 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnknown Unknowns: Why Hidden Intentions in LLMs Evade Detection
Jan 26, 2026LLMs are increasingly embedded in everyday decision-making, yet their outputs can encode subtle, unintended behaviours that shape user beliefs and actions. We refer to these covert, goal-directed behaviours as hidden intentions, which may arise from training and optimisation artefacts, or be deliberately induced by an adversarial developer, yet remain difficult to detect in practice. We introduce a taxonomy of ten categories of hidden intentions, grounded in social science research and organised by intent, mechanism, context, and impact, shifting attention from surface-level behaviours to design-level strategies of influence. We show how hidden intentions can be easily induced in controlled models, providing both testbeds for evaluation and demonstrations of potential misuse. We systematically assess detection methods, including reasoning and non-reasoning LLM judges, and find that detection collapses in realistic open-world settings, particularly under low-prevalence conditions, where false positives overwhelm precision and false negatives conceal true risks. Stress tests on precision-prevalence and precision-FNR trade-offs reveal why auditing fails without vanishingly small false positive rates or strong priors on manipulation types. Finally, a qualitative case study shows that all ten categories manifest in deployed, state-of-the-art LLMs, emphasising the urgent need for robust frameworks. Our work provides the first systematic analysis of detectability failures of hidden intentions in LLMs under open-world settings, offering a foundation for understanding, inducing, and stress-testing such behaviours, and establishing a flexible taxonomy for anticipating evolving threats and informing governance.
Extending and Applying Automated HERMES Software Publication Workflows
Oct 23, 2024
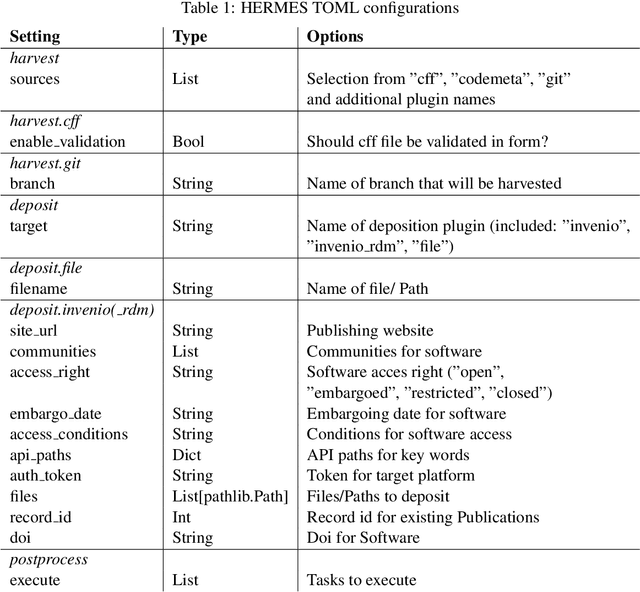
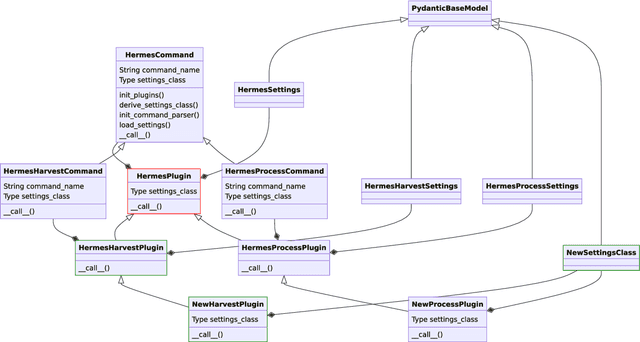
Research software is an import output of research and must be published according to the FAIR Principles for Research Software. This can be achieved by publishing software with metadata under a persistent identifier. HERMES is a tool that leverages continuous integration to automate the publication of software with rich metadata. In this work, we describe the HERMES workflow itself, and how to extend it to meet the needs of specific research software metadata or infrastructure. We introduce the HERMES plugin architecture and provide the example of creating a new HERMES plugin that harvests metadata from a metadata source in source code repositories. We show how to use HERMES as an end user, both via the command line interface, and as a step in a continuous integration pipeline. Finally, we report three informal case studies whose results provide a preliminary evaluation of the feasibility and applicability of HERMES workflows, and the extensibility of the hermes software package.
Fake It Until You Break It: On the Adversarial Robustness of AI-generated Image Detectors
Oct 02, 2024



While generative AI (GenAI) offers countless possibilities for creative and productive tasks, artificially generated media can be misused for fraud, manipulation, scams, misinformation campaigns, and more. To mitigate the risks associated with maliciously generated media, forensic classifiers are employed to identify AI-generated content. However, current forensic classifiers are often not evaluated in practically relevant scenarios, such as the presence of an attacker or when real-world artifacts like social media degradations affect images. In this paper, we evaluate state-of-the-art AI-generated image (AIGI) detectors under different attack scenarios. We demonstrate that forensic classifiers can be effectively attacked in realistic settings, even when the attacker does not have access to the target model and post-processing occurs after the adversarial examples are created, which is standard on social media platforms. These attacks can significantly reduce detection accuracy to the extent that the risks of relying on detectors outweigh their benefits. Finally, we propose a simple defense mechanism to make CLIP-based detectors, which are currently the best-performing detectors, robust against these attacks.
Prompt Obfuscation for Large Language Models
Sep 17, 2024
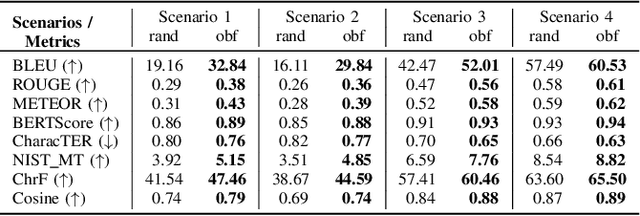

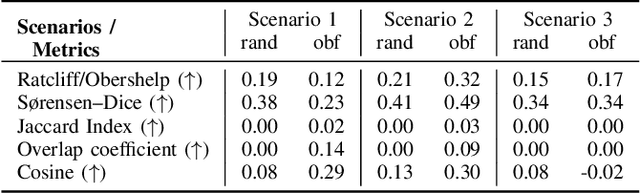
System prompts that include detailed instructions to describe the task performed by the underlying large language model (LLM) can easily transform foundation models into tools and services with minimal overhead. Because of their crucial impact on the utility, they are often considered intellectual property, similar to the code of a software product. However, extracting system prompts is easily possible by using prompt injection. As of today, there is no effective countermeasure to prevent the stealing of system prompts and all safeguarding efforts could be evaded with carefully crafted prompt injections that bypass all protection mechanisms.In this work, we propose an alternative to conventional system prompts. We introduce prompt obfuscation to prevent the extraction of the system prompt while maintaining the utility of the system itself with only little overhead. The core idea is to find a representation of the original system prompt that leads to the same functionality, while the obfuscated system prompt does not contain any information that allows conclusions to be drawn about the original system prompt. We implement an optimization-based method to find an obfuscated prompt representation while maintaining the functionality. To evaluate our approach, we investigate eight different metrics to compare the performance of a system using the original and the obfuscated system prompts, and we show that the obfuscated version is constantly on par with the original one. We further perform three different deobfuscation attacks and show that with access to the obfuscated prompt and the LLM itself, we are not able to consistently extract meaningful information. Overall, we showed that prompt obfuscation can be an effective method to protect intellectual property while maintaining the same utility as the original system prompt.
On the Limitations of Model Stealing with Uncertainty Quantification Models
May 09, 2023


Model stealing aims at inferring a victim model's functionality at a fraction of the original training cost. While the goal is clear, in practice the model's architecture, weight dimension, and original training data can not be determined exactly, leading to mutual uncertainty during stealing. In this work, we explicitly tackle this uncertainty by generating multiple possible networks and combining their predictions to improve the quality of the stolen model. For this, we compare five popular uncertainty quantification models in a model stealing task. Surprisingly, our results indicate that the considered models only lead to marginal improvements in terms of label agreement (i.e., fidelity) to the stolen model. To find the cause of this, we inspect the diversity of the model's prediction by looking at the prediction variance as a function of training iterations. We realize that during training, the models tend to have similar predictions, indicating that the network diversity we wanted to leverage using uncertainty quantification models is not (high) enough for improvements on the model stealing task.