 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
Jul 21, 2020
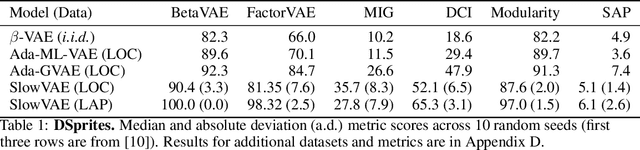
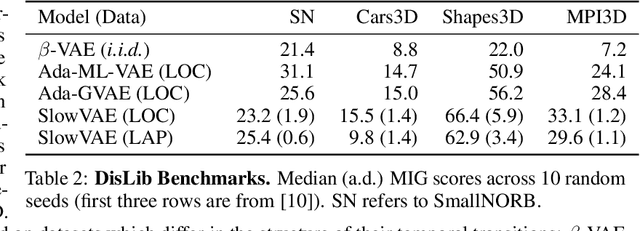
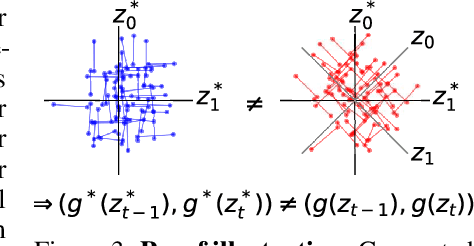
We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disentangled if all but a few factors in the environment stay constant at any point in time. As a result, algorithms proposed for this problem have only been tested on carefully constructed datasets with this exact property, leaving it unclear whether they will transfer to natural scenes. Here we provide evidence that objects in segmented natural movies undergo transitions that are typically small in magnitude with occasional large jumps, which is characteristic of a temporally sparse distribution. We leverage this finding and present SlowVAE, a model for unsupervised representation learning that uses a sparse prior on temporally adjacent observations to disentangle generative factors without any assumptions on the number of changing factors. We provide a proof of identifiability and show that the model reliably learns disentangled representations on several established benchmark datasets, often surpassing the current state-of-the-art. We additionally demonstrate transferability towards video datasets with natural dynamics, Natural Sprites and KITTI Masks, which we contribute as benchmarks for guiding disentanglement research towards more natural data domains.
Towards causal generative scene models via competition of experts
Apr 27, 2020

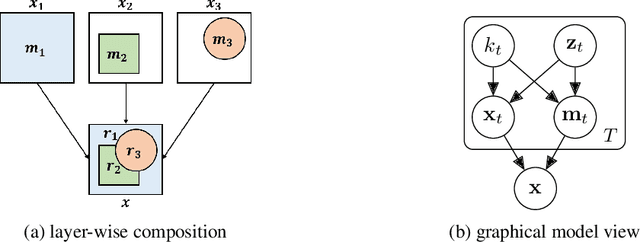
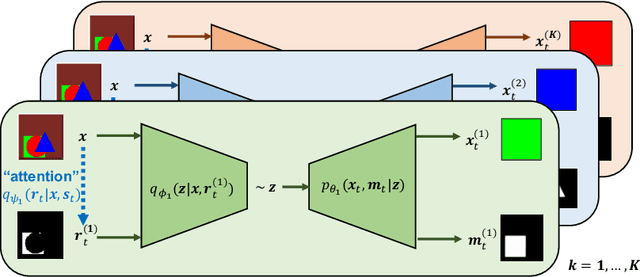
Learning how to model complex scenes in a modular way with recombinable components is a pre-requisite for higher-order reasoning and acting in the physical world. However, current generative models lack the ability to capture the inherently compositional and layered nature of visual scenes. While recent work has made progress towards unsupervised learning of object-based scene representations, most models still maintain a global representation space (i.e., objects are not explicitly separated), and cannot generate scenes with novel object arrangement and depth ordering. Here, we present an alternative approach which uses an inductive bias encouraging modularity by training an ensemble of generative models (experts). During training, experts compete for explaining parts of a scene, and thus specialise on different object classes, with objects being identified as parts that re-occur across multiple scenes. Our model allows for controllable sampling of individual objects and recombination of experts in physically plausible ways. In contrast to other methods, depth layering and occlusion are handled correctly, moving this approach closer to a causal generative scene model. Experiments on simple toy data qualitatively demonstrate the conceptual advantages of the proposed approach.
Compositional uncertainty in deep Gaussian processes
Sep 17, 2019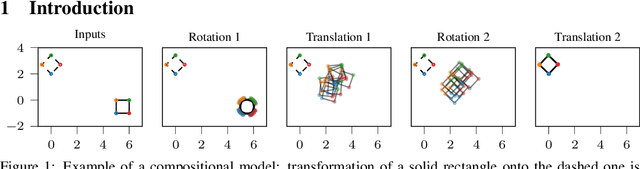
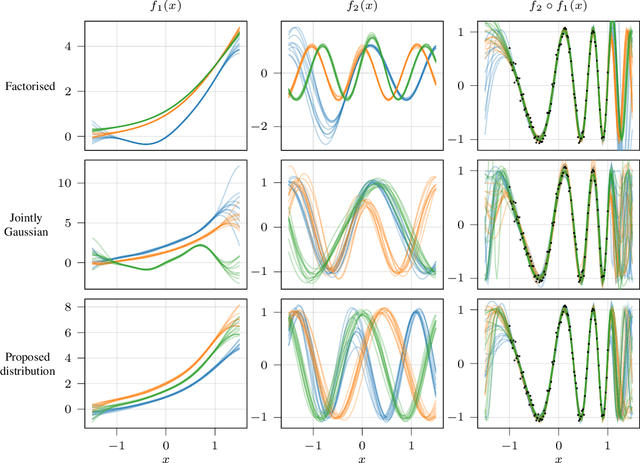
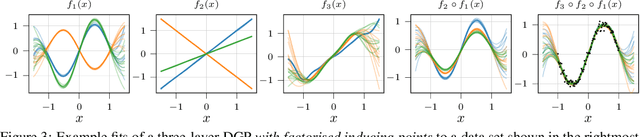
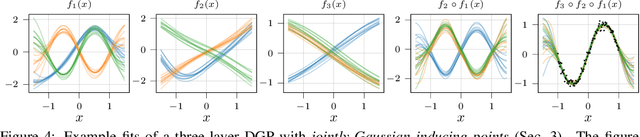
Gaussian processes (GPs) are nonparametric priors over functions, and fitting a GP to the data implies computing the posterior distribution of the functions consistent with the observed data. Similarly, deep Gaussian processes (DGPs) [Damianou:2013] should allow us to compute the posterior distribution of compositions of multiple functions giving rise to the observations. However, exact Bayesian inference is usually intractable for DGPs, motivating the use of various approximations. We show that the simplifying assumptions for a common type of Variational inference approximation imply that all but one layer of a DGP collapse to a deterministic transformation. We argue that such an inference scheme is suboptimal, not taking advantage of the potential of the model to discover the compositional structure in the data, and propose possible modifications addressing this issue.
Accurate, reliable and fast robustness evaluation
Jul 01, 2019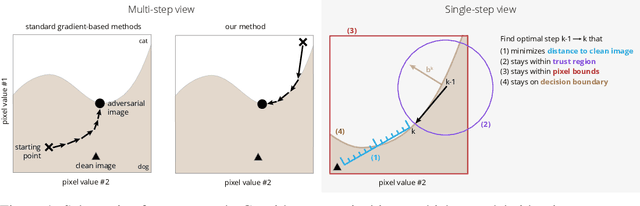
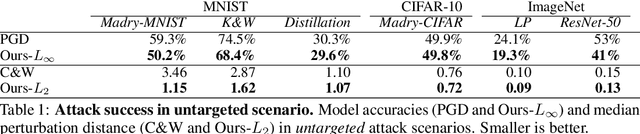


Throughout the past five years, the susceptibility of neural networks to minimal adversarial perturbations has moved from a peculiar phenomenon to a core issue in Deep Learning. Despite much attention, however, progress towards more robust models is significantly impaired by the difficulty of evaluating the robustness of neural network models. Today's methods are either fast but brittle (gradient-based attacks), or they are fairly reliable but slow (score- and decision-based attacks). We here develop a new set of gradient-based adversarial attacks which (a) are more reliable in the face of gradient-masking than other gradient-based attacks, (b) perform better and are more query efficient than current state-of-the-art gradient-based attacks, (c) can be flexibly adapted to a wide range of adversarial criteria and (d) require virtually no hyperparameter tuning. These findings are carefully validated across a diverse set of six different models and hold for L2 and L_infinity in both targeted as well as untargeted scenarios. Implementations will be made available in all major toolboxes (Foolbox, CleverHans and ART). Furthermore, we will soon add additional content and experiments, including L0 and L1 versions of our attack as well as additional comparisons to other L2 and L_infinity attacks. We hope that this class of attacks will make robustness evaluations easier and more reliable, thus contributing to more signal in the search for more robust machine learning models.
Monotonic Gaussian Process Flow
May 30, 2019

We propose a new framework of imposing monotonicity constraints in a Bayesian non-parametric setting. Our approach is based on numerical solutions of stochastic differential equations [Hedge, 2019]. We derive a non-parametric model of monotonic functions that allows for interpretable priors and principled quantification of hierarchical uncertainty. We demonstrate the efficacy of the proposed model by providing competitive results to other probabilistic models of monotonic functions on a number of benchmark functions. In addition, we consider the utility of a monotonic constraint in hierarchical probabilistic models, such as deep Gaussian processes. These typically suffer difficulties in modelling and propagating uncertainties throughout the hierarchy that can lead to hidden layers collapsing to point estimates. We address this by constraining hidden layers to be monotonic and present novel procedures for learning and inference that maintain uncertainty. We illustrate the capacity and versatility of the proposed framework on the task of temporal alignment of time-series data where it is beneficial to preserve the uncertainty in the temporal warpings.
One-Shot Instance Segmentation
Nov 28, 2018

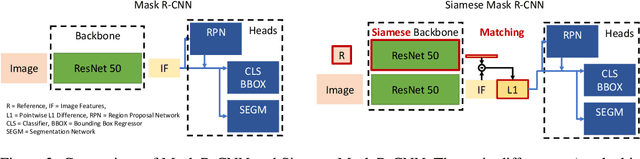

We tackle one-shot visual search by example for arbitrary object categories: Given an example image of a novel reference object, find and segment all object instances of the same category within a scene. To address this problem, we propose Siamese Mask R-CNN. It extends Mask R-CNN by a Siamese backbone encoding both reference image and scene, allowing it to target detection and segmentation towards the reference category. We use Siamese Mask R-CNN to perform one-shot instance segmentation on MS-COCO, demonstrating that it can detect and segment objects of novel categories it was not trained on, and without using mask annotations at test time. Our results highlight challenges of the one-shot setting: while transferring knowledge about instance segmentation to novel object categories not used during training works very well, targeting the detection and segmentation networks towards the reference category appears to be more difficult. Our work provides a first strong baseline for one-shot instance segmentation and will hopefully inspire further research in this relatively unexplored field.
Sequence Alignment with Dirichlet Process Mixtures
Nov 26, 2018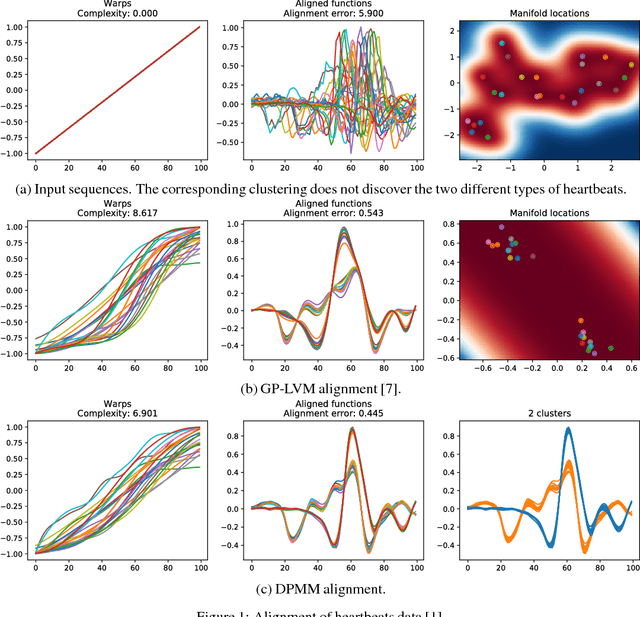
We present a probabilistic model for unsupervised alignment of high-dimensional time-warped sequences based on the Dirichlet Process Mixture Model (DPMM). We follow the approach introduced in (Kazlauskaite, 2018) of simultaneously representing each data sequence as a composition of a true underlying function and a time-warping, both of which are modelled using Gaussian processes (GPs) (Rasmussen, 2005), and aligning the underlying functions using an unsupervised alignment method. In (Kazlauskaite, 2018) the alignment is performed using the GP latent variable model (GP-LVM) (Lawrence, 2005) as a model of sequences, while our main contribution is extending this approach to using DPMM, which allows us to align the sequences temporally and cluster them at the same time. We show that the DPMM achieves competitive results in comparison to the GP-LVM on synthetic and real-world data sets, and discuss the different properties of the estimated underlying functions and the time-warps favoured by these models.
One-shot Texture Segmentation
Jul 07, 2018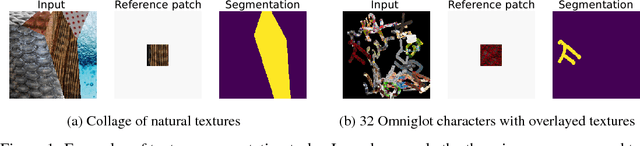
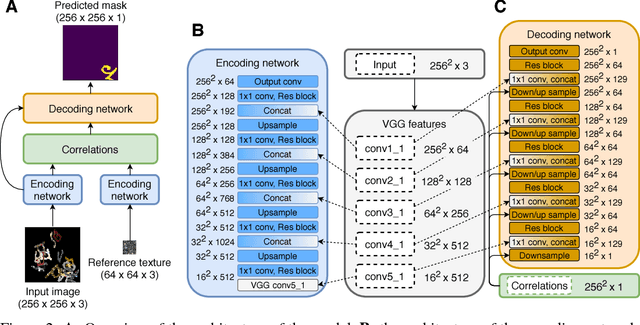
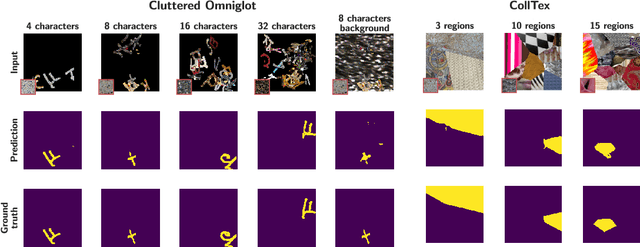
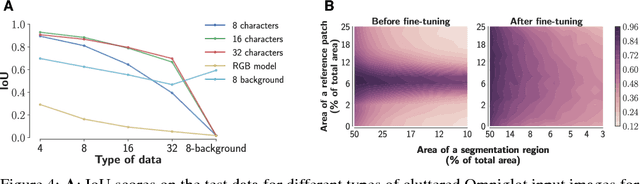
We introduce one-shot texture segmentation: the task of segmenting an input image containing multiple textures given a patch of a reference texture. This task is designed to turn the problem of texture-based perceptual grouping into an objective benchmark. We show that it is straight-forward to generate large synthetic data sets for this task from a relatively small number of natural textures. In particular, this task can be cast as a self-supervised problem thereby alleviating the need for massive amounts of manually annotated data necessary for traditional segmentation tasks. In this paper we introduce and study two concrete data sets: a dense collage of textures (CollTex) and a cluttered texturized Omniglot data set. We show that a baseline model trained on these synthesized data is able to generalize to natural images and videos without further fine-tuning, suggesting that the learned image representations are useful for higher-level vision tasks.
Texture Synthesis Using Shallow Convolutional Networks with Random Filters
May 31, 2016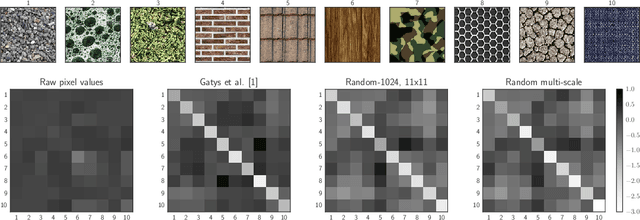



Here we demonstrate that the feature space of random shallow convolutional neural networks (CNNs) can serve as a surprisingly good model of natural textures. Patches from the same texture are consistently classified as being more similar then patches from different textures. Samples synthesized from the model capture spatial correlations on scales much larger then the receptive field size, and sometimes even rival or surpass the perceptual quality of state of the art texture models (but show less variability). The current state of the art in parametric texture synthesis relies on the multi-layer feature space of deep CNNs that were trained on natural images. Our finding suggests that such optimized multi-layer feature spaces are not imperative for texture modeling. Instead, much simpler shallow and convolutional networks can serve as the basis for novel texture synthesis algorithms.