 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Transformer Variational Autoencoders for Multi-Action Motion Synthesis
Jun 14, 2022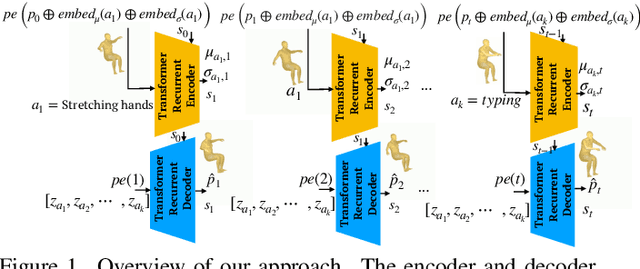
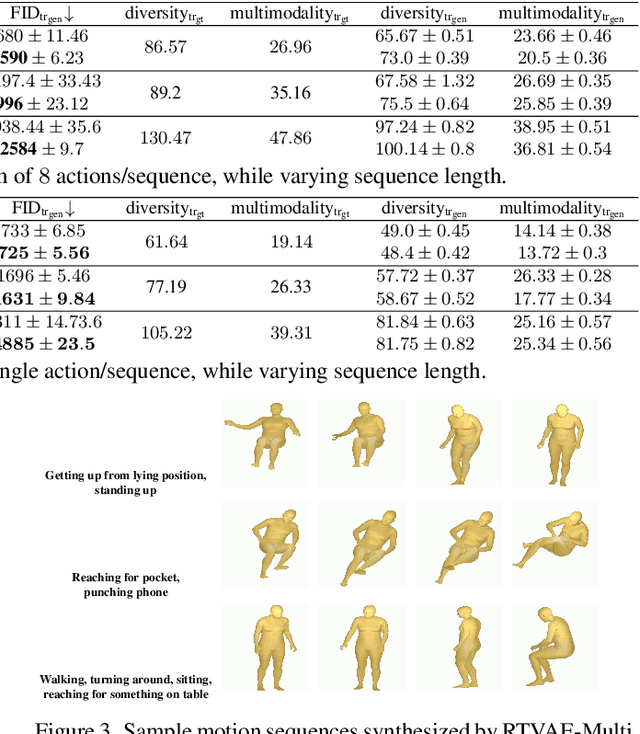
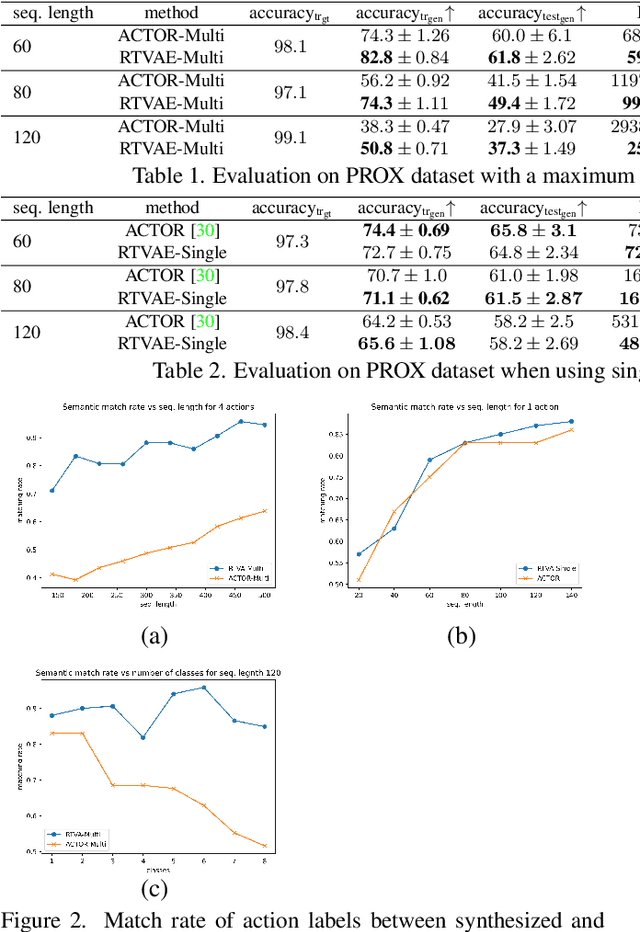

We consider the problem of synthesizing multi-action human motion sequences of arbitrary lengths. Existing approaches have mastered motion sequence generation in single-action scenarios, but fail to generalize to multi-action and arbitrary-length sequences. We fill this gap by proposing a novel efficient approach that leverages the expressiveness of Recurrent Transformers and generative richness of conditional Variational Autoencoders. The proposed iterative approach is able to generate smooth and realistic human motion sequences with an arbitrary number of actions and frames while doing so in linear space and time. We train and evaluate the proposed approach on PROX dataset which we augment with ground-truth action labels. Experimental evaluation shows significant improvements in FID score and semantic consistency metrics compared to the state-of-the-art.
AOWS: Adaptive and optimal network width search with latency constraints
May 21, 2020
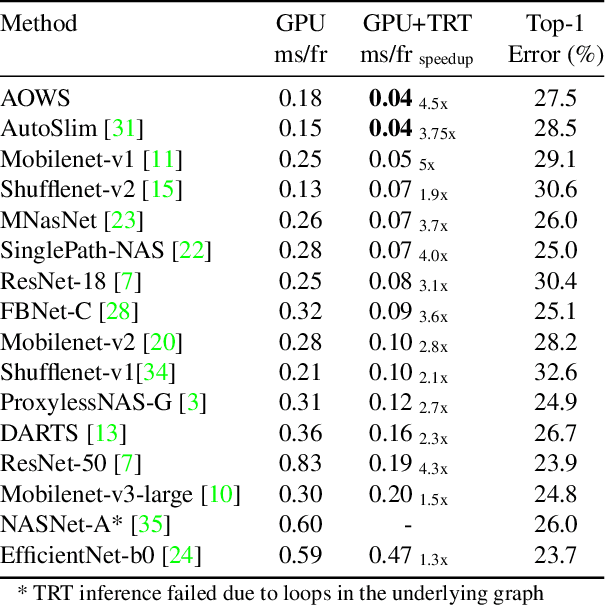
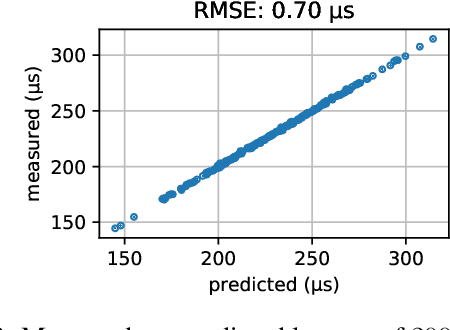
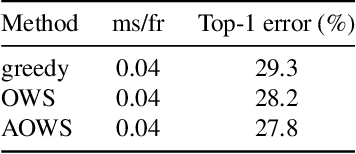
Neural architecture search (NAS) approaches aim at automatically finding novel CNN architectures that fit computational constraints while maintaining a good performance on the target platform. We introduce a novel efficient one-shot NAS approach to optimally search for channel numbers, given latency constraints on a specific hardware. We first show that we can use a black-box approach to estimate a realistic latency model for a specific inference platform, without the need for low-level access to the inference computation. Then, we design a pairwise MRF to score any channel configuration and use dynamic programming to efficiently decode the best performing configuration, yielding an optimal solution for the network width search. Finally, we propose an adaptive channel configuration sampling scheme to gradually specialize the training phase to the target computational constraints. Experiments on ImageNet classification show that our approach can find networks fitting the resource constraints on different target platforms while improving accuracy over the state-of-the-art efficient networks.
Learning to Refine Human Pose Estimation
Apr 21, 2018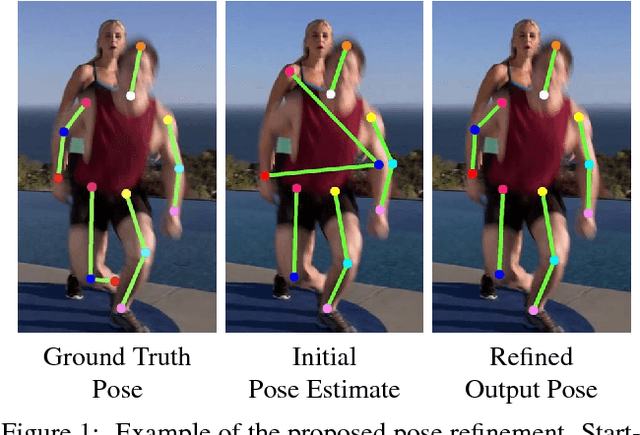
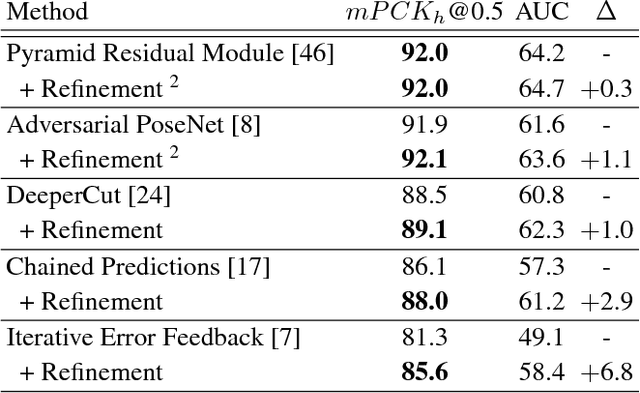
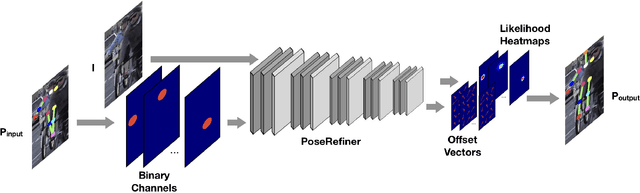
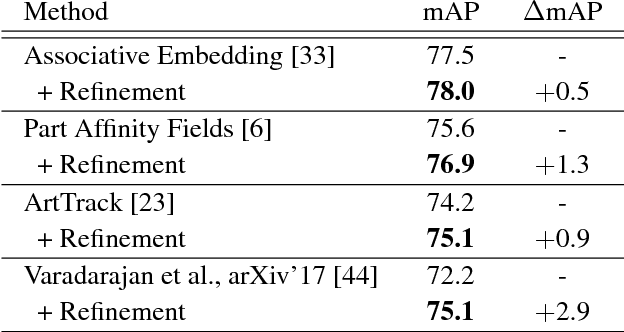
Multi-person pose estimation in images and videos is an important yet challenging task with many applications. Despite the large improvements in human pose estimation enabled by the development of convolutional neural networks, there still exist a lot of difficult cases where even the state-of-the-art models fail to correctly localize all body joints. This motivates the need for an additional refinement step that addresses these challenging cases and can be easily applied on top of any existing method. In this work, we introduce a pose refinement network (PoseRefiner) which takes as input both the image and a given pose estimate and learns to directly predict a refined pose by jointly reasoning about the input-output space. In order for the network to learn to refine incorrect body joint predictions, we employ a novel data augmentation scheme for training, where we model "hard" human pose cases. We evaluate our approach on four popular large-scale pose estimation benchmarks such as MPII Single- and Multi-Person Pose Estimation, PoseTrack Pose Estimation, and PoseTrack Pose Tracking, and report systematic improvement over the state of the art.
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Apr 10, 2018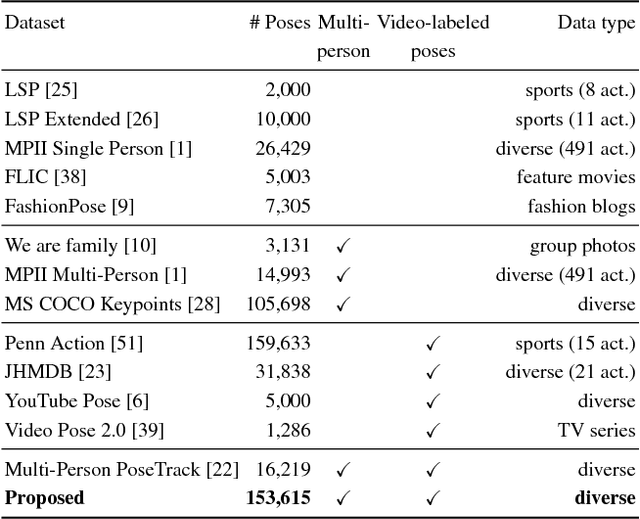


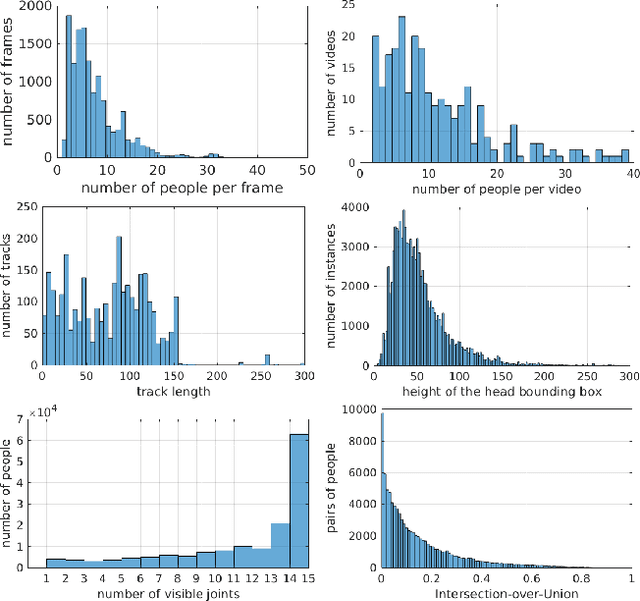
Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack", a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at https://posetrack.net.
ArtTrack: Articulated Multi-person Tracking in the Wild
May 09, 2017
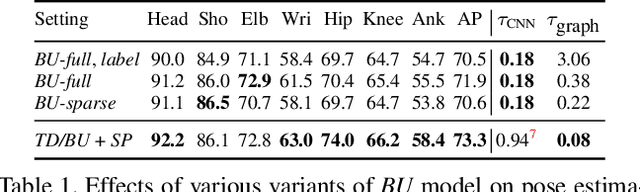
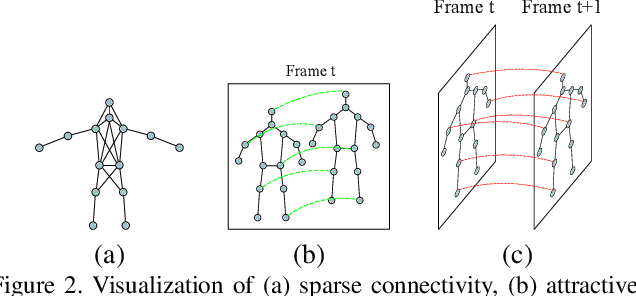
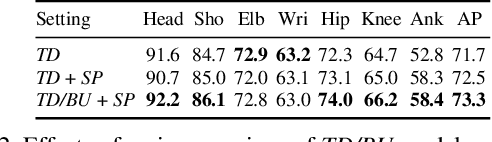
In this paper we propose an approach for articulated tracking of multiple people in unconstrained videos. Our starting point is a model that resembles existing architectures for single-frame pose estimation but is substantially faster. We achieve this in two ways: (1) by simplifying and sparsifying the body-part relationship graph and leveraging recent methods for faster inference, and (2) by offloading a substantial share of computation onto a feed-forward convolutional architecture that is able to detect and associate body joints of the same person even in clutter. We use this model to generate proposals for body joint locations and formulate articulated tracking as spatio-temporal grouping of such proposals. This allows to jointly solve the association problem for all people in the scene by propagating evidence from strong detections through time and enforcing constraints that each proposal can be assigned to one person only. We report results on a public MPII Human Pose benchmark and on a new MPII Video Pose dataset of image sequences with multiple people. We demonstrate that our model achieves state-of-the-art results while using only a fraction of time and is able to leverage temporal information to improve state-of-the-art for crowded scenes.
Building Statistical Shape Spaces for 3D Human Modeling
Mar 03, 2017
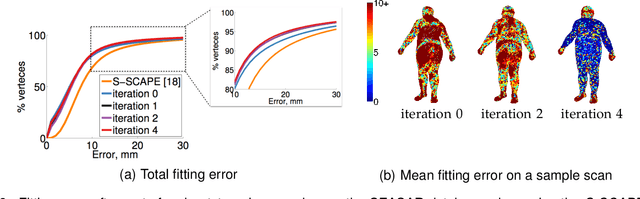
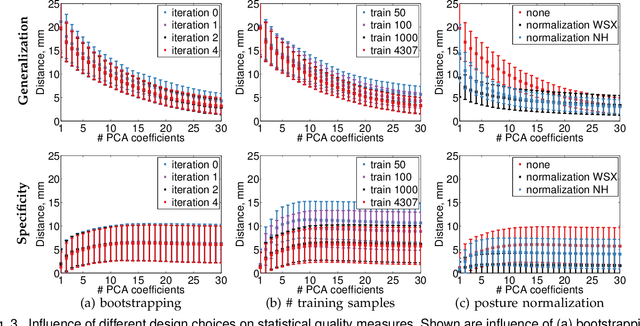
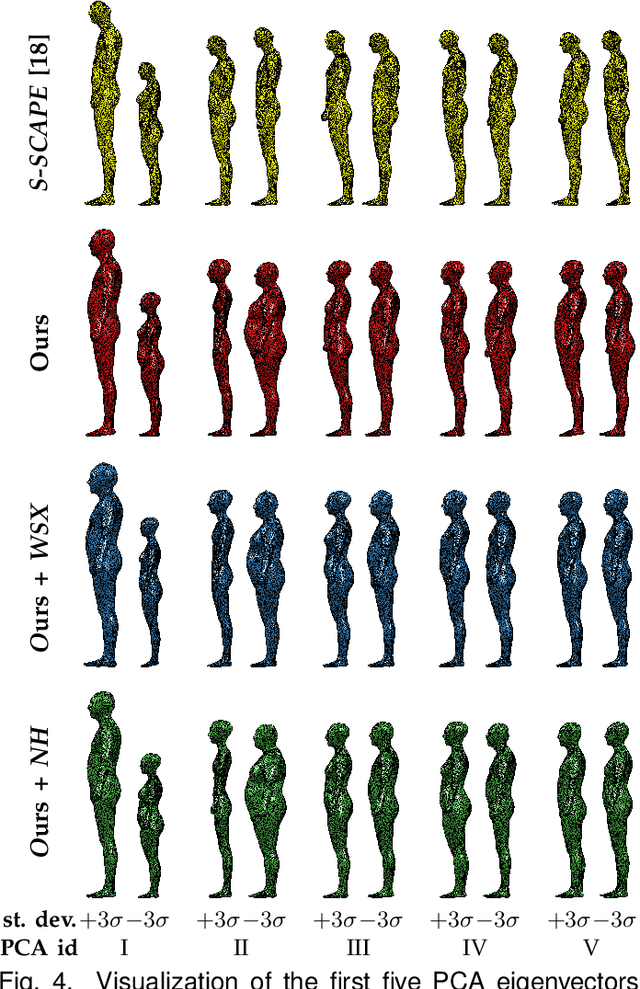
Statistical models of 3D human shape and pose learned from scan databases have developed into valuable tools to solve a variety of vision and graphics problems. Unfortunately, most publicly available models are of limited expressiveness as they were learned on very small databases that hardly reflect the true variety in human body shapes. In this paper, we contribute by rebuilding a widely used statistical body representation from the largest commercially available scan database, and making the resulting model available to the community (visit http://humanshape.mpi-inf.mpg.de). As preprocessing several thousand scans for learning the model is a challenge in itself, we contribute by developing robust best practice solutions for scan alignment that quantitatively lead to the best learned models. We make implementations of these preprocessing steps also publicly available. We extensively evaluate the improved accuracy and generality of our new model, and show its improved performance for human body reconstruction from sparse input data.
DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model
Nov 30, 2016
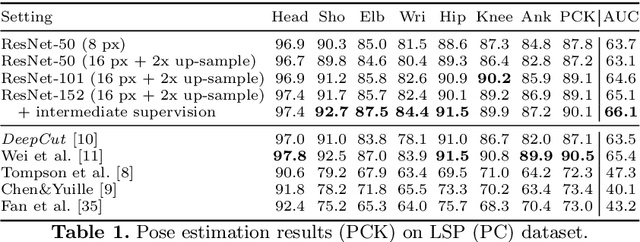
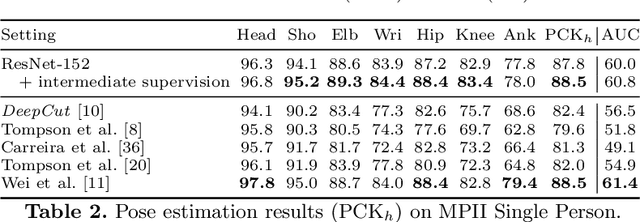

The goal of this paper is to advance the state-of-the-art of articulated pose estimation in scenes with multiple people. To that end we contribute on three fronts. We propose (1) improved body part detectors that generate effective bottom-up proposals for body parts; (2) novel image-conditioned pairwise terms that allow to assemble the proposals into a variable number of consistent body part configurations; and (3) an incremental optimization strategy that explores the search space more efficiently thus leading both to better performance and significant speed-up factors. Evaluation is done on two single-person and two multi-person pose estimation benchmarks. The proposed approach significantly outperforms best known multi-person pose estimation results while demonstrating competitive performance on the task of single person pose estimation. Models and code available at http://pose.mpi-inf.mpg.de
DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
Apr 26, 2016
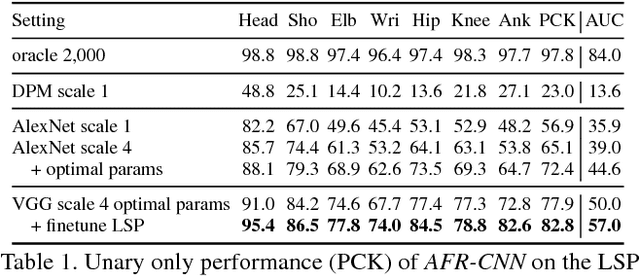
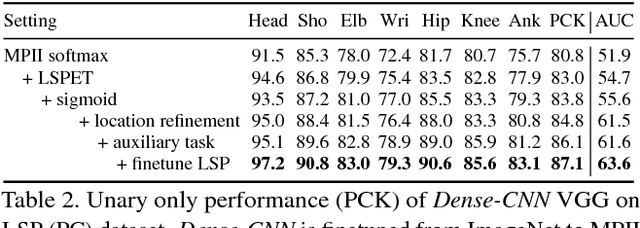
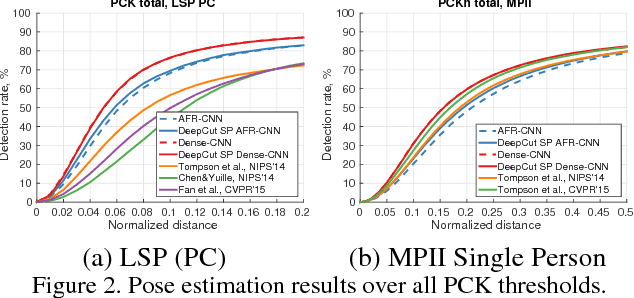
This paper considers the task of articulated human pose estimation of multiple people in real world images. We propose an approach that jointly solves the tasks of detection and pose estimation: it infers the number of persons in a scene, identifies occluded body parts, and disambiguates body parts between people in close proximity of each other. This joint formulation is in contrast to previous strategies, that address the problem by first detecting people and subsequently estimating their body pose. We propose a partitioning and labeling formulation of a set of body-part hypotheses generated with CNN-based part detectors. Our formulation, an instance of an integer linear program, implicitly performs non-maximum suppression on the set of part candidates and groups them to form configurations of body parts respecting geometric and appearance constraints. Experiments on four different datasets demonstrate state-of-the-art results for both single person and multi person pose estimation. Models and code available at http://pose.mpi-inf.mpg.de.
Fine-grained Activity Recognition with Holistic and Pose based Features
Jul 28, 2014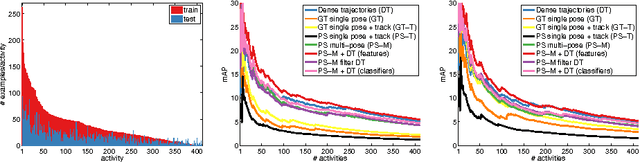
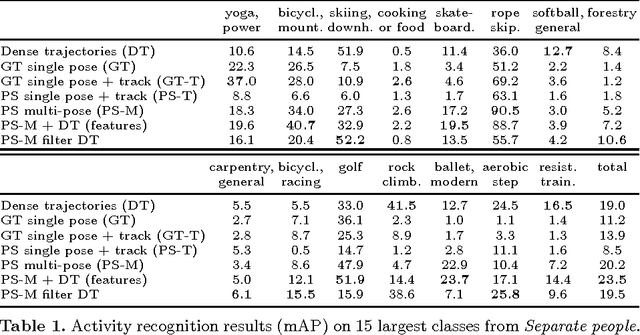
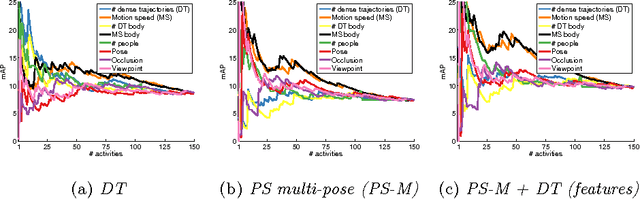

Holistic methods based on dense trajectories are currently the de facto standard for recognition of human activities in video. Whether holistic representations will sustain or will be superseded by higher level video encoding in terms of body pose and motion is the subject of an ongoing debate. In this paper we aim to clarify the underlying factors responsible for good performance of holistic and pose-based representations. To that end we build on our recent dataset leveraging the existing taxonomy of human activities. This dataset includes 24,920 video snippets covering 410 human activities in total. Our analysis reveals that holistic and pose-based methods are highly complementary, and their performance varies significantly depending on the activity. We find that holistic methods are mostly affected by the number and speed of trajectories, whereas pose-based methods are mostly influenced by viewpoint of the person. We observe striking performance differences across activities: for certain activities results with pose-based features are more than twice as accurate compared to holistic features, and vice versa. The best performing approach in our comparison is based on the combination of holistic and pose-based approaches, which again underlines their complementarity.
Estimation of Human Body Shape and Posture Under Clothing
Jun 26, 2014

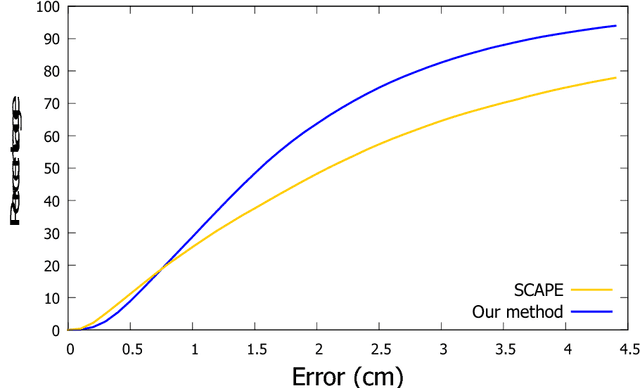

Estimating the body shape and posture of a dressed human subject in motion represented as a sequence of (possibly incomplete) 3D meshes is important for virtual change rooms and security. To solve this problem, statistical shape spaces encoding human body shape and posture variations are commonly used to constrain the search space for the shape estimate. In this work, we propose a novel method that uses a posture-invariant shape space to model body shape variation combined with a skeleton-based deformation to model posture variation. Our method can estimate the body shape and posture of both static scans and motion sequences of dressed human body scans. In case of motion sequences, our method takes advantage of motion cues to solve for a single body shape estimate along with a sequence of posture estimates. We apply our approach to both static scans and motion sequences and demonstrate that using our method, higher fitting accuracy is achieved than when using a variant of the popular SCAPE model as statistical model.
* 23 pages, 11 figures