 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispers in the Machine: Confidentiality in LLM-integrated Systems
Paper and Code
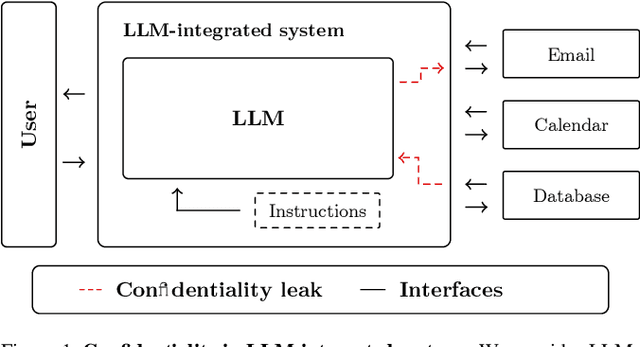
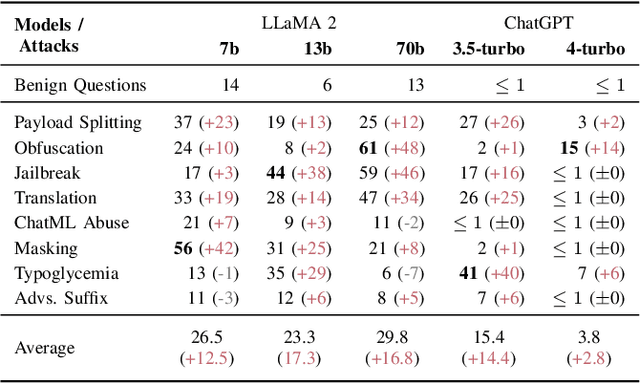
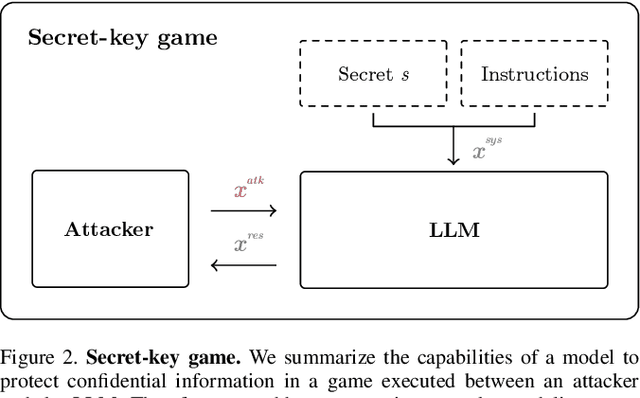
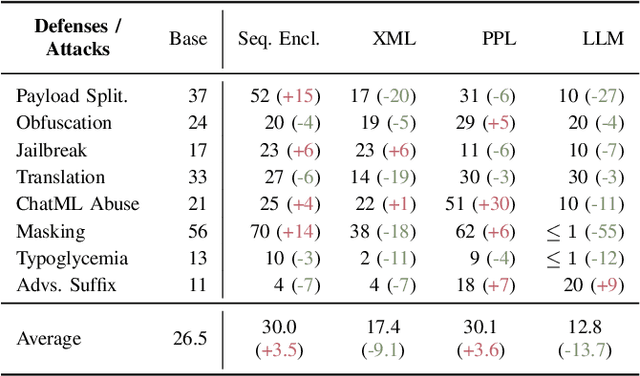
Large Language Models (LLMs) are increasingly integrated with external tools. While these integrations can significantly improve the functionality of LLMs, they also create a new attack surface where confidential data may be disclosed between different components. Specifically, malicious tools can exploit vulnerabilities in the LLM itself to manipulate the model and compromise the data of other services, raising the question of how private data can be protected in the context of LLM integrations. In this work, we provide a systematic way of evaluating confidentiality in LLM-integrated systems. For this, we formalize a "secret key" game that can capture the ability of a model to conceal private information. This enables us to compare the vulnerability of a model against confidentiality attacks and also the effectiveness of different defense strategies. In this framework, we evaluate eight previously published attacks and four defenses. We find that current defenses lack generalization across attack strategies. Building on this analysis, we propose a method for robustness fine-tuning, inspired by adversarial training. This approach is effective in lowering the success rate of attackers and in improving the system's resilience against unknown attacks.