 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Triggered Backdoors
Jan 29, 2026Machine learning models are routinely deployed on a wide range of computing hardware. Although such hardware is typically expected to produce identical results, differences in its design can lead to small numerical variations during inference. In this work, we show that these variations can be exploited to create backdoors in machine learning models. The core idea is to shape the model's decision function such that it yields different predictions for the same input when executed on different hardware. This effect is achieved by locally moving the decision boundary close to a target input and then refining numerical deviations to flip the prediction on selected hardware. We empirically demonstrate that these hardware-triggered backdoors can be created reliably across common GPU accelerators. Our findings reveal a novel attack vector affecting the use of third-party models, and we investigate different defenses to counter this threat.
Adversarial Observations in Weather Forecasting
Apr 22, 2025AI-based systems, such as Google's GenCast, have recently redefined the state of the art in weather forecasting, offering more accurate and timely predictions of both everyday weather and extreme events. While these systems are on the verge of replacing traditional meteorological methods, they also introduce new vulnerabilities into the forecasting process. In this paper, we investigate this threat and present a novel attack on autoregressive diffusion models, such as those used in GenCast, capable of manipulating weather forecasts and fabricating extreme events, including hurricanes, heat waves, and intense rainfall. The attack introduces subtle perturbations into weather observations that are statistically indistinguishable from natural noise and change less than 0.1% of the measurements - comparable to tampering with data from a single meteorological satellite. As modern forecasting integrates data from nearly a hundred satellites and many other sources operated by different countries, our findings highlight a critical security risk with the potential to cause large-scale disruptions and undermine public trust in weather prediction.
Prompt Obfuscation for Large Language Models
Sep 17, 2024
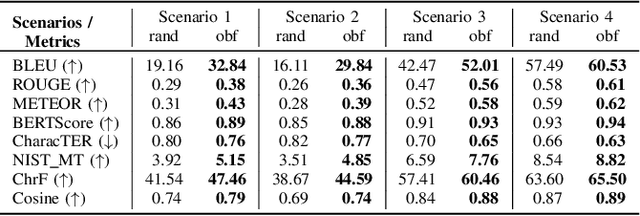

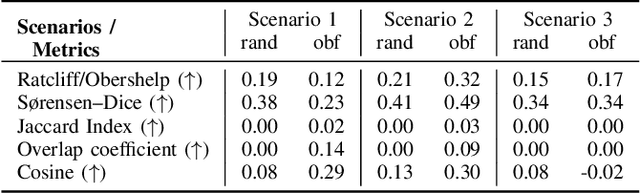
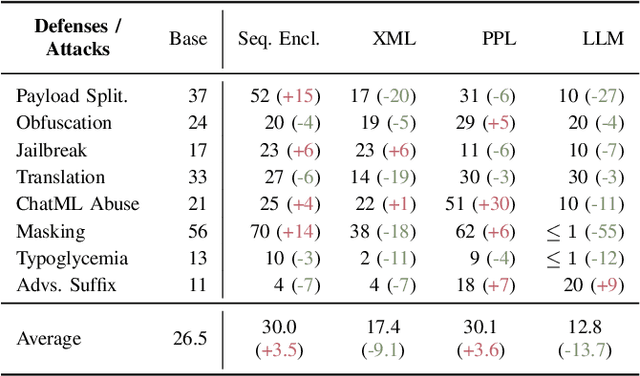
System prompts that include detailed instructions to describe the task performed by the underlying large language model (LLM) can easily transform foundation models into tools and services with minimal overhead. Because of their crucial impact on the utility, they are often considered intellectual property, similar to the code of a software product. However, extracting system prompts is easily possible by using prompt injection. As of today, there is no effective countermeasure to prevent the stealing of system prompts and all safeguarding efforts could be evaded with carefully crafted prompt injections that bypass all protection mechanisms.In this work, we propose an alternative to conventional system prompts. We introduce prompt obfuscation to prevent the extraction of the system prompt while maintaining the utility of the system itself with only little overhead. The core idea is to find a representation of the original system prompt that leads to the same functionality, while the obfuscated system prompt does not contain any information that allows conclusions to be drawn about the original system prompt. We implement an optimization-based method to find an obfuscated prompt representation while maintaining the functionality. To evaluate our approach, we investigate eight different metrics to compare the performance of a system using the original and the obfuscated system prompts, and we show that the obfuscated version is constantly on par with the original one. We further perform three different deobfuscation attacks and show that with access to the obfuscated prompt and the LLM itself, we are not able to consistently extract meaningful information. Overall, we showed that prompt obfuscation can be an effective method to protect intellectual property while maintaining the same utility as the original system prompt.
Whispers in the Machine: Confidentiality in LLM-integrated Systems
Feb 10, 2024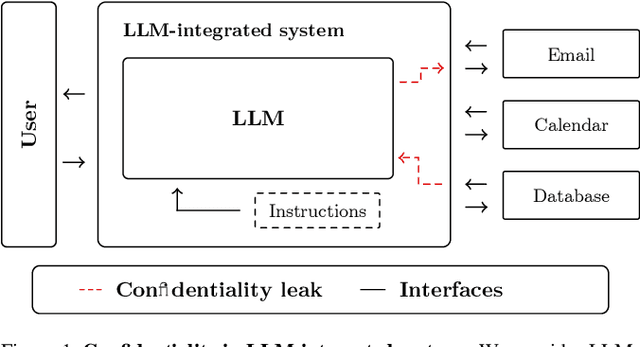
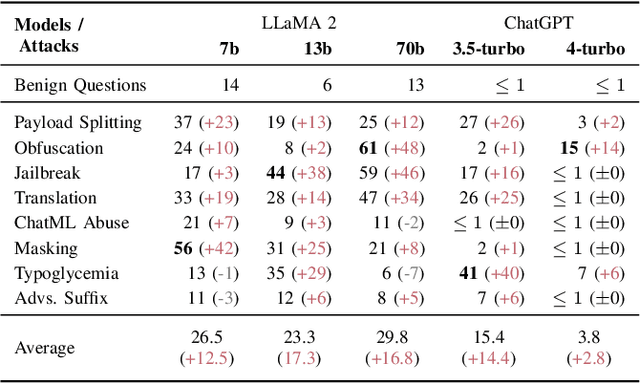
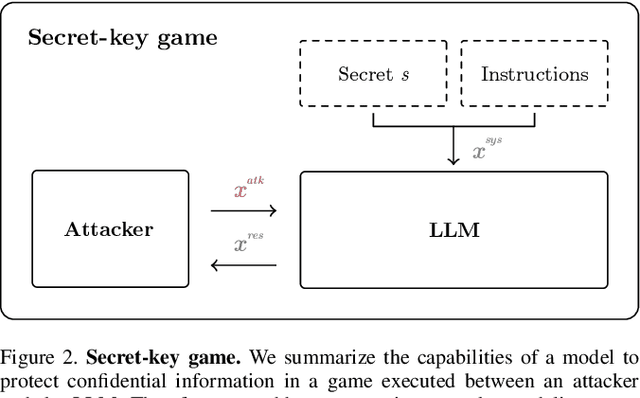
Large Language Models (LLMs) are increasingly integrated with external tools. While these integrations can significantly improve the functionality of LLMs, they also create a new attack surface where confidential data may be disclosed between different components. Specifically, malicious tools can exploit vulnerabilities in the LLM itself to manipulate the model and compromise the data of other services, raising the question of how private data can be protected in the context of LLM integrations. In this work, we provide a systematic way of evaluating confidentiality in LLM-integrated systems. For this, we formalize a "secret key" game that can capture the ability of a model to conceal private information. This enables us to compare the vulnerability of a model against confidentiality attacks and also the effectiveness of different defense strategies. In this framework, we evaluate eight previously published attacks and four defenses. We find that current defenses lack generalization across attack strategies. Building on this analysis, we propose a method for robustness fine-tuning, inspired by adversarial training. This approach is effective in lowering the success rate of attackers and in improving the system's resilience against unknown attacks.
A Representative Study on Human Detection of Artificially Generated Media Across Countries
Dec 10, 2023



AI-generated media has become a threat to our digital society as we know it. These forgeries can be created automatically and on a large scale based on publicly available technology. Recognizing this challenge, academics and practitioners have proposed a multitude of automatic detection strategies to detect such artificial media. However, in contrast to these technical advances, the human perception of generated media has not been thoroughly studied yet. In this paper, we aim at closing this research gap. We perform the first comprehensive survey into people's ability to detect generated media, spanning three countries (USA, Germany, and China) with 3,002 participants across audio, image, and text media. Our results indicate that state-of-the-art forgeries are almost indistinguishable from "real" media, with the majority of participants simply guessing when asked to rate them as human- or machine-generated. In addition, AI-generated media receive is voted more human like across all media types and all countries. To further understand which factors influence people's ability to detect generated media, we include personal variables, chosen based on a literature review in the domains of deepfake and fake news research. In a regression analysis, we found that generalized trust, cognitive reflection, and self-reported familiarity with deepfakes significantly influence participant's decision across all media categories.
On the Limitations of Model Stealing with Uncertainty Quantification Models
May 09, 2023


Model stealing aims at inferring a victim model's functionality at a fraction of the original training cost. While the goal is clear, in practice the model's architecture, weight dimension, and original training data can not be determined exactly, leading to mutual uncertainty during stealing. In this work, we explicitly tackle this uncertainty by generating multiple possible networks and combining their predictions to improve the quality of the stolen model. For this, we compare five popular uncertainty quantification models in a model stealing task. Surprisingly, our results indicate that the considered models only lead to marginal improvements in terms of label agreement (i.e., fidelity) to the stolen model. To find the cause of this, we inspect the diversity of the model's prediction by looking at the prediction variance as a function of training iterations. We realize that during training, the models tend to have similar predictions, indicating that the network diversity we wanted to leverage using uncertainty quantification models is not (high) enough for improvements on the model stealing task.
No more Reviewer #2: Subverting Automatic Paper-Reviewer Assignment using Adversarial Learning
Mar 25, 2023



The number of papers submitted to academic conferences is steadily rising in many scientific disciplines. To handle this growth, systems for automatic paper-reviewer assignments are increasingly used during the reviewing process. These systems use statistical topic models to characterize the content of submissions and automate the assignment to reviewers. In this paper, we show that this automation can be manipulated using adversarial learning. We propose an attack that adapts a given paper so that it misleads the assignment and selects its own reviewers. Our attack is based on a novel optimization strategy that alternates between the feature space and problem space to realize unobtrusive changes to the paper. To evaluate the feasibility of our attack, we simulate the paper-reviewer assignment of an actual security conference (IEEE S&P) with 165 reviewers on the program committee. Our results show that we can successfully select and remove reviewers without access to the assignment system. Moreover, we demonstrate that the manipulated papers remain plausible and are often indistinguishable from benign submissions.
Learned Systems Security
Jan 10, 2023



A learned system uses machine learning (ML) internally to improve performance. We can expect such systems to be vulnerable to some adversarial-ML attacks. Often, the learned component is shared between mutually-distrusting users or processes, much like microarchitectural resources such as caches, potentially giving rise to highly-realistic attacker models. However, compared to attacks on other ML-based systems, attackers face a level of indirection as they cannot interact directly with the learned model. Additionally, the difference between the attack surface of learned and non-learned versions of the same system is often subtle. These factors obfuscate the de-facto risks that the incorporation of ML carries. We analyze the root causes of potentially-increased attack surface in learned systems and develop a framework for identifying vulnerabilities that stem from the use of ML. We apply our framework to a broad set of learned systems under active development. To empirically validate the many vulnerabilities surfaced by our framework, we choose 3 of them and implement and evaluate exploits against prominent learned-system instances. We show that the use of ML caused leakage of past queries in a database, enabled a poisoning attack that causes exponential memory blowup in an index structure and crashes it in seconds, and enabled index users to snoop on each others' key distributions by timing queries over their own keys. We find that adversarial ML is a universal threat against learned systems, point to open research gaps in our understanding of learned-systems security, and conclude by discussing mitigations, while noting that data leakage is inherent in systems whose learned component is shared between multiple parties.
Verifiable and Provably Secure Machine Unlearning
Oct 17, 2022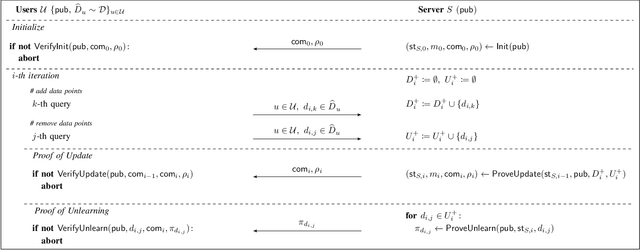



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.
Dompteur: Taming Audio Adversarial Examples
Feb 10, 2021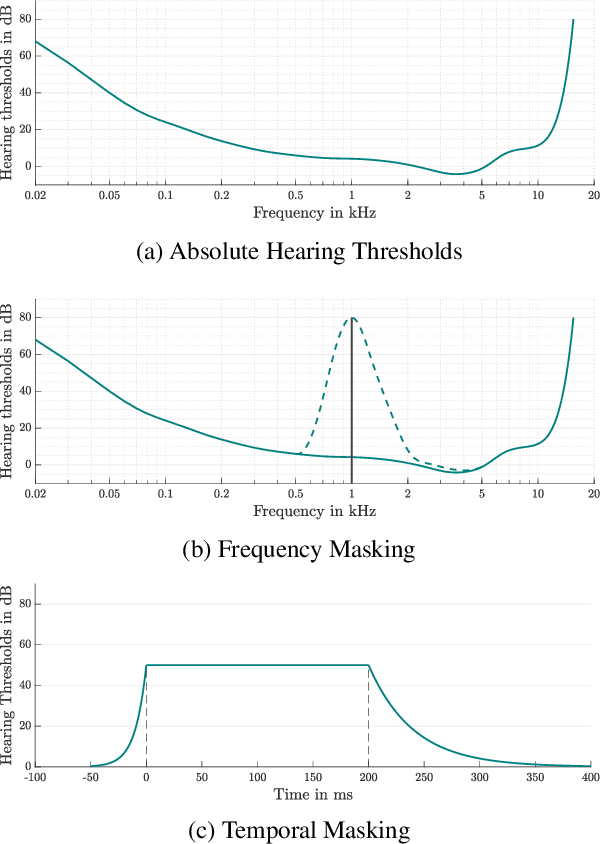

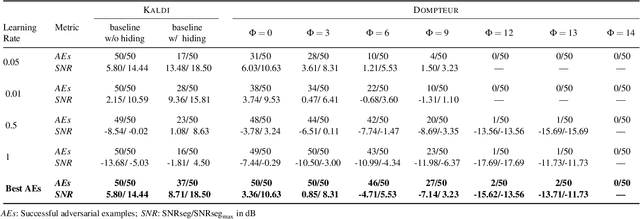
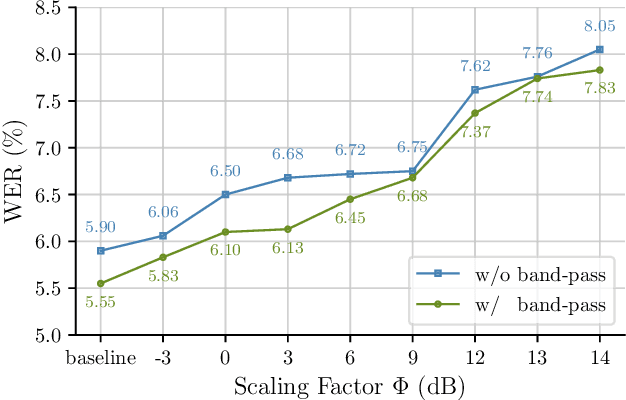
Adversarial examples seem to be inevitable. These specifically crafted inputs allow attackers to arbitrarily manipulate machine learning systems. Even worse, they often seem harmless to human observers. In our digital society, this poses a significant threat. For example, Automatic Speech Recognition (ASR) systems, which serve as hands-free interfaces to many kinds of systems, can be attacked with inputs incomprehensible for human listeners. The research community has unsuccessfully tried several approaches to tackle this problem. In this paper we propose a different perspective: We accept the presence of adversarial examples against ASR systems, but we require them to be perceivable by human listeners. By applying the principles of psychoacoustics, we can remove semantically irrelevant information from the ASR input and train a model that resembles human perception more closely. We implement our idea in a tool named Dompteur and demonstrate that our augmented system, in contrast to an unmodified baseline, successfully focuses on perceptible ranges of the input signal. This change forces adversarial examples into the audible range, while using minimal computational overhead and preserving benign performance. To evaluate our approach, we construct an adaptive attacker, which actively tries to avoid our augmentations and demonstrate that adversarial examples from this attacker remain clearly perceivable. Finally, we substantiate our claims by performing a hearing test with crowd-sourced human listeners.