 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONEBench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities
Dec 09, 2024



Traditional fixed test sets fall short in evaluating open-ended capabilities of foundation models. To address this, we propose ONEBench(OpeN-Ended Benchmarking), a new testing paradigm that consolidates individual evaluation datasets into a unified, ever-expanding sample pool. ONEBench allows users to generate custom, open-ended evaluation benchmarks from this pool, corresponding to specific capabilities of interest. By aggregating samples across test sets, ONEBench enables the assessment of diverse capabilities beyond those covered by the original test sets, while mitigating overfitting and dataset bias. Most importantly, it frames model evaluation as a collective process of selecting and aggregating sample-level tests. The shift from task-specific benchmarks to ONEBench introduces two challenges: (1)heterogeneity and (2)incompleteness. Heterogeneity refers to the aggregation over diverse metrics, while incompleteness describes comparing models evaluated on different data subsets. To address these challenges, we explore algorithms to aggregate sparse measurements into reliable model scores. Our aggregation algorithm ensures identifiability(asymptotically recovering ground-truth scores) and rapid convergence, enabling accurate model ranking with less data. On homogenous datasets, we show our aggregation algorithm provides rankings that highly correlate with those produced by average scores. We also demonstrate robustness to ~95% of measurements missing, reducing evaluation cost by up to 20x with little-to-no change in model rankings. We introduce ONEBench-LLM for language models and ONEBench-LMM for vision-language models, unifying evaluations across these domains. Overall, we present a technique for open-ended evaluation, which can aggregate over incomplete, heterogeneous sample-level measurements to continually grow a benchmark alongside the rapidly developing foundation models.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Apr 08, 2024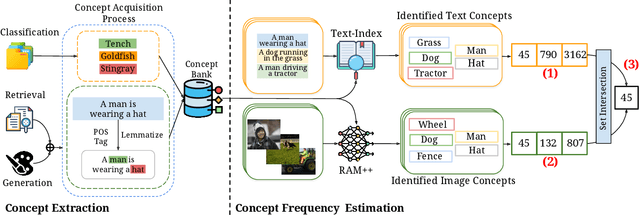


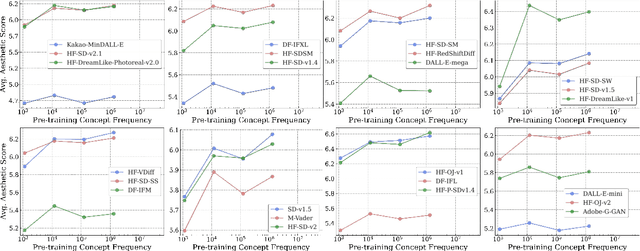
Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.
ViPE: Visualise Pretty-much Everything
Oct 16, 2023
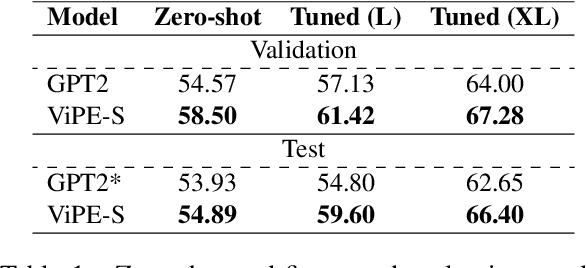


Figurative and non-literal expressions are profoundly integrated in human communication. Visualising such expressions allow us to convey our creative thoughts, and evoke nuanced emotions. Recent text-to-image models like Stable Diffusion, on the other hand, struggle to depict non-literal expressions. Recent works primarily deal with this issue by compiling humanly annotated datasets on a small scale, which not only demands specialised expertise but also proves highly inefficient. To address this issue, we introduce ViPE: Visualise Pretty-much Everything. ViPE offers a series of lightweight and robust language models that have been trained on a large-scale set of lyrics with noisy visual descriptions that represent their implicit meaning. The synthetic visual descriptions are generated by GPT3.5 relying on neither human annotations nor images. ViPE effectively expresses any arbitrary piece of text into a visualisable description, enabling meaningful and high-quality image generation. We provide compelling evidence that ViPE is more robust than GPT3.5 in synthesising visual elaborations. ViPE also exhibits an understanding of figurative expressions comparable to human experts, providing a powerful and open-source backbone to many downstream applications such as music video and caption generation.
Relation Preserving Triplet Mining for Stabilizing the Triplet Loss in Vehicle Re-identification
Oct 15, 2021
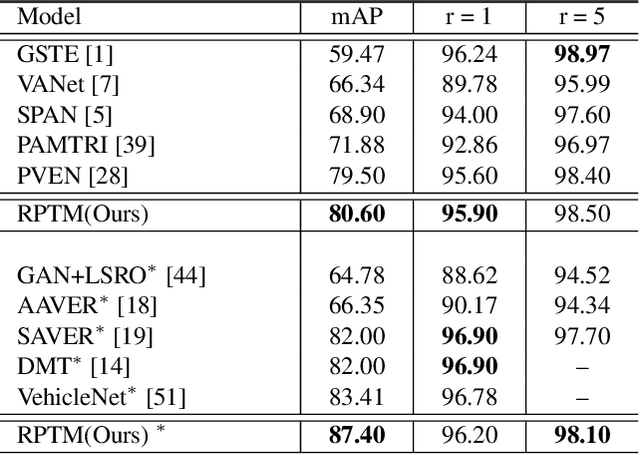
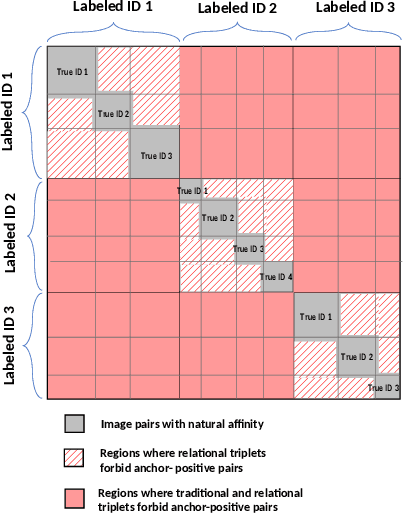

Object appearances often change dramatically with pose variations. This creates a challenge for embedding schemes that seek to map instances with the same object ID to locations that are as close as possible. This issue becomes significantly heightened in complex computer vision tasks such as re-identification(re-id). In this paper, we suggest these dramatic appearance changes are indications that an object ID is composed of multiple natural groups and it is counter-productive to forcefully map instances from different groups to a common location. This leads us to introduce Relation Preserving Triplet Mining (RPTM), a feature matching guided triplet mining scheme, that ensures triplets will respect the natural sub-groupings within an object ID. We use this triplet mining mechanism to establish a pose-aware, well-conditioned triplet cost function. This allows a single network to be trained with fixed parameters across three challenging benchmarks, while still providing state-of-the-art re-identification results.