 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025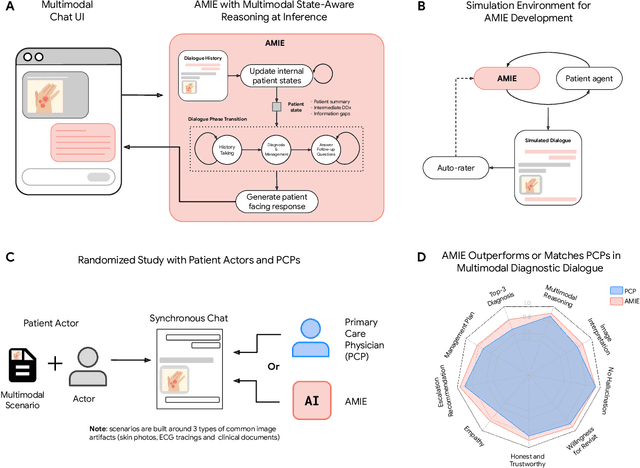
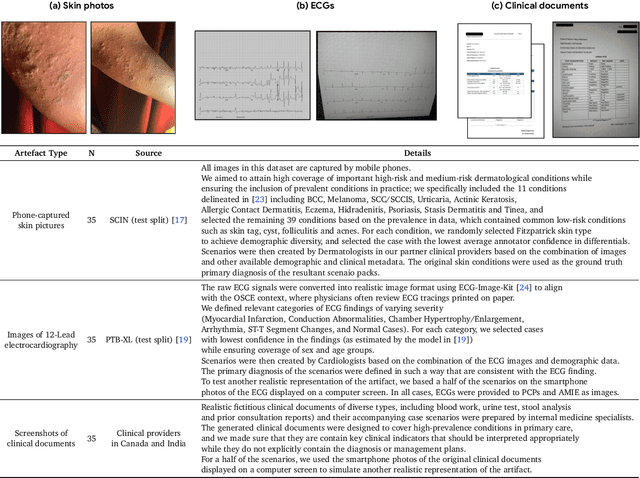
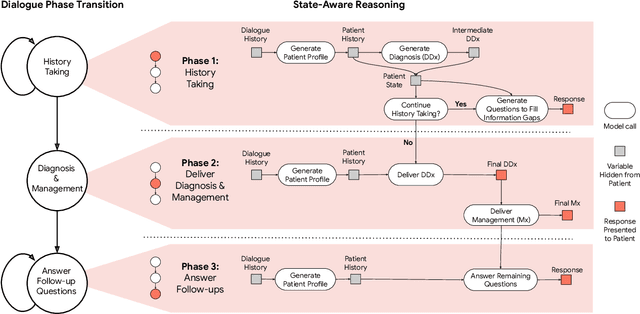
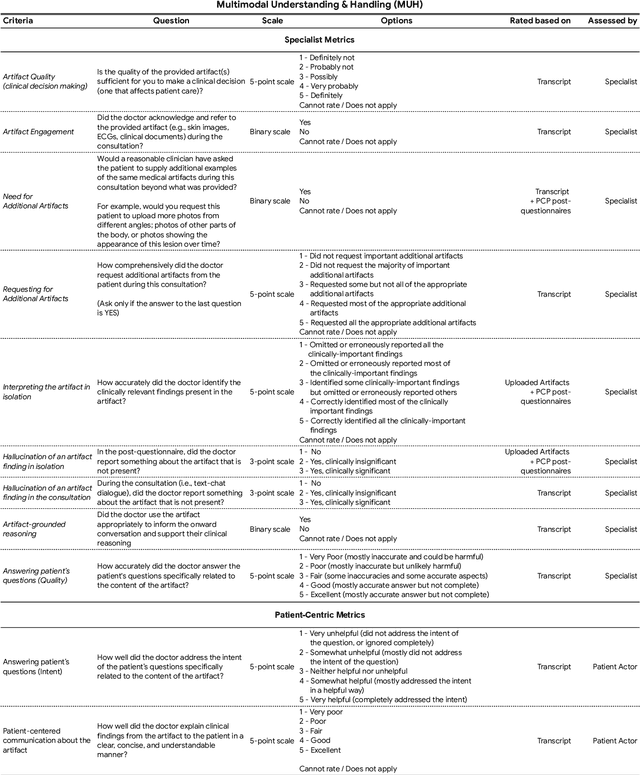
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Fake It Until You Break It: On the Adversarial Robustness of AI-generated Image Detectors
Oct 02, 2024



While generative AI (GenAI) offers countless possibilities for creative and productive tasks, artificially generated media can be misused for fraud, manipulation, scams, misinformation campaigns, and more. To mitigate the risks associated with maliciously generated media, forensic classifiers are employed to identify AI-generated content. However, current forensic classifiers are often not evaluated in practically relevant scenarios, such as the presence of an attacker or when real-world artifacts like social media degradations affect images. In this paper, we evaluate state-of-the-art AI-generated image (AIGI) detectors under different attack scenarios. We demonstrate that forensic classifiers can be effectively attacked in realistic settings, even when the attacker does not have access to the target model and post-processing occurs after the adversarial examples are created, which is standard on social media platforms. These attacks can significantly reduce detection accuracy to the extent that the risks of relying on detectors outweigh their benefits. Finally, we propose a simple defense mechanism to make CLIP-based detectors, which are currently the best-performing detectors, robust against these attacks.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Apr 08, 2024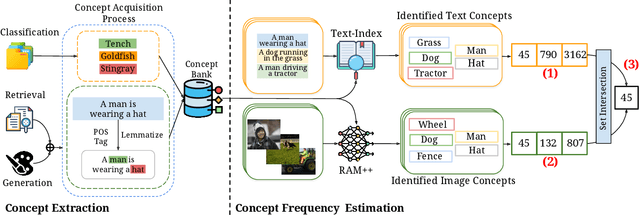


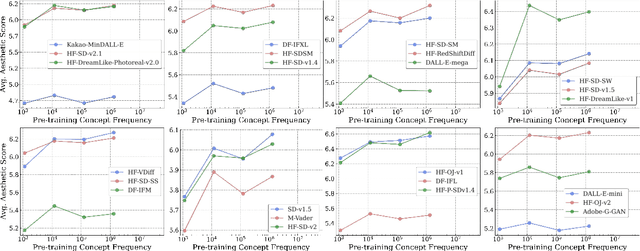
Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.
Gujarati-English Code-Switching Speech Recognition using ensemble prediction of spoken language
Mar 12, 2024An important and difficult task in code-switched speech recognition is to recognize the language, as lots of words in two languages can sound similar, especially in some accents. We focus on improving performance of end-to-end Automatic Speech Recognition models by conditioning transformer layers on language ID of words and character in the output in an per layer supervised manner. To this end, we propose two methods of introducing language specific parameters and explainability in the multi-head attention mechanism, and implement a Temporal Loss that helps maintain continuity in input alignment. Despite being unable to reduce WER significantly, our method shows promise in predicting the correct language from just spoken data. We introduce regularization in the language prediction by dropping LID in the sequence, which helps align long repeated output sequences.
MOSAIC: A Modular System for Assistive and Interactive Cooking
Feb 29, 2024We present MOSAIC, a modular architecture for home robots to perform complex collaborative tasks, such as cooking with everyday users. MOSAIC tightly collaborates with humans, interacts with users using natural language, coordinates multiple robots, and manages an open vocabulary of everyday objects. At its core, MOSAIC employs modularity: it leverages multiple large-scale pre-trained models for general tasks like language and image recognition, while using streamlined modules designed for task-specific control. We extensively evaluate MOSAIC on 60 end-to-end trials where two robots collaborate with a human user to cook a combination of 6 recipes. We also extensively test individual modules with 180 episodes of visuomotor picking, 60 episodes of human motion forecasting, and 46 online user evaluations of the task planner. We show that MOSAIC is able to efficiently collaborate with humans by running the overall system end-to-end with a real human user, completing 68.3% (41/60) collaborative cooking trials of 6 different recipes with a subtask completion rate of 91.6%. Finally, we discuss the limitations of the current system and exciting open challenges in this domain. The project's website is at https://portal-cornell.github.io/MOSAIC/
Nonparametric Partial Disentanglement via Mechanism Sparsity: Sparse Actions, Interventions and Sparse Temporal Dependencies
Jan 10, 2024This work introduces a novel principle for disentanglement we call mechanism sparsity regularization, which applies when the latent factors of interest depend sparsely on observed auxiliary variables and/or past latent factors. We propose a representation learning method that induces disentanglement by simultaneously learning the latent factors and the sparse causal graphical model that explains them. We develop a nonparametric identifiability theory that formalizes this principle and shows that the latent factors can be recovered by regularizing the learned causal graph to be sparse. More precisely, we show identifiablity up to a novel equivalence relation we call "consistency", which allows some latent factors to remain entangled (hence the term partial disentanglement). To describe the structure of this entanglement, we introduce the notions of entanglement graphs and graph preserving functions. We further provide a graphical criterion which guarantees complete disentanglement, that is identifiability up to permutations and element-wise transformations. We demonstrate the scope of the mechanism sparsity principle as well as the assumptions it relies on with several worked out examples. For instance, the framework shows how one can leverage multi-node interventions with unknown targets on the latent factors to disentangle them. We further draw connections between our nonparametric results and the now popular exponential family assumption. Lastly, we propose an estimation procedure based on variational autoencoders and a sparsity constraint and demonstrate it on various synthetic datasets. This work is meant to be a significantly extended version of Lachapelle et al. (2022).
Towards Accurate Differential Diagnosis with Large Language Models
Nov 30, 2023



An accurate differential diagnosis (DDx) is a cornerstone of medical care, often reached through an iterative process of interpretation that combines clinical history, physical examination, investigations and procedures. Interactive interfaces powered by Large Language Models (LLMs) present new opportunities to both assist and automate aspects of this process. In this study, we introduce an LLM optimized for diagnostic reasoning, and evaluate its ability to generate a DDx alone or as an aid to clinicians. 20 clinicians evaluated 302 challenging, real-world medical cases sourced from the New England Journal of Medicine (NEJM) case reports. Each case report was read by two clinicians, who were randomized to one of two assistive conditions: either assistance from search engines and standard medical resources, or LLM assistance in addition to these tools. All clinicians provided a baseline, unassisted DDx prior to using the respective assistive tools. Our LLM for DDx exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% vs 33.6%, [p = 0.04]). Comparing the two assisted study arms, the DDx quality score was higher for clinicians assisted by our LLM (top-10 accuracy 51.7%) compared to clinicians without its assistance (36.1%) (McNemar's Test: 45.7, p < 0.01) and clinicians with search (44.4%) (4.75, p = 0.03). Further, clinicians assisted by our LLM arrived at more comprehensive differential lists than those without its assistance. Our study suggests that our LLM for DDx has potential to improve clinicians' diagnostic reasoning and accuracy in challenging cases, meriting further real-world evaluation for its ability to empower physicians and widen patients' access to specialist-level expertise.
Attribute Diversity Determines the Systematicity Gap in VQA
Nov 15, 2023



The degree to which neural networks can generalize to new combinations of familiar concepts, and the conditions under which they are able to do so, has long been an open question. In this work, we study the systematicity gap in visual question answering: the performance difference between reasoning on previously seen and unseen combinations of object attributes. To test, we introduce a novel diagnostic dataset, CLEVR-HOPE. We find that while increased quantity of training data does not reduce the systematicity gap, increased training data diversity of the attributes in the unseen combination does. In all, our experiments suggest that the more distinct attribute type combinations are seen during training, the more systematic we can expect the resulting model to be.
The intersection of video capsule endoscopy and artificial intelligence: addressing unique challenges using machine learning
Aug 24, 2023



Introduction: Technical burdens and time-intensive review processes limit the practical utility of video capsule endoscopy (VCE). Artificial intelligence (AI) is poised to address these limitations, but the intersection of AI and VCE reveals challenges that must first be overcome. We identified five challenges to address. Challenge #1: VCE data are stochastic and contains significant artifact. Challenge #2: VCE interpretation is cost-intensive. Challenge #3: VCE data are inherently imbalanced. Challenge #4: Existing VCE AIMLT are computationally cumbersome. Challenge #5: Clinicians are hesitant to accept AIMLT that cannot explain their process. Methods: An anatomic landmark detection model was used to test the application of convolutional neural networks (CNNs) to the task of classifying VCE data. We also created a tool that assists in expert annotation of VCE data. We then created more elaborate models using different approaches including a multi-frame approach, a CNN based on graph representation, and a few-shot approach based on meta-learning. Results: When used on full-length VCE footage, CNNs accurately identified anatomic landmarks (99.1%), with gradient weighted-class activation mapping showing the parts of each frame that the CNN used to make its decision. The graph CNN with weakly supervised learning (accuracy 89.9%, sensitivity of 91.1%), the few-shot model (accuracy 90.8%, precision 91.4%, sensitivity 90.9%), and the multi-frame model (accuracy 97.5%, precision 91.5%, sensitivity 94.8%) performed well. Discussion: Each of these five challenges is addressed, in part, by one of our AI-based models. Our goal of producing high performance using lightweight models that aim to improve clinician confidence was achieved.
Demo2Code: From Summarizing Demonstrations to Synthesizing Code via Extended Chain-of-Thought
Jun 08, 2023Language instructions and demonstrations are two natural ways for users to teach robots personalized tasks. Recent progress in Large Language Models (LLMs) has shown impressive performance in translating language instructions into code for robotic tasks. However, translating demonstrations into task code continues to be a challenge due to the length and complexity of both demonstrations and code, making learning a direct mapping intractable. This paper presents Demo2Code, a novel framework that generates robot task code from demonstrations via an extended chain-of-thought and defines a common latent specification to connect the two. Our framework employs a robust two-stage process: (1) a recursive summarization technique that condenses demonstrations into concise specifications, and (2) a code synthesis approach that expands each function recursively from the generated specifications. We conduct extensive evaluation on various robot task benchmarks, including a novel game benchmark Robotouille, designed to simulate diverse cooking tasks in a kitchen environment. The project's website is available at https://portal-cornell.github.io/demo2code-webpage