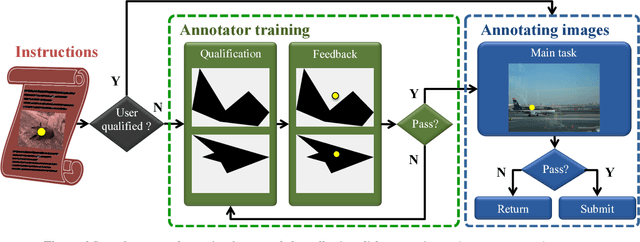


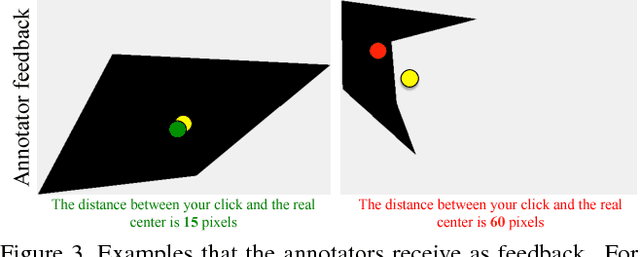
Training object class detectors typically requires a large set of images with objects annotated by bounding boxes. However, manually drawing bounding boxes is very time consuming. In this paper we greatly reduce annotation time by proposing center-click annotations: we ask annotators to click on the center of an imaginary bounding box which tightly encloses the object instance. We then incorporate these clicks into existing Multiple Instance Learning techniques for weakly supervised object localization, to jointly localize object bounding boxes over all training images. Extensive experiments on PASCAL VOC 2007 and MS COCO show that: (1) our scheme delivers high-quality detectors, performing substantially better than those produced by weakly supervised techniques, with a modest extra annotation effort; (2) these detectors in fact perform in a range close to those trained from manually drawn bounding boxes; (3) as the center-click task is very fast, our scheme reduces total annotation time by 9x to 18x.
We don't need no bounding-boxes: Training object class detectors using only human verification
Apr 24, 2017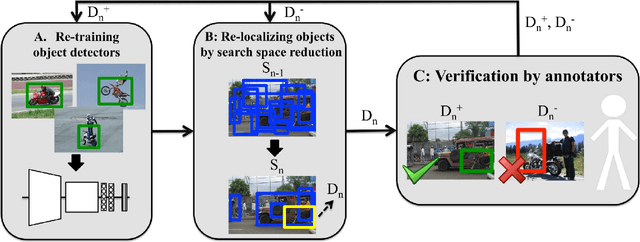



Training object class detectors typically requires a large set of images in which objects are annotated by bounding-boxes. However, manually drawing bounding-boxes is very time consuming. We propose a new scheme for training object detectors which only requires annotators to verify bounding-boxes produced automatically by the learning algorithm. Our scheme iterates between re-training the detector, re-localizing objects in the training images, and human verification. We use the verification signal both to improve re-training and to reduce the search space for re-localisation, which makes these steps different to what is normally done in a weakly supervised setting. Extensive experiments on PASCAL VOC 2007 show that (1) using human verification to update detectors and reduce the search space leads to the rapid production of high-quality bounding-box annotations; (2) our scheme delivers detectors performing almost as good as those trained in a fully supervised setting, without ever drawing any bounding-box; (3) as the verification task is very quick, our scheme substantially reduces total annotation time by a factor 6x-9x.