 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-generated images are surprisingly easy to spotfor now
Paper and Code
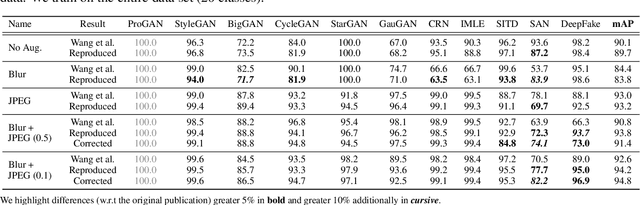
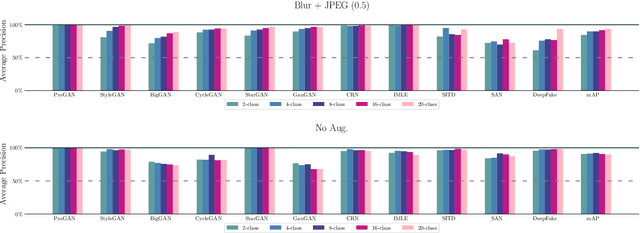

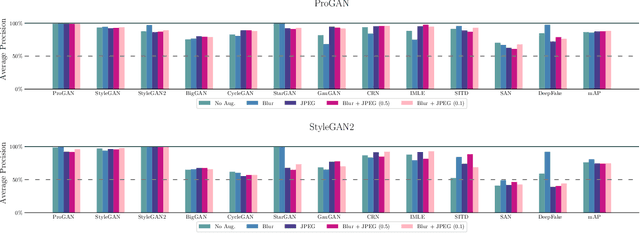
This work evaluates the reproducibility of the paper "CNN-generated images are surprisingly easy to spot... for now" by Wang et al. published at CVPR 2020. The paper addresses the challenge of detecting CNN-generated imagery, which has reached the potential to even fool humans. The authors propose two methods which help an image classifier to generalize from being trained on one specific CNN to detecting imagery produced by unseen architectures, training methods, or data sets. The paper proposes two methods to help a classifier generalize: (i) utilizing different kinds of data augmentations and (ii) using a diverse data set. This report focuses on assessing if these techniques indeed help the generalization process. Furthermore, we perform additional experiments to study the limitations of the proposed techniques.