 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVENOMAVE: Clean-Label Poisoning Against Speech Recognition
Paper and Code


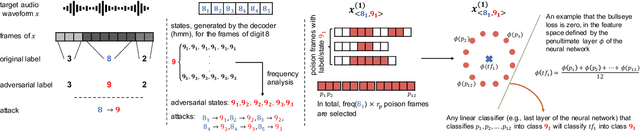
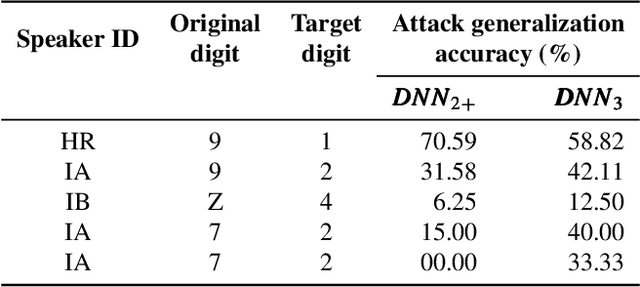
In the past few years, we observed a wide adoption of practical systems that use Automatic Speech Recognition (ASR) systems to improve human-machine interaction. Modern ASR systems are based on neural networks and prior research demonstrated that these systems are susceptible to adversarial examples, i.e., malicious audio inputs that lead to misclassification by the victim's network during the system's run time. The research question if ASR systems are also vulnerable to data poisoning attacks is still unanswered. In such an attack, a manipulation happens during the training phase of the neural network: an adversary injects malicious inputs into the training set such that the neural network's integrity and performance are compromised. In this paper, we present the first data poisoning attack in the audio domain, called VENOMAVE. Prior work in the image domain demonstrated several types of data poisoning attacks, but they cannot be applied to the audio domain. The main challenge is that we need to attack a time series of inputs. To enforce a targeted misclassification in an ASR system, we need to carefully generate a specific sequence of disturbed inputs for the target utterance, which will eventually be decoded to the desired sequence of words. More specifically, the adversarial goal is to produce a series of misclassification tasks and in each of them, we need to poison the system to misrecognize each frame of the target file. To demonstrate the practical feasibility of our attack, we evaluate VENOMAVE on an ASR system that detects sequences of digits from 0 to 9. When poisoning only 0.94% of the dataset on average, we achieve an attack success rate of 83.33%. We conclude that data poisoning attacks against ASR systems represent a real threat that needs to be considered.