 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Saliency Dataset Bias
May 15, 2025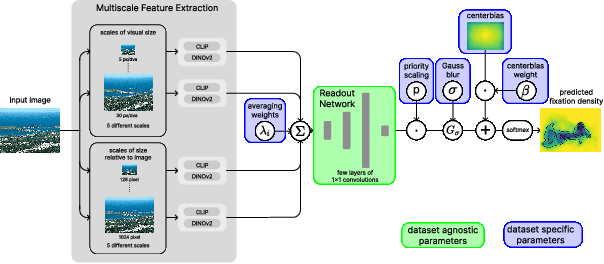
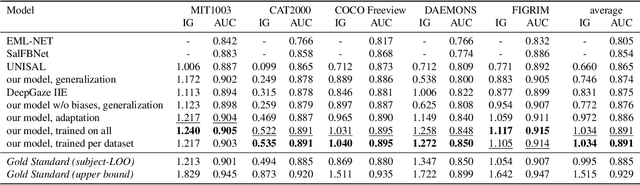
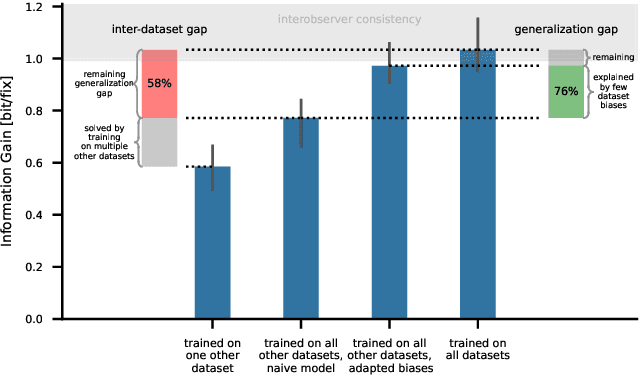
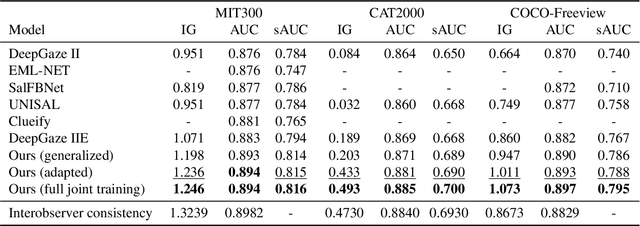
Recent advances in image-based saliency prediction are approaching gold standard performance levels on existing benchmarks. Despite this success, we show that predicting fixations across multiple saliency datasets remains challenging due to dataset bias. We find a significant performance drop (around 40%) when models trained on one dataset are applied to another. Surprisingly, increasing dataset diversity does not resolve this inter-dataset gap, with close to 60% attributed to dataset-specific biases. To address this remaining generalization gap, we propose a novel architecture extending a mostly dataset-agnostic encoder-decoder structure with fewer than 20 dataset-specific parameters that govern interpretable mechanisms such as multi-scale structure, center bias, and fixation spread. Adapting only these parameters to new data accounts for more than 75% of the generalization gap, with a large fraction of the improvement achieved with as few as 50 samples. Our model sets a new state-of-the-art on all three datasets of the MIT/Tuebingen Saliency Benchmark (MIT300, CAT2000, and COCO-Freeview), even when purely generalizing from unrelated datasets, but with a substantial boost when adapting to the respective training datasets. The model also provides valuable insights into spatial saliency properties, revealing complex multi-scale effects that combine both absolute and relative sizes.
Object segmentation from common fate: Motion energy processing enables human-like zero-shot generalization to random dot stimuli
Nov 03, 2024



Humans excel at detecting and segmenting moving objects according to the Gestalt principle of "common fate". Remarkably, previous works have shown that human perception generalizes this principle in a zero-shot fashion to unseen textures or random dots. In this work, we seek to better understand the computational basis for this capability by evaluating a broad range of optical flow models and a neuroscience inspired motion energy model for zero-shot figure-ground segmentation of random dot stimuli. Specifically, we use the extensively validated motion energy model proposed by Simoncelli and Heeger in 1998 which is fitted to neural recordings in cortex area MT. We find that a cross section of 40 deep optical flow models trained on different datasets struggle to estimate motion patterns in random dot videos, resulting in poor figure-ground segmentation performance. Conversely, the neuroscience-inspired model significantly outperforms all optical flow models on this task. For a direct comparison to human perception, we conduct a psychophysical study using a shape identification task as a proxy to measure human segmentation performance. All state-of-the-art optical flow models fall short of human performance, but only the motion energy model matches human capability. This neuroscience-inspired model successfully addresses the lack of human-like zero-shot generalization to random dot stimuli in current computer vision models, and thus establishes a compelling link between the Gestalt psychology of human object perception and cortical motion processing in the brain. Code, models and datasets are available at https://github.com/mtangemann/motion_energy_segmentation
RDumb: A simple approach that questions our progress in continual test-time adaptation
Jun 08, 2023Test-Time Adaptation (TTA) allows to update pretrained models to changing data distributions at deployment time. While early work tested these algorithms for individual fixed distribution shifts, recent work proposed and applied methods for continual adaptation over long timescales. To examine the reported progress in the field, we propose the Continuously Changing Corruptions (CCC) benchmark to measure asymptotic performance of TTA techniques. We find that eventually all but one state-of-the-art methods collapse and perform worse than a non-adapting model, including models specifically proposed to be robust to performance collapse. In addition, we introduce a simple baseline, "RDumb", that periodically resets the model to its pretrained state. RDumb performs better or on par with the previously proposed state-of-the-art in all considered benchmarks. Our results show that previous TTA approaches are neither effective at regularizing adaptation to avoid collapse nor able to outperform a simplistic resetting strategy.
Disentanglement and Generalization Under Correlation Shifts
Dec 29, 2021



Correlations between factors of variation are prevalent in real-world data. Machine learning algorithms may benefit from exploiting such correlations, as they can increase predictive performance on noisy data. However, often such correlations are not robust (e.g., they may change between domains, datasets, or applications) and we wish to avoid exploiting them. Disentanglement methods aim to learn representations which capture different factors of variation in latent subspaces. A common approach involves minimizing the mutual information between latent subspaces, such that each encodes a single underlying attribute. However, this fails when attributes are correlated. We solve this problem by enforcing independence between subspaces conditioned on the available attributes, which allows us to remove only dependencies that are not due to the correlation structure present in the training data. We achieve this via an adversarial approach to minimize the conditional mutual information (CMI) between subspaces with respect to categorical variables. We first show theoretically that CMI minimization is a good objective for robust disentanglement on linear problems with Gaussian data. We then apply our method on real-world datasets based on MNIST and CelebA, and show that it yields models that are disentangled and robust under correlation shift, including in weakly supervised settings.
Unsupervised Object Learning via Common Fate
Oct 13, 2021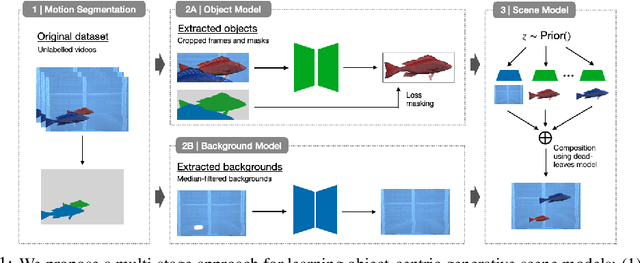
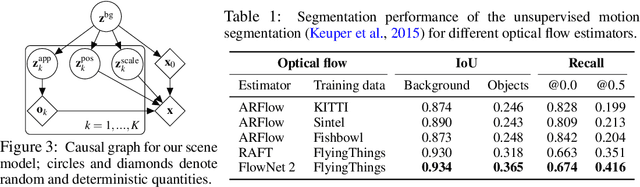

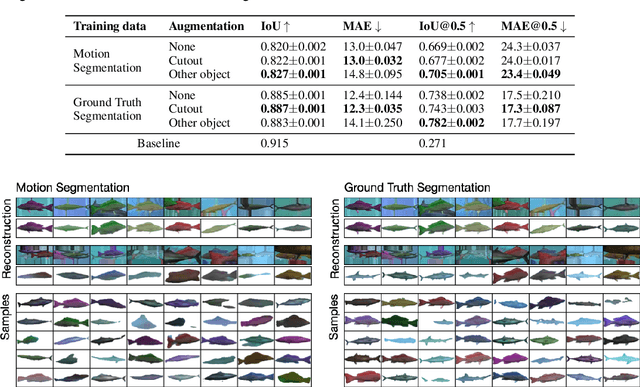
Learning generative object models from unlabelled videos is a long standing problem and required for causal scene modeling. We decompose this problem into three easier subtasks, and provide candidate solutions for each of them. Inspired by the Common Fate Principle of Gestalt Psychology, we first extract (noisy) masks of moving objects via unsupervised motion segmentation. Second, generative models are trained on the masks of the background and the moving objects, respectively. Third, background and foreground models are combined in a conditional "dead leaves" scene model to sample novel scene configurations where occlusions and depth layering arise naturally. To evaluate the individual stages, we introduce the Fishbowl dataset positioned between complex real-world scenes and common object-centric benchmarks of simplistic objects. We show that our approach allows learning generative models that generalize beyond the occlusions present in the input videos, and represent scenes in a modular fashion that allows sampling plausible scenes outside the training distribution by permitting, for instance, object numbers or densities not observed in the training set.
Calibrated prediction in and out-of-domain for state-of-the-art saliency modeling
May 27, 2021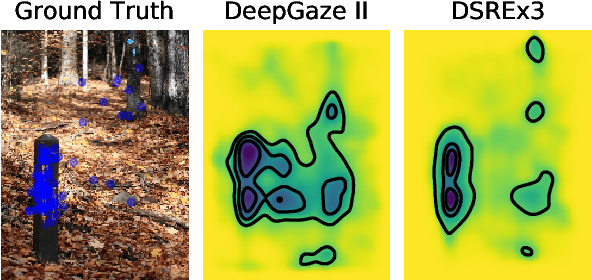

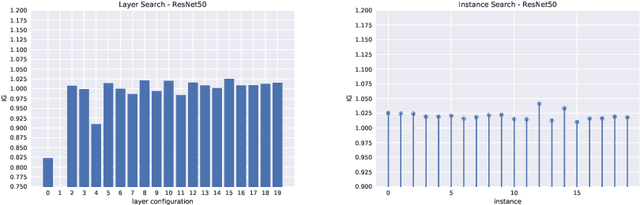
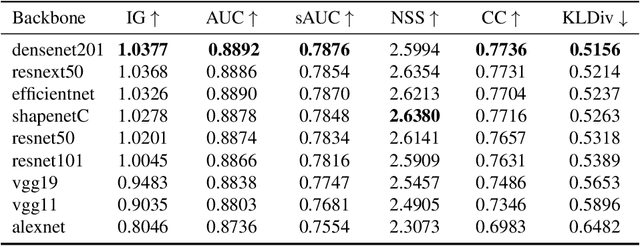
Since 2014 transfer learning has become the key driver for the improvement of spatial saliency prediction; however, with stagnant progress in the last 3-5 years. We conduct a large-scale transfer learning study which tests different ImageNet backbones, always using the same read out architecture and learning protocol adopted from DeepGaze II. By replacing the VGG19 backbone of DeepGaze II with ResNet50 features we improve the performance on saliency prediction from 78% to 85%. However, as we continue to test better ImageNet models as backbones (such as EfficientNetB5) we observe no additional improvement on saliency prediction. By analyzing the backbones further, we find that generalization to other datasets differs substantially, with models being consistently overconfident in their fixation predictions. We show that by combining multiple backbones in a principled manner a good confidence calibration on unseen datasets can be achieved. This yields a significant leap in benchmark performance in and out-of-domain with a 15 percent point improvement over DeepGaze II to 93% on MIT1003, marking a new state of the art on the MIT/Tuebingen Saliency Benchmark in all available metrics (AUC: 88.3%, sAUC: 79.4%, CC: 82.4%).
State-of-the-Art in Human Scanpath Prediction
Feb 24, 2021
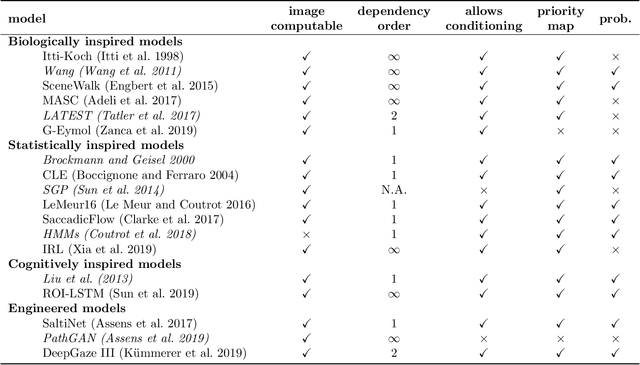
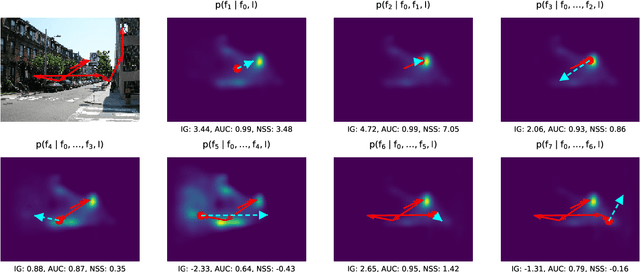
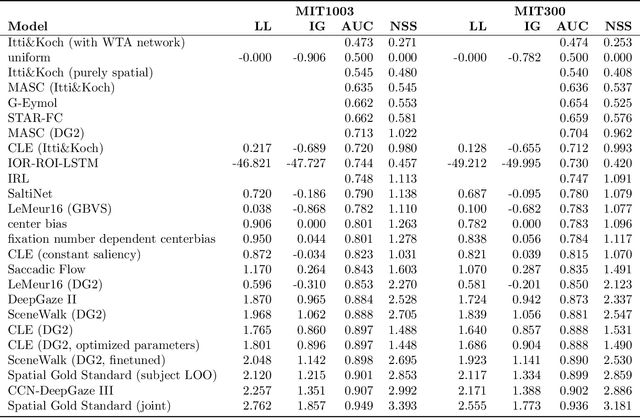
The last years have seen a surge in models predicting the scanpaths of fixations made by humans when viewing images. However, the field is lacking a principled comparison of those models with respect to their predictive power. In the past, models have usually been evaluated based on comparing human scanpaths to scanpaths generated from the model. Here, instead we evaluate models based on how well they predict each fixation in a scanpath given the previous scanpath history. This makes model evaluation closely aligned with the biological processes thought to underly scanpath generation and allows to apply established saliency metrics like AUC and NSS in an intuitive and interpretable way. We evaluate many existing models of scanpath prediction on the datasets MIT1003, MIT300, CAT2000 train and CAT200 test, for the first time giving a detailed picture of the current state of the art of human scanpath prediction. We also show that the discussed method of model benchmarking allows for more detailed analyses leading to interesting insights about where and when models fail to predict human behaviour. The MIT/Tuebingen Saliency Benchmark will implement the evaluation of scanpath models as detailed here, allowing researchers to score their models on the established benchmark datasets MIT300 and CAT2000.
Accurate, reliable and fast robustness evaluation
Jul 01, 2019
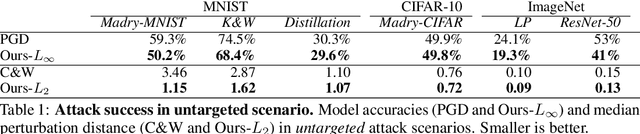


Throughout the past five years, the susceptibility of neural networks to minimal adversarial perturbations has moved from a peculiar phenomenon to a core issue in Deep Learning. Despite much attention, however, progress towards more robust models is significantly impaired by the difficulty of evaluating the robustness of neural network models. Today's methods are either fast but brittle (gradient-based attacks), or they are fairly reliable but slow (score- and decision-based attacks). We here develop a new set of gradient-based adversarial attacks which (a) are more reliable in the face of gradient-masking than other gradient-based attacks, (b) perform better and are more query efficient than current state-of-the-art gradient-based attacks, (c) can be flexibly adapted to a wide range of adversarial criteria and (d) require virtually no hyperparameter tuning. These findings are carefully validated across a diverse set of six different models and hold for L2 and L_infinity in both targeted as well as untargeted scenarios. Implementations will be made available in all major toolboxes (Foolbox, CleverHans and ART). Furthermore, we will soon add additional content and experiments, including L0 and L1 versions of our attack as well as additional comparisons to other L2 and L_infinity attacks. We hope that this class of attacks will make robustness evaluations easier and more reliable, thus contributing to more signal in the search for more robust machine learning models.
Saliency Benchmarking Made Easy: Separating Models, Maps and Metrics
Jul 25, 2018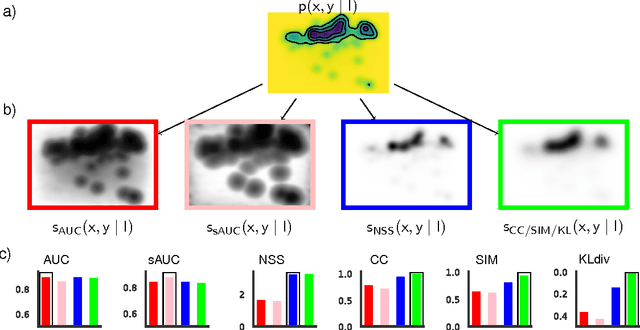

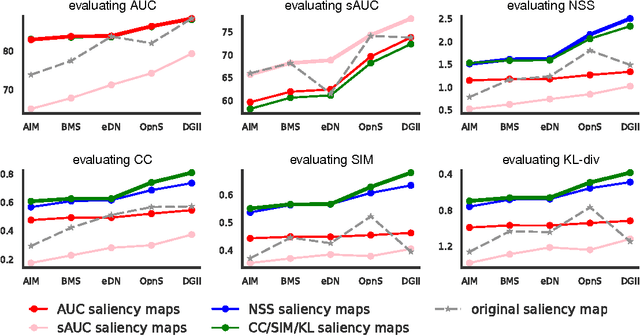
Dozens of new models on fixation prediction are published every year and compared on open benchmarks such as MIT300 and LSUN. However, progress in the field can be difficult to judge because models are compared using a variety of inconsistent metrics. Here we show that no single saliency map can perform well under all metrics. Instead, we propose a principled approach to solve the benchmarking problem by separating the notions of saliency models, maps and metrics. Inspired by Bayesian decision theory, we define a saliency model to be a probabilistic model of fixation density prediction and a saliency map to be a metric-specific prediction derived from the model density which maximizes the expected performance on that metric given the model density. We derive these optimal saliency maps for the most commonly used saliency metrics (AUC, sAUC, NSS, CC, SIM, KL-Div) and show that they can be computed analytically or approximated with high precision. We show that this leads to consistent rankings in all metrics and avoids the penalties of using one saliency map for all metrics. Our method allows researchers to have their model compete on many different metrics with state-of-the-art in those metrics: "good" models will perform well in all metrics.
Guiding human gaze with convolutional neural networks
Dec 18, 2017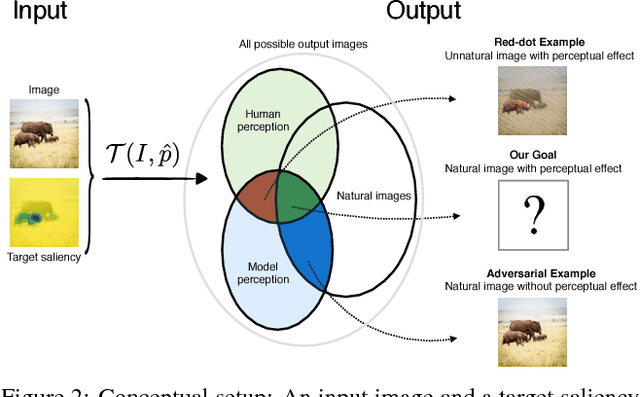
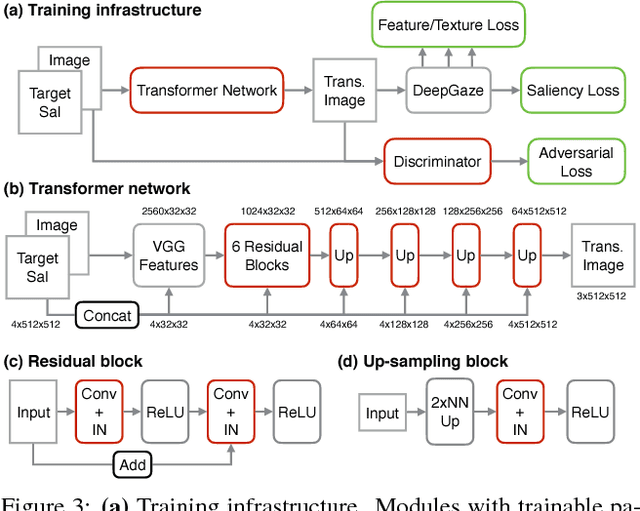
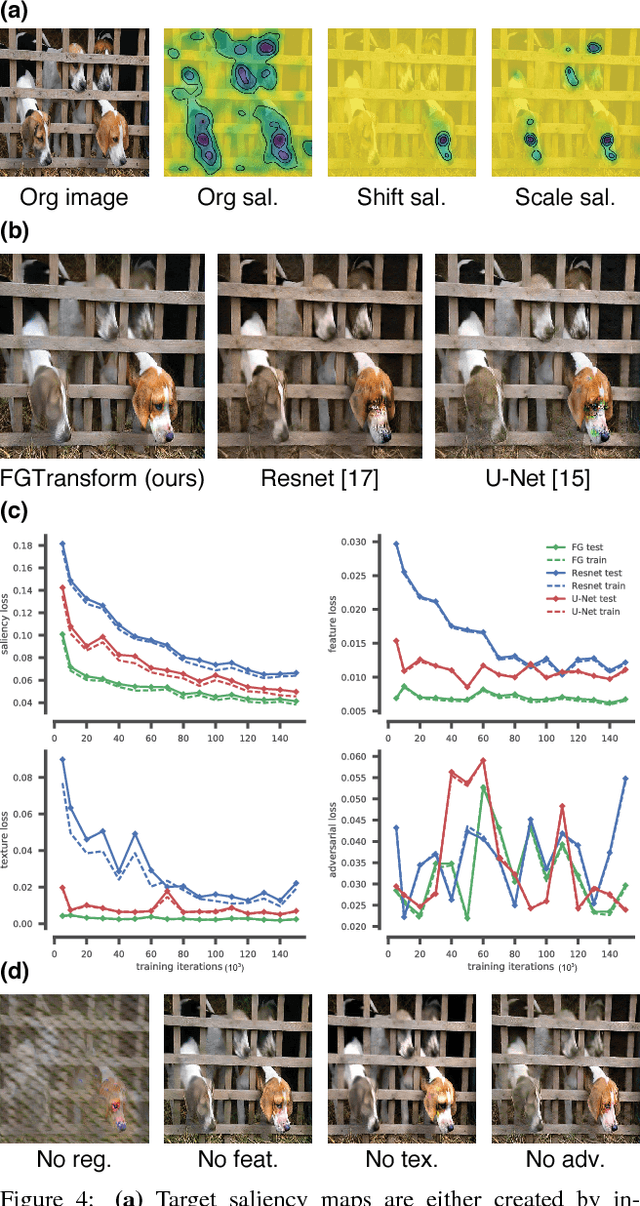

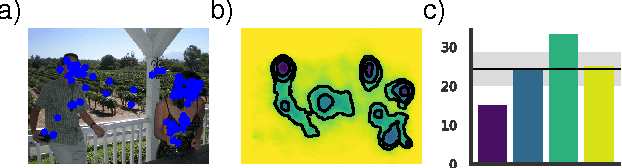
The eye fixation patterns of human observers are a fundamental indicator of the aspects of an image to which humans attend. Thus, manipulating fixation patterns to guide human attention is an exciting challenge in digital image processing. Here, we present a new model for manipulating images to change the distribution of human fixations in a controlled fashion. We use the state-of-the-art model for fixation prediction to train a convolutional neural network to transform images so that they satisfy a given fixation distribution. For network training, we carefully design a loss function to achieve a perceptual effect while preserving naturalness of the transformed images. Finally, we evaluate the success of our model by measuring human fixations for a set of manipulated images. On our test images we can in-/decrease the probability to fixate on selected objects on average by 43/22% but show that the effectiveness of the model depends on the semantic content of the manipulated images.