 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptScope: Characterizing Dataset Bias via Disentangled Visual Concepts
Oct 30, 2025Dataset bias, where data points are skewed to certain concepts, is ubiquitous in machine learning datasets. Yet, systematically identifying these biases is challenging without costly, fine-grained attribute annotations. We present ConceptScope, a scalable and automated framework for analyzing visual datasets by discovering and quantifying human-interpretable concepts using Sparse Autoencoders trained on representations from vision foundation models. ConceptScope categorizes concepts into target, context, and bias types based on their semantic relevance and statistical correlation to class labels, enabling class-level dataset characterization, bias identification, and robustness evaluation through concept-based subgrouping. We validate that ConceptScope captures a wide range of visual concepts, including objects, textures, backgrounds, facial attributes, emotions, and actions, through comparisons with annotated datasets. Furthermore, we show that concept activations produce spatial attributions that align with semantically meaningful image regions. ConceptScope reliably detects known biases (e.g., background bias in Waterbirds) and uncovers previously unannotated ones (e.g, co-occurring objects in ImageNet), offering a practical tool for dataset auditing and model diagnostics.
Equivariance by Contrast: Identifiable Equivariant Embeddings from Unlabeled Finite Group Actions
Oct 24, 2025We propose Equivariance by Contrast (EbC) to learn equivariant embeddings from observation pairs $(\mathbf{y}, g \cdot \mathbf{y})$, where $g$ is drawn from a finite group acting on the data. Our method jointly learns a latent space and a group representation in which group actions correspond to invertible linear maps -- without relying on group-specific inductive biases. We validate our approach on the infinite dSprites dataset with structured transformations defined by the finite group $G:= (R_m \times \mathbb{Z}_n \times \mathbb{Z}_n)$, combining discrete rotations and periodic translations. The resulting embeddings exhibit high-fidelity equivariance, with group operations faithfully reproduced in latent space. On synthetic data, we further validate the approach on the non-abelian orthogonal group $O(n)$ and the general linear group $GL(n)$. We also provide a theoretical proof for identifiability. While broad evaluation across diverse group types on real-world data remains future work, our results constitute the first successful demonstration of general-purpose encoder-only equivariant learning from group action observations alone, including non-trivial non-abelian groups and a product group motivated by modeling affine equivariances in computer vision.
CytoSAE: Interpretable Cell Embeddings for Hematology
Jul 16, 2025



Sparse autoencoders (SAEs) emerged as a promising tool for mechanistic interpretability of transformer-based foundation models. Very recently, SAEs were also adopted for the visual domain, enabling the discovery of visual concepts and their patch-wise attribution to tokens in the transformer model. While a growing number of foundation models emerged for medical imaging, tools for explaining their inferences are still lacking. In this work, we show the applicability of SAEs for hematology. We propose CytoSAE, a sparse autoencoder which is trained on over 40,000 peripheral blood single-cell images. CytoSAE generalizes to diverse and out-of-domain datasets, including bone marrow cytology, where it identifies morphologically relevant concepts which we validated with medical experts. Furthermore, we demonstrate scenarios in which CytoSAE can generate patient-specific and disease-specific concepts, enabling the detection of pathognomonic cells and localized cellular abnormalities at the patch level. We quantified the effect of concepts on a patient-level AML subtype classification task and show that CytoSAE concepts reach performance comparable to the state-of-the-art, while offering explainability on the sub-cellular level. Source code and model weights are available at https://github.com/dynamical-inference/cytosae.
Time-series attribution maps with regularized contrastive learning
Feb 17, 2025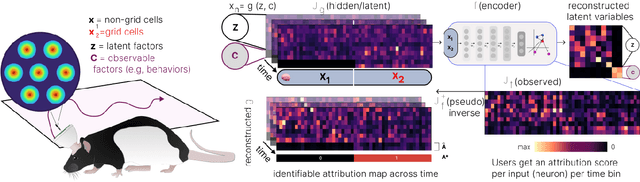
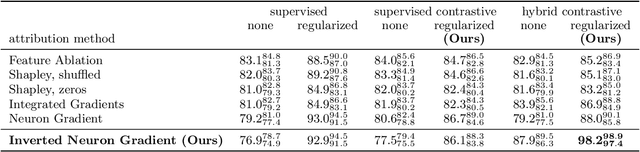
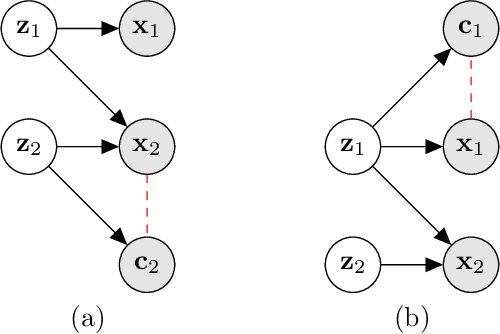
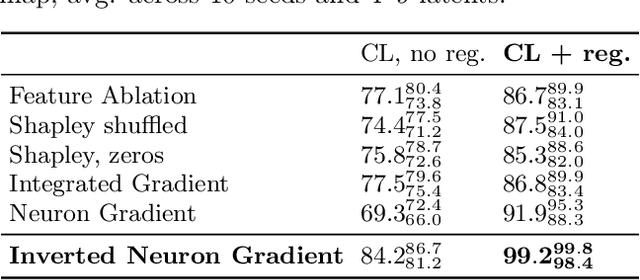
Gradient-based attribution methods aim to explain decisions of deep learning models but so far lack identifiability guarantees. Here, we propose a method to generate attribution maps with identifiability guarantees by developing a regularized contrastive learning algorithm trained on time-series data plus a new attribution method called Inverted Neuron Gradient (collectively named xCEBRA). We show theoretically that xCEBRA has favorable properties for identifying the Jacobian matrix of the data generating process. Empirically, we demonstrate robust approximation of zero vs. non-zero entries in the ground-truth attribution map on synthetic datasets, and significant improvements across previous attribution methods based on feature ablation, Shapley values, and other gradient-based methods. Our work constitutes a first example of identifiable inference of time-series attribution maps and opens avenues to a better understanding of time-series data, such as for neural dynamics and decision-processes within neural networks.
* Accepted at The 28th International Conference on Artificial Intelligence and Statistics (AISTATS 2025). Code is available at https://github.com/AdaptiveMotorControlLab/CEBRA
Sparse autoencoders reveal selective remapping of visual concepts during adaptation
Dec 06, 2024



Adapting foundation models for specific purposes has become a standard approach to build machine learning systems for downstream applications. Yet, it is an open question which mechanisms take place during adaptation. Here we develop a new Sparse Autoencoder (SAE) for the CLIP vision transformer, named PatchSAE, to extract interpretable concepts at granular levels (e.g. shape, color, or semantics of an object) and their patch-wise spatial attributions. We explore how these concepts influence the model output in downstream image classification tasks and investigate how recent state-of-the-art prompt-based adaptation techniques change the association of model inputs to these concepts. While activations of concepts slightly change between adapted and non-adapted models, we find that the majority of gains on common adaptation tasks can be explained with the existing concepts already present in the non-adapted foundation model. This work provides a concrete framework to train and use SAEs for Vision Transformers and provides insights into explaining adaptation mechanisms.
Self-supervised contrastive learning performs non-linear system identification
Oct 18, 2024Self-supervised learning (SSL) approaches have brought tremendous success across many tasks and domains. It has been argued that these successes can be attributed to a link between SSL and identifiable representation learning: Temporal structure and auxiliary variables ensure that latent representations are related to the true underlying generative factors of the data. Here, we deepen this connection and show that SSL can perform system identification in latent space. We propose DynCL, a framework to uncover linear, switching linear and non-linear dynamics under a non-linear observation model, give theoretical guarantees and validate them empirically.
RDumb: A simple approach that questions our progress in continual test-time adaptation
Jun 08, 2023



Test-Time Adaptation (TTA) allows to update pretrained models to changing data distributions at deployment time. While early work tested these algorithms for individual fixed distribution shifts, recent work proposed and applied methods for continual adaptation over long timescales. To examine the reported progress in the field, we propose the Continuously Changing Corruptions (CCC) benchmark to measure asymptotic performance of TTA techniques. We find that eventually all but one state-of-the-art methods collapse and perform worse than a non-adapting model, including models specifically proposed to be robust to performance collapse. In addition, we introduce a simple baseline, "RDumb", that periodically resets the model to its pretrained state. RDumb performs better or on par with the previously proposed state-of-the-art in all considered benchmarks. Our results show that previous TTA approaches are neither effective at regularizing adaptation to avoid collapse nor able to outperform a simplistic resetting strategy.
Learnable latent embeddings for joint behavioral and neural analysis
Apr 01, 2022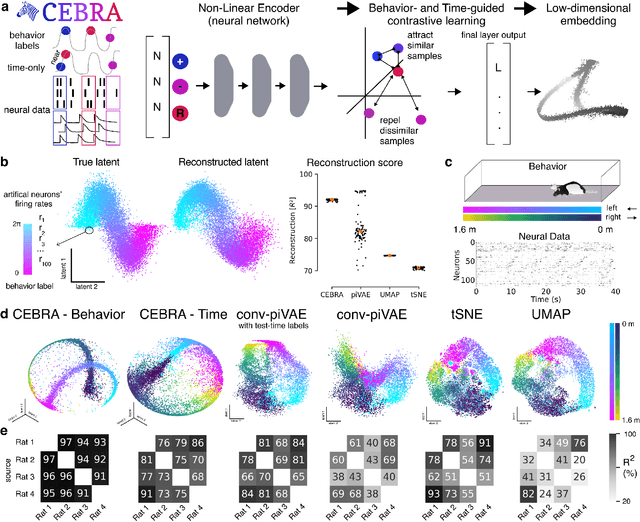
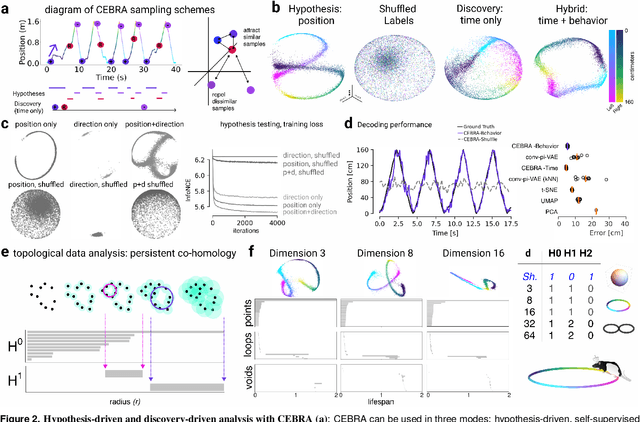
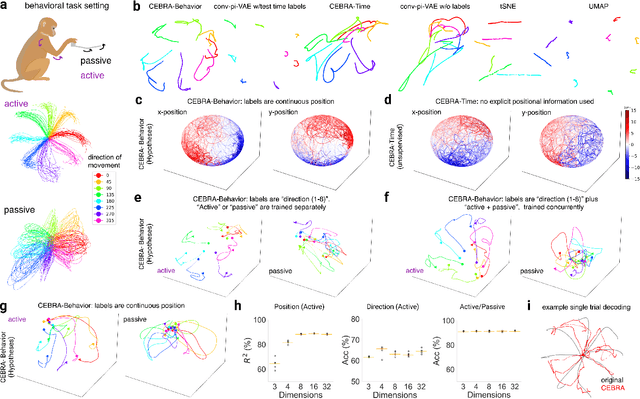
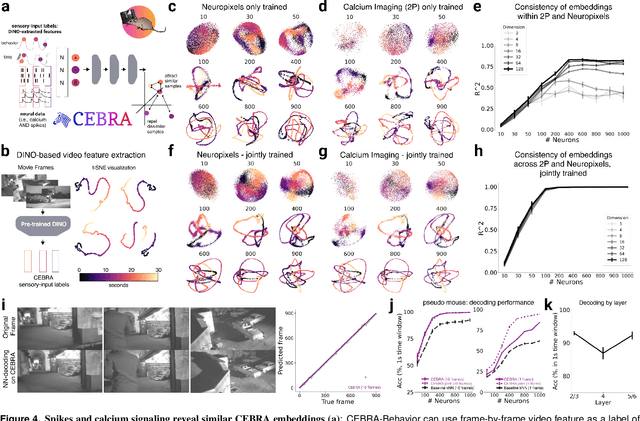
Mapping behavioral actions to neural activity is a fundamental goal of neuroscience. As our ability to record large neural and behavioral data increases, there is growing interest in modeling neural dynamics during adaptive behaviors to probe neural representations. In particular, neural latent embeddings can reveal underlying correlates of behavior, yet, we lack non-linear techniques that can explicitly and flexibly leverage joint behavior and neural data. Here, we fill this gap with a novel method, CEBRA, that jointly uses behavioral and neural data in a hypothesis- or discovery-driven manner to produce consistent, high-performance latent spaces. We validate its accuracy and demonstrate our tool's utility for both calcium and electrophysiology datasets, across sensory and motor tasks, and in simple or complex behaviors across species. It allows for single and multi-session datasets to be leveraged for hypothesis testing or can be used label-free. Lastly, we show that CEBRA can be used for the mapping of space, uncovering complex kinematic features, and rapid, high-accuracy decoding of natural movies from visual cortex.
Unsupervised Object Learning via Common Fate
Oct 13, 2021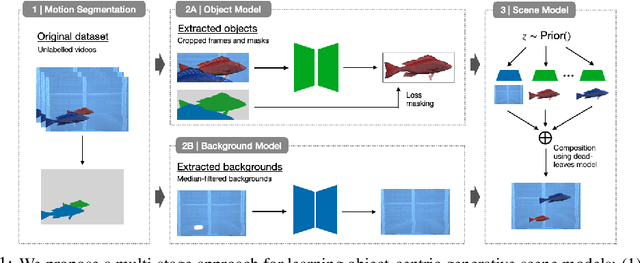
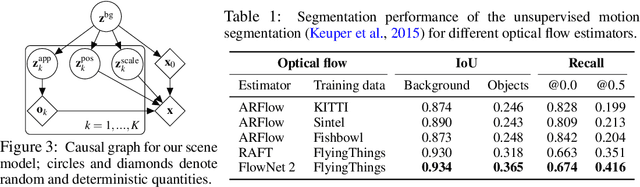

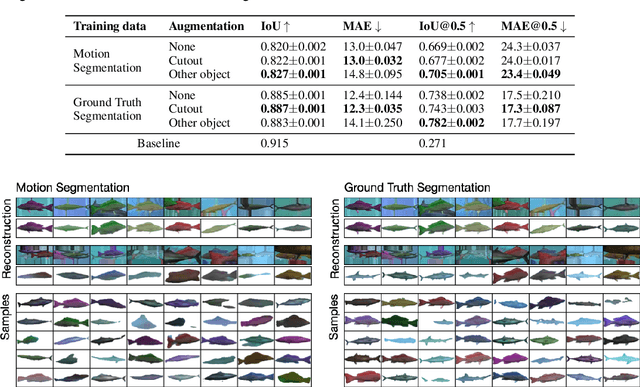
Learning generative object models from unlabelled videos is a long standing problem and required for causal scene modeling. We decompose this problem into three easier subtasks, and provide candidate solutions for each of them. Inspired by the Common Fate Principle of Gestalt Psychology, we first extract (noisy) masks of moving objects via unsupervised motion segmentation. Second, generative models are trained on the masks of the background and the moving objects, respectively. Third, background and foreground models are combined in a conditional "dead leaves" scene model to sample novel scene configurations where occlusions and depth layering arise naturally. To evaluate the individual stages, we introduce the Fishbowl dataset positioned between complex real-world scenes and common object-centric benchmarks of simplistic objects. We show that our approach allows learning generative models that generalize beyond the occlusions present in the input videos, and represent scenes in a modular fashion that allows sampling plausible scenes outside the training distribution by permitting, for instance, object numbers or densities not observed in the training set.
Adapting ImageNet-scale models to complex distribution shifts with self-learning
Apr 28, 2021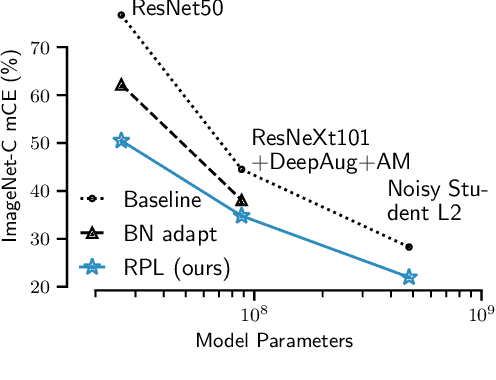

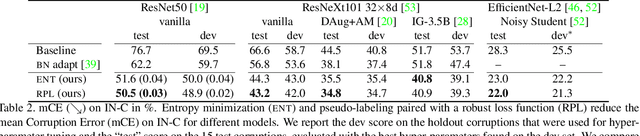
While self-learning methods are an important component in many recent domain adaptation techniques, they are not yet comprehensively evaluated on ImageNet-scale datasets common in robustness research. In extensive experiments on ResNet and EfficientNet models, we find that three components are crucial for increasing performance with self-learning: (i) using short update times between the teacher and the student network, (ii) fine-tuning only few affine parameters distributed across the network, and (iii) leveraging methods from robust classification to counteract the effect of label noise. We use these insights to obtain drastically improved state-of-the-art results on ImageNet-C (22.0% mCE), ImageNet-R (17.4% error) and ImageNet-A (14.8% error). Our techniques yield further improvements in combination with previously proposed robustification methods. Self-learning is able to reduce the top-1 error to a point where no substantial further progress can be expected. We therefore re-purpose the dataset from the Visual Domain Adaptation Challenge 2019 and use a subset of it as a new robustness benchmark (ImageNet-D) which proves to be a more challenging dataset for all current state-of-the-art models (58.2% error) to guide future research efforts at the intersection of robustness and domain adaptation on ImageNet scale.