 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeST: Test-time Self-Training under Distribution Shift
Sep 23, 2022
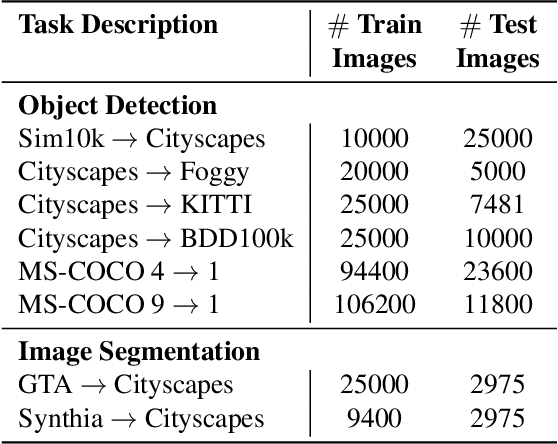
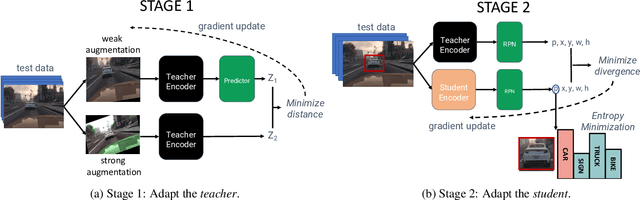
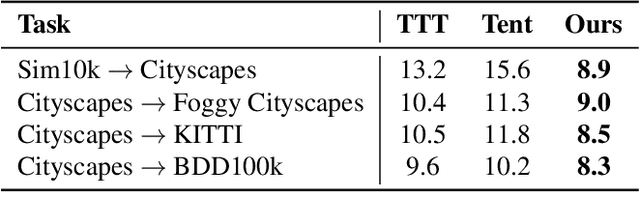
Despite their recent success, deep neural networks continue to perform poorly when they encounter distribution shifts at test time. Many recently proposed approaches try to counter this by aligning the model to the new distribution prior to inference. With no labels available this requires unsupervised objectives to adapt the model on the observed test data. In this paper, we propose Test-Time Self-Training (TeST): a technique that takes as input a model trained on some source data and a novel data distribution at test time, and learns invariant and robust representations using a student-teacher framework. We find that models adapted using TeST significantly improve over baseline test-time adaptation algorithms. TeST achieves competitive performance to modern domain adaptation algorithms, while having access to 5-10x less data at time of adaption. We thoroughly evaluate a variety of baselines on two tasks: object detection and image segmentation and find that models adapted with TeST. We find that TeST sets the new state-of-the art for test-time domain adaptation algorithms.
Unsupervised Object Learning via Common Fate
Oct 13, 2021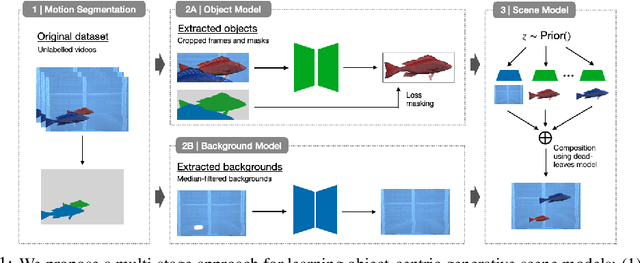
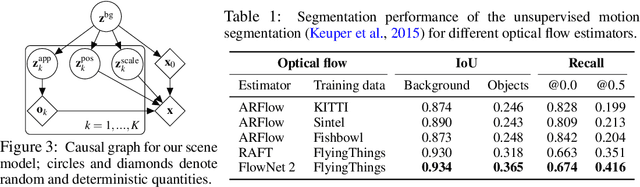

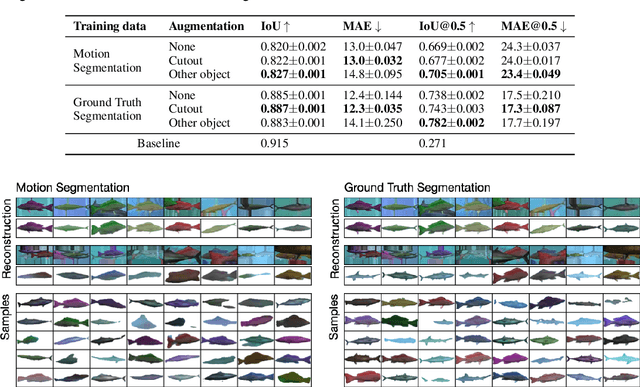
Learning generative object models from unlabelled videos is a long standing problem and required for causal scene modeling. We decompose this problem into three easier subtasks, and provide candidate solutions for each of them. Inspired by the Common Fate Principle of Gestalt Psychology, we first extract (noisy) masks of moving objects via unsupervised motion segmentation. Second, generative models are trained on the masks of the background and the moving objects, respectively. Third, background and foreground models are combined in a conditional "dead leaves" scene model to sample novel scene configurations where occlusions and depth layering arise naturally. To evaluate the individual stages, we introduce the Fishbowl dataset positioned between complex real-world scenes and common object-centric benchmarks of simplistic objects. We show that our approach allows learning generative models that generalize beyond the occlusions present in the input videos, and represent scenes in a modular fashion that allows sampling plausible scenes outside the training distribution by permitting, for instance, object numbers or densities not observed in the training set.
Dynamic Inference with Neural Interpreters
Oct 12, 2021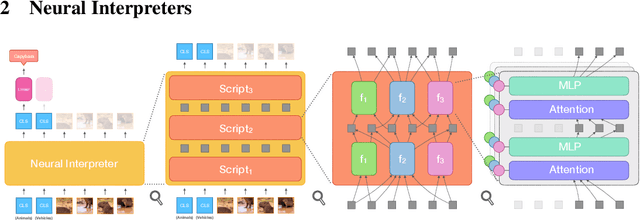
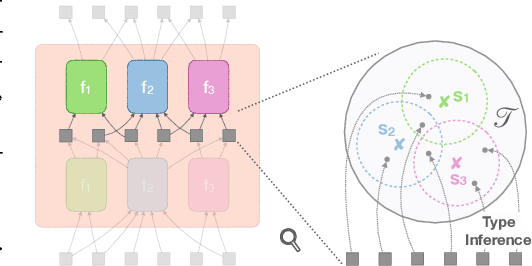
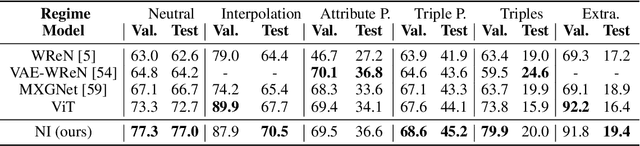
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
You Mostly Walk Alone: Analyzing Feature Attribution in Trajectory Prediction
Oct 11, 2021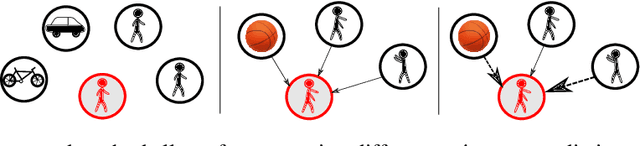
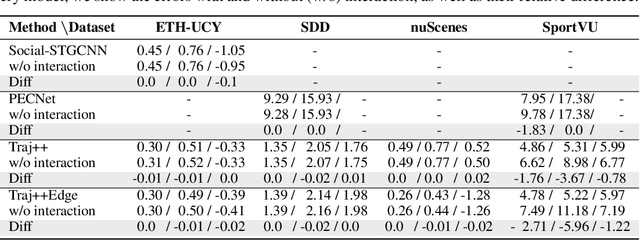

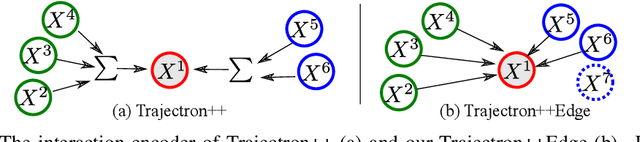
Predicting the future trajectory of a moving agent can be easy when the past trajectory continues smoothly but is challenging when complex interactions with other agents are involved. Recent deep learning approaches for trajectory prediction show promising performance and partially attribute this to successful reasoning about agent-agent interactions. However, it remains unclear which features such black-box models actually learn to use for making predictions. This paper proposes a procedure that quantifies the contributions of different cues to model performance based on a variant of Shapley values. Applying this procedure to state-of-the-art trajectory prediction methods on standard benchmark datasets shows that they are, in fact, unable to reason about interactions. Instead, the past trajectory of the target is the only feature used for predicting its future. For a task with richer social interaction patterns, on the other hand, the tested models do pick up such interactions to a certain extent, as quantified by our feature attribution method. We discuss the limits of the proposed method and its links to causality
CrossCLR: Cross-modal Contrastive Learning For Multi-modal Video Representations
Sep 30, 2021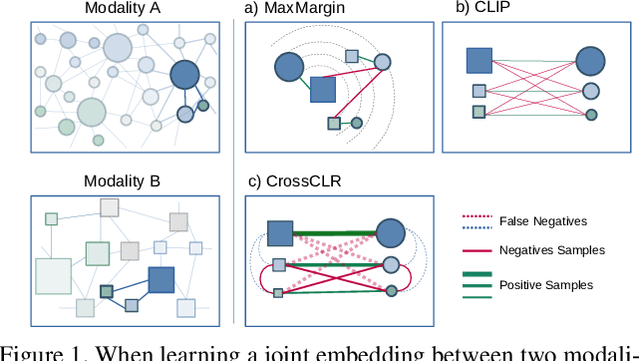

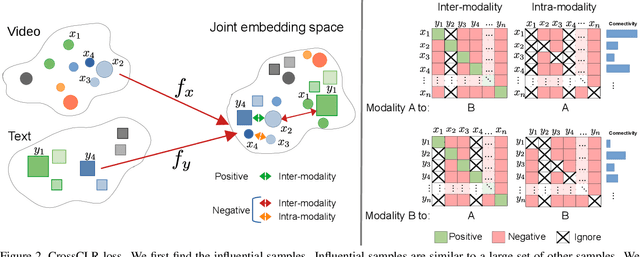

Contrastive learning allows us to flexibly define powerful losses by contrasting positive pairs from sets of negative samples. Recently, the principle has also been used to learn cross-modal embeddings for video and text, yet without exploiting its full potential. In particular, previous losses do not take the intra-modality similarities into account, which leads to inefficient embeddings, as the same content is mapped to multiple points in the embedding space. With CrossCLR, we present a contrastive loss that fixes this issue. Moreover, we define sets of highly related samples in terms of their input embeddings and exclude them from the negative samples to avoid issues with false negatives. We show that these principles consistently improve the quality of the learned embeddings. The joint embeddings learned with CrossCLR extend the state of the art in video-text retrieval on Youcook2 and LSMDC datasets and in video captioning on Youcook2 dataset by a large margin. We also demonstrate the generality of the concept by learning improved joint embeddings for other pairs of modalities.
Visual Representation Learning Does Not Generalize Strongly Within the Same Domain
Jul 23, 2021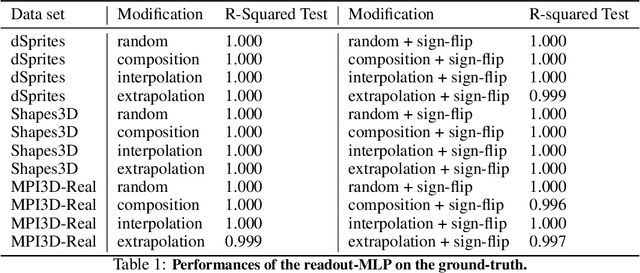



An important component for generalization in machine learning is to uncover underlying latent factors of variation as well as the mechanism through which each factor acts in the world. In this paper, we test whether 17 unsupervised, weakly supervised, and fully supervised representation learning approaches correctly infer the generative factors of variation in simple datasets (dSprites, Shapes3D, MPI3D). In contrast to prior robustness work that introduces novel factors of variation during test time, such as blur or other (un)structured noise, we here recompose, interpolate, or extrapolate only existing factors of variation from the training data set (e.g., small and medium-sized objects during training and large objects during testing). Models that learn the correct mechanism should be able to generalize to this benchmark. In total, we train and test 2000+ models and observe that all of them struggle to learn the underlying mechanism regardless of supervision signal and architectural bias. Moreover, the generalization capabilities of all tested models drop significantly as we move from artificial datasets towards more realistic real-world datasets. Despite their inability to identify the correct mechanism, the models are quite modular as their ability to infer other in-distribution factors remains fairly stable, providing only a single factor is out-of-distribution. These results point to an important yet understudied problem of learning mechanistic models of observations that can facilitate generalization.
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021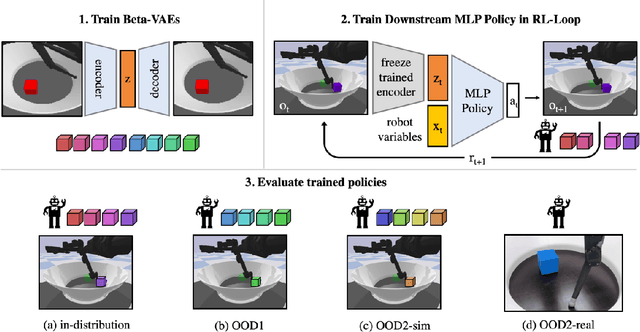
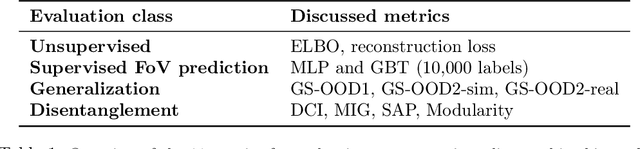
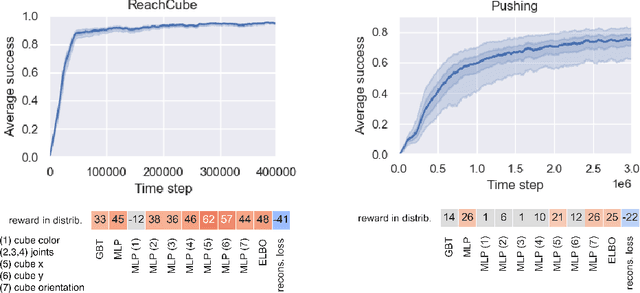
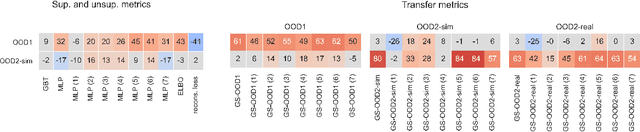
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.
Backward-Compatible Prediction Updates: A Probabilistic Approach
Jul 02, 2021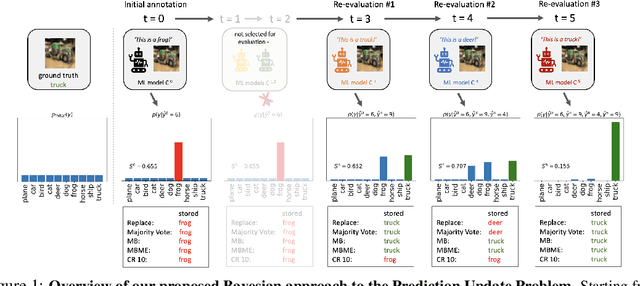
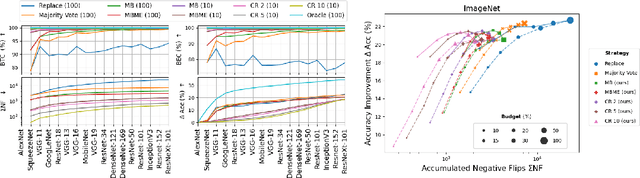
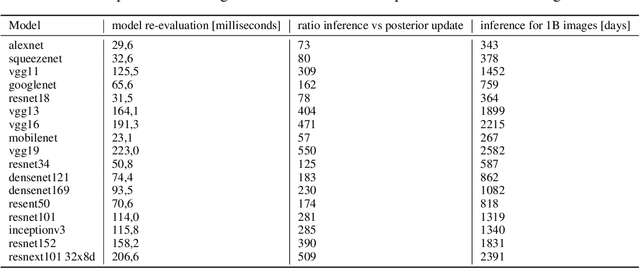
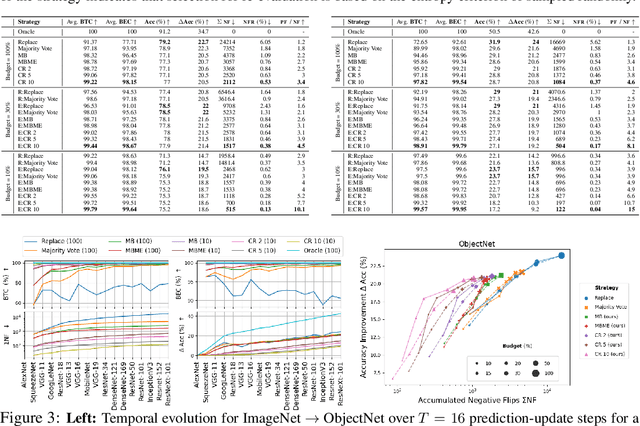
When machine learning systems meet real world applications, accuracy is only one of several requirements. In this paper, we assay a complementary perspective originating from the increasing availability of pre-trained and regularly improving state-of-the-art models. While new improved models develop at a fast pace, downstream tasks vary more slowly or stay constant. Assume that we have a large unlabelled data set for which we want to maintain accurate predictions. Whenever a new and presumably better ML models becomes available, we encounter two problems: (i) given a limited budget, which data points should be re-evaluated using the new model?; and (ii) if the new predictions differ from the current ones, should we update? Problem (i) is about compute cost, which matters for very large data sets and models. Problem (ii) is about maintaining consistency of the predictions, which can be highly relevant for downstream applications; our demand is to avoid negative flips, i.e., changing correct to incorrect predictions. In this paper, we formalize the Prediction Update Problem and present an efficient probabilistic approach as answer to the above questions. In extensive experiments on standard classification benchmark data sets, we show that our method outperforms alternative strategies along key metrics for backward-compatible prediction updates.
Towards Total Recall in Industrial Anomaly Detection
Jun 15, 2021

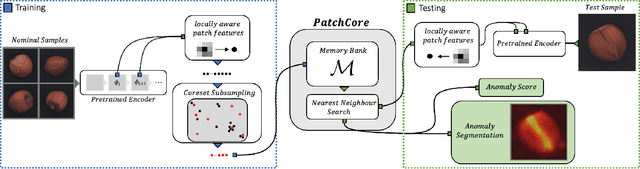
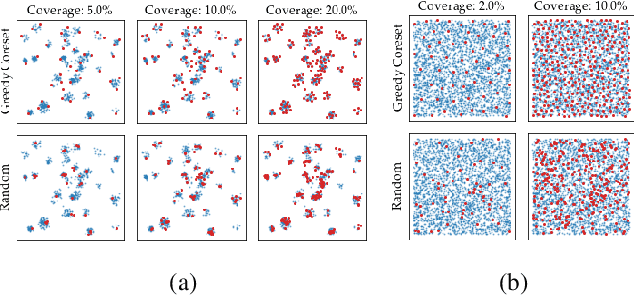
Being able to spot defective parts is a critical component in large-scale industrial manufacturing. A particular challenge that we address in this work is the cold-start problem: fit a model using nominal (non-defective) example images only. While handcrafted solutions per class are possible, the goal is to build systems that work well simultaneously on many different tasks automatically. The best peforming approaches combine embeddings from ImageNet models with an outlier detection model. In this paper, we extend on this line of work and propose PatchCore, which uses a maximally representative memory bank of nominal patch-features. PatchCore offers competitive inference times while achieving state-of-the-art performance for both detection and localization. On the standard dataset MVTec AD, PatchCore achieves an image-level anomaly detection AUROC score of $99.1\%$, more than halving the error compared to the next best competitor. We further report competitive results on two additional datasets and also find competitive results in the few samples regime.
Adapting ImageNet-scale models to complex distribution shifts with self-learning
Apr 28, 2021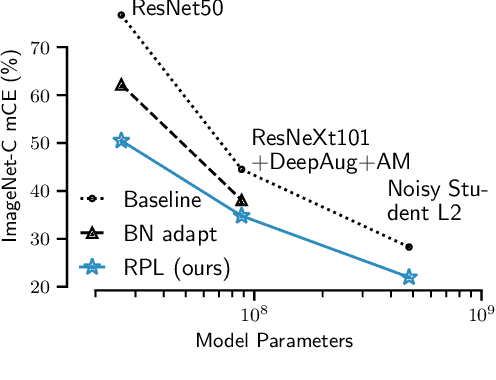

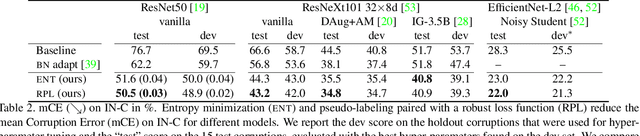
While self-learning methods are an important component in many recent domain adaptation techniques, they are not yet comprehensively evaluated on ImageNet-scale datasets common in robustness research. In extensive experiments on ResNet and EfficientNet models, we find that three components are crucial for increasing performance with self-learning: (i) using short update times between the teacher and the student network, (ii) fine-tuning only few affine parameters distributed across the network, and (iii) leveraging methods from robust classification to counteract the effect of label noise. We use these insights to obtain drastically improved state-of-the-art results on ImageNet-C (22.0% mCE), ImageNet-R (17.4% error) and ImageNet-A (14.8% error). Our techniques yield further improvements in combination with previously proposed robustification methods. Self-learning is able to reduce the top-1 error to a point where no substantial further progress can be expected. We therefore re-purpose the dataset from the Visual Domain Adaptation Challenge 2019 and use a subset of it as a new robustness benchmark (ImageNet-D) which proves to be a more challenging dataset for all current state-of-the-art models (58.2% error) to guide future research efforts at the intersection of robustness and domain adaptation on ImageNet scale.