 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Representative Study on Human Detection of Artificially Generated Media Across Countries
Dec 10, 2023



AI-generated media has become a threat to our digital society as we know it. These forgeries can be created automatically and on a large scale based on publicly available technology. Recognizing this challenge, academics and practitioners have proposed a multitude of automatic detection strategies to detect such artificial media. However, in contrast to these technical advances, the human perception of generated media has not been thoroughly studied yet. In this paper, we aim at closing this research gap. We perform the first comprehensive survey into people's ability to detect generated media, spanning three countries (USA, Germany, and China) with 3,002 participants across audio, image, and text media. Our results indicate that state-of-the-art forgeries are almost indistinguishable from "real" media, with the majority of participants simply guessing when asked to rate them as human- or machine-generated. In addition, AI-generated media receive is voted more human like across all media types and all countries. To further understand which factors influence people's ability to detect generated media, we include personal variables, chosen based on a literature review in the domains of deepfake and fake news research. In a regression analysis, we found that generalized trust, cognitive reflection, and self-reported familiarity with deepfakes significantly influence participant's decision across all media categories.
WaveFake: A Data Set to Facilitate Audio Deepfake Detection
Nov 04, 2021

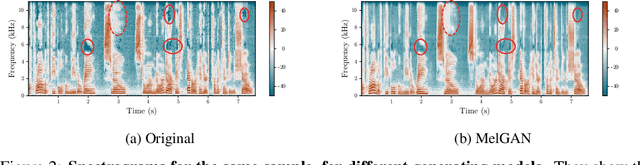
Deep generative modeling has the potential to cause significant harm to society. Recognizing this threat, a magnitude of research into detecting so-called "Deepfakes" has emerged. This research most often focuses on the image domain, while studies exploring generated audio signals have, so-far, been neglected. In this paper we make three key contributions to narrow this gap. First, we provide researchers with an introduction to common signal processing techniques used for analyzing audio signals. Second, we present a novel data set, for which we collected nine sample sets from five different network architectures, spanning two languages. Finally, we supply practitioners with two baseline models, adopted from the signal processing community, to facilitate further research in this area.
CNN-generated images are surprisingly easy to spotfor now
Apr 07, 2021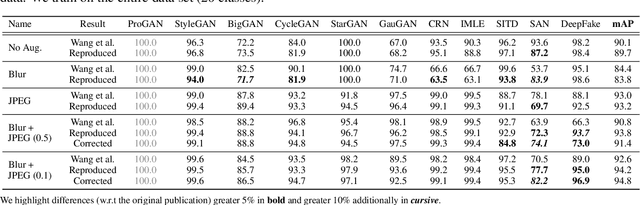
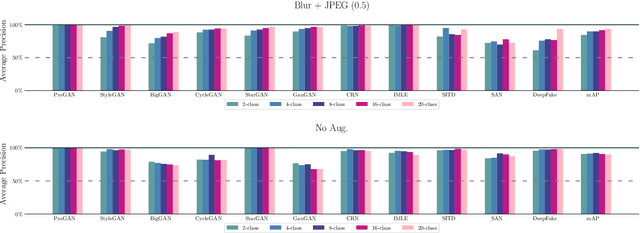

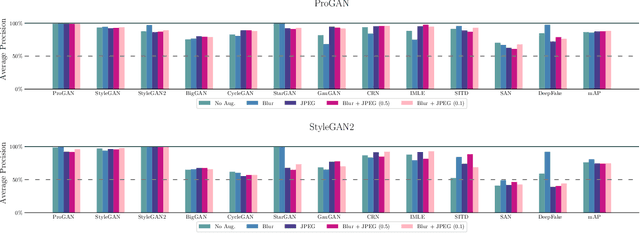
This work evaluates the reproducibility of the paper "CNN-generated images are surprisingly easy to spot... for now" by Wang et al. published at CVPR 2020. The paper addresses the challenge of detecting CNN-generated imagery, which has reached the potential to even fool humans. The authors propose two methods which help an image classifier to generalize from being trained on one specific CNN to detecting imagery produced by unseen architectures, training methods, or data sets. The paper proposes two methods to help a classifier generalize: (i) utilizing different kinds of data augmentations and (ii) using a diverse data set. This report focuses on assessing if these techniques indeed help the generalization process. Furthermore, we perform additional experiments to study the limitations of the proposed techniques.
Dompteur: Taming Audio Adversarial Examples
Feb 10, 2021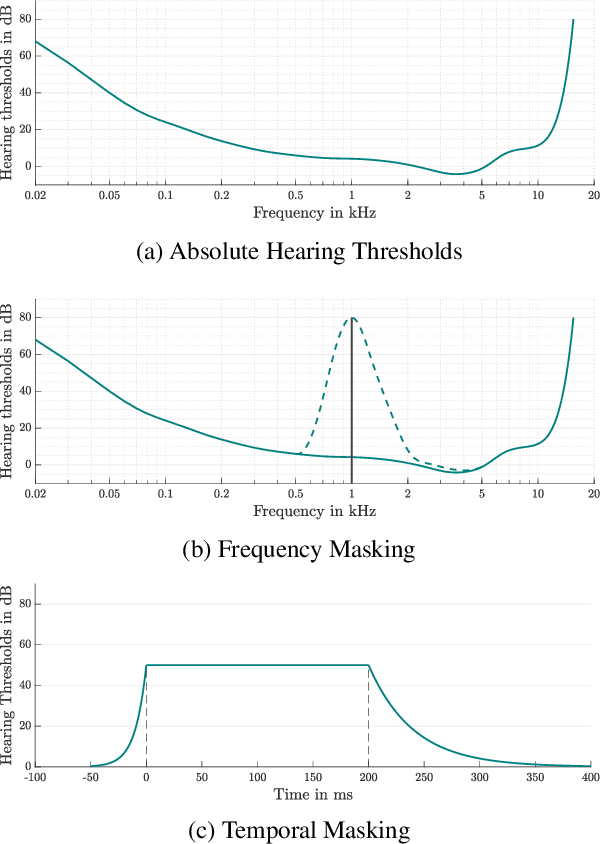

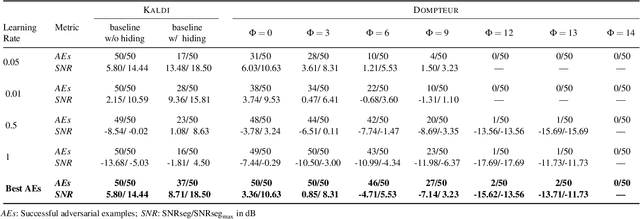
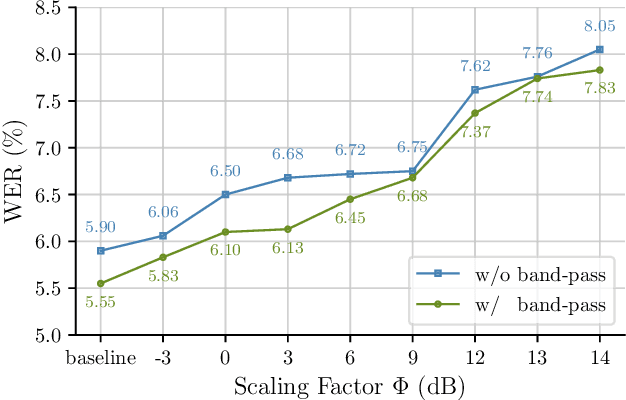
Adversarial examples seem to be inevitable. These specifically crafted inputs allow attackers to arbitrarily manipulate machine learning systems. Even worse, they often seem harmless to human observers. In our digital society, this poses a significant threat. For example, Automatic Speech Recognition (ASR) systems, which serve as hands-free interfaces to many kinds of systems, can be attacked with inputs incomprehensible for human listeners. The research community has unsuccessfully tried several approaches to tackle this problem. In this paper we propose a different perspective: We accept the presence of adversarial examples against ASR systems, but we require them to be perceivable by human listeners. By applying the principles of psychoacoustics, we can remove semantically irrelevant information from the ASR input and train a model that resembles human perception more closely. We implement our idea in a tool named Dompteur and demonstrate that our augmented system, in contrast to an unmodified baseline, successfully focuses on perceptible ranges of the input signal. This change forces adversarial examples into the audible range, while using minimal computational overhead and preserving benign performance. To evaluate our approach, we construct an adaptive attacker, which actively tries to avoid our augmentations and demonstrate that adversarial examples from this attacker remain clearly perceivable. Finally, we substantiate our claims by performing a hearing test with crowd-sourced human listeners.
Leveraging Frequency Analysis for Deep Fake Image Recognition
Mar 20, 2020
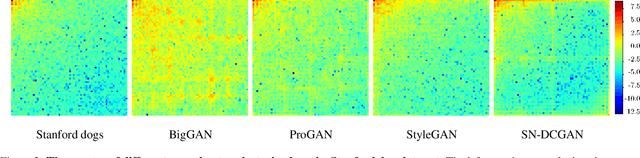
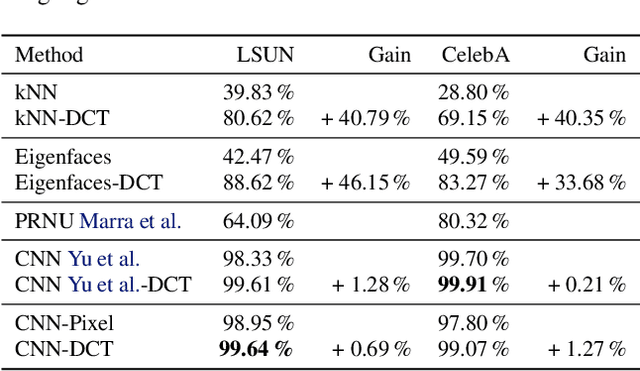
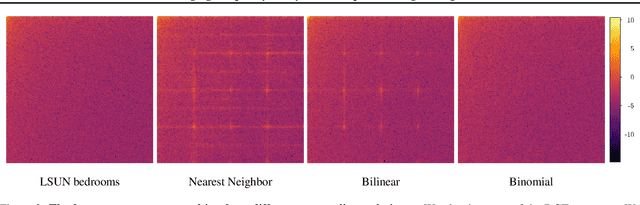
Deep neural networks can generate images that are astonishingly realistic, so much so that it is often hard for humans to distinguish them from actual photos. These achievements have been largely made possible by Generative Adversarial Networks (GANs). While these deep fake images have been thoroughly investigated in the image domain-a classical approach from the area of image forensics-an analysis in the frequency domain has been missing so far. In this paper, we address this shortcoming and our results reveal that in frequency space, GAN-generated images exhibit severe artifacts that can be easily identified. We perform a comprehensive analysis, showing that these artifacts are consistent across different neural network architectures, data sets, and resolutions. In a further investigation, we demonstrate that these artifacts are caused by upsampling operations found in all current GAN architectures, indicating a structural and fundamental problem in the way images are generated via GANs. Based on this analysis, we demonstrate how the frequency representation can be used to identify deep fake images in an automated way, surpassing state-of-the-art methods.