 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveFake: A Data Set to Facilitate Audio Deepfake Detection
Paper and Code


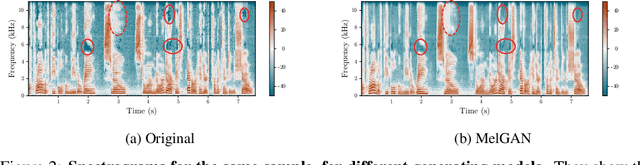
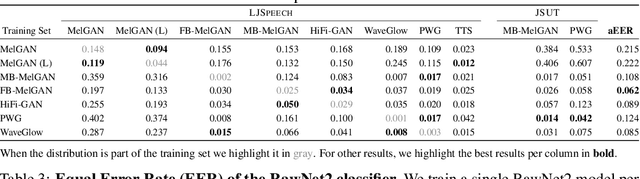
Deep generative modeling has the potential to cause significant harm to society. Recognizing this threat, a magnitude of research into detecting so-called "Deepfakes" has emerged. This research most often focuses on the image domain, while studies exploring generated audio signals have, so-far, been neglected. In this paper we make three key contributions to narrow this gap. First, we provide researchers with an introduction to common signal processing techniques used for analyzing audio signals. Second, we present a novel data set, for which we collected nine sample sets from five different network architectures, spanning two languages. Finally, we supply practitioners with two baseline models, adopted from the signal processing community, to facilitate further research in this area.