 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymptomAI: Towards a Conversational AI Agent for Everyday Symptom Assessment
May 05, 2026Language models excel at diagnostic assessments on currated medical case-studies and vignettes, performing on par with, or better than, clinical professionals. However, existing studies focus on complex scenarios with rich context making it difficult to draw conclusions about how these systems perform for patients reporting symptoms in everyday life. We deployed SymptomAI, a set of conversational AI agents for end-to-end patient interviewing and differential diagnosis (DDx), via the Fitbit app in a study that randomized participants (N=13,917) to interact with five AI agents. This corpus captures diverse communication and a realistic distribution of illnesses from a real world population. A subset of 1,228 participants reported a clinician-provided diagnosis, and 517 of these were further evaluated by a panel of clinicians during over 250 hours of annotation. SymptomAI DDx were significantly more accurate (OR = 2.47, p < 0.001) than those from independent clinicians given the same dialogue in a blinded randomized comparison. Moreover, agentic strategies which conduct a dedicated symptom interview that elicit additional symptom information before providing a diagnosis, perform substantially better than baseline, user-guided conversations (p < 0.001). An auxiliary analysis on 1,509 conversations from a general US population panel validated that these results generalize beyond wearable device users. We used SymptomAI diagnoses as labels for all 13,917 participants to analyze over 500,000 days of wearable metrics across nearly 400 unique conditions. We identified strong associations between acute infections and physiological shifts (e.g., OR > 7 for influenza). While limited by self-reported ground truth, these results demonstrate the benefits of a dedicated and complete symptom interview compared to a user-guided symptom discussion, which is the default of most consumer LLMs.
A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic
Mar 10, 2026Large language model (LLM)-based AI systems have shown promise for patient-facing diagnostic and management conversations in simulated settings. Translating these systems into clinical practice requires assessment in real-world workflows with rigorous safety oversight. We report a prospective, single-arm feasibility study of an LLM-based conversational AI, the Articulate Medical Intelligence Explorer (AMIE), conducting clinical history taking and presentation of potential diagnoses for patients to discuss with their provider at urgent care appointments at a leading academic medical center. 100 adult patients completed an AMIE text-chat interaction up to 5 days before their appointment. We sought to assess the conversational safety and quality, patient and clinician experience, and clinical reasoning capabilities compared to primary care providers (PCPs). Human safety supervisors monitored all patient-AMIE interactions in real time and did not need to intervene to stop any consultations based on pre-defined criteria. Patients reported high satisfaction and their attitudes towards AI improved after interacting with AMIE (p < 0.001). PCPs found AMIE's output useful with a positive impact on preparedness. AMIE's differential diagnosis (DDx) included the final diagnosis, per chart review 8 weeks post-encounter, in 90% of cases, with 75% top-3 accuracy. Blinded assessment of AMIE and PCP DDx and management (Mx) plans suggested similar overall DDx and Mx plan quality, without significant differences for DDx (p = 0.6) and appropriateness and safety of Mx (p = 0.1 and 1.0, respectively). PCPs outperformed AMIE in the practicality (p = 0.003) and cost effectiveness (p = 0.004) of Mx. While further research is needed, this study demonstrates the initial feasibility, safety, and user acceptance of conversational AI in a real-world setting, representing crucial steps towards clinical translation.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering
May 29, 2025Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these "relevant" subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025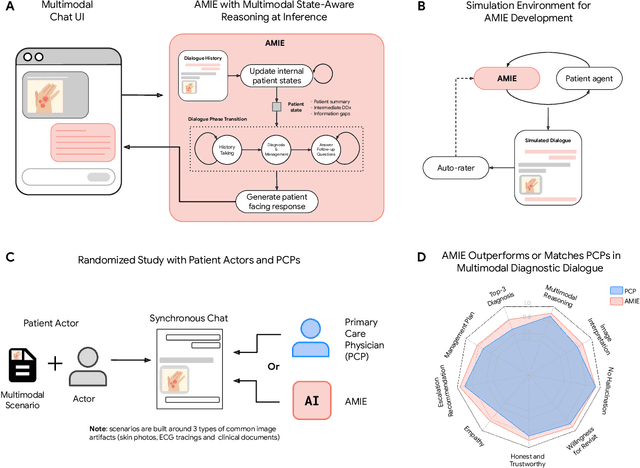
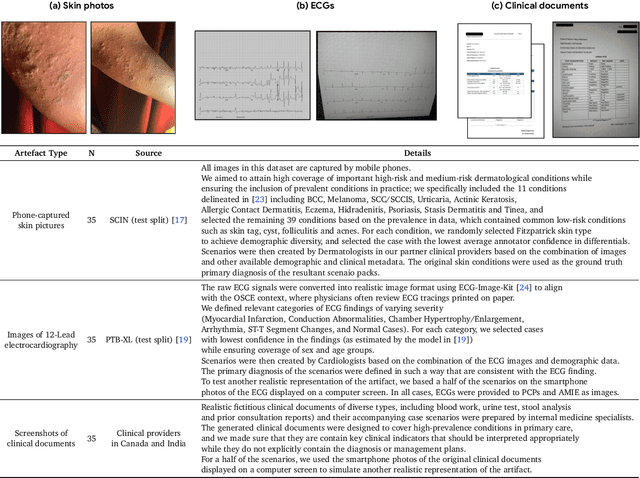
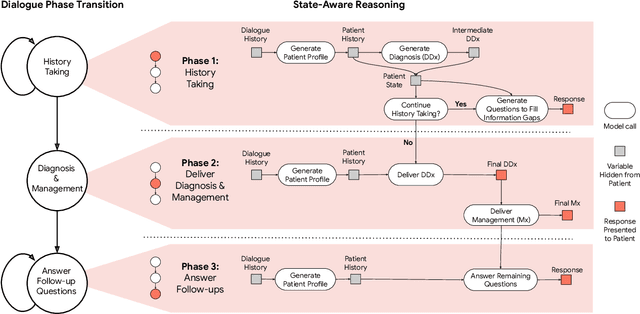
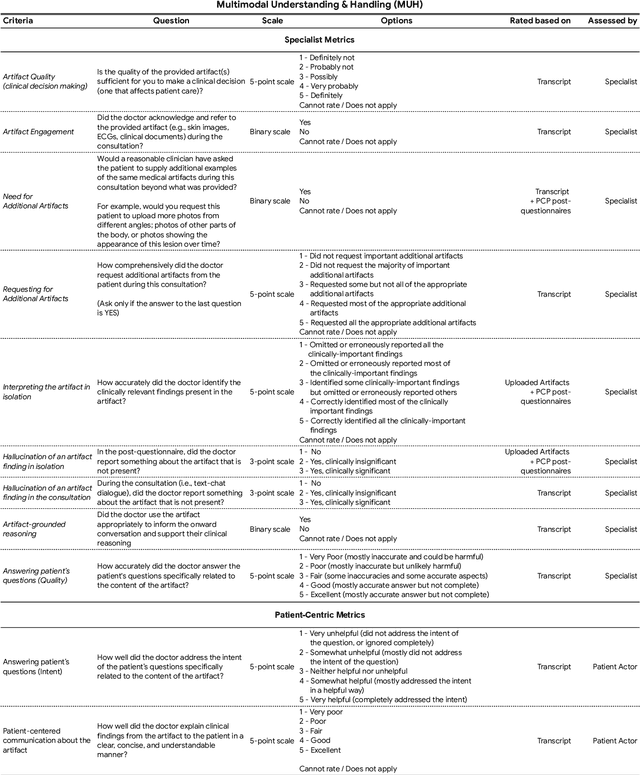
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Towards Conversational AI for Disease Management
Mar 08, 2025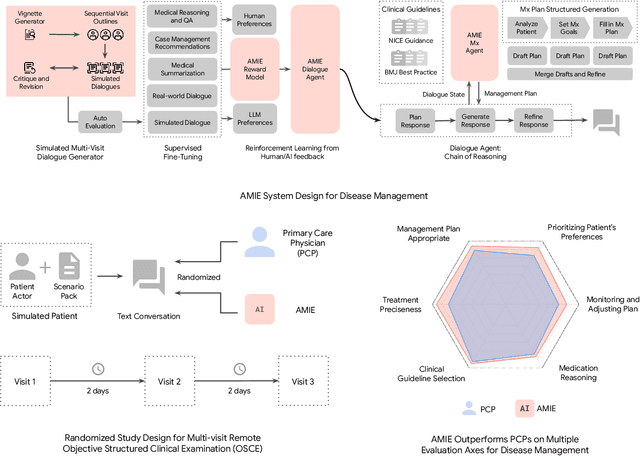

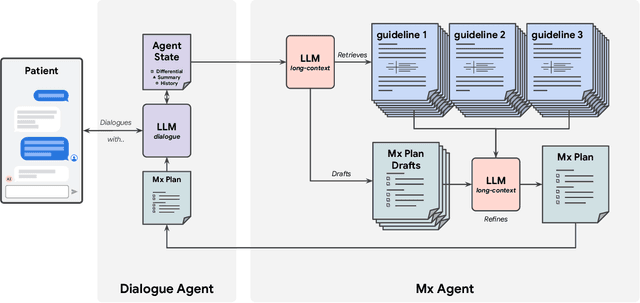
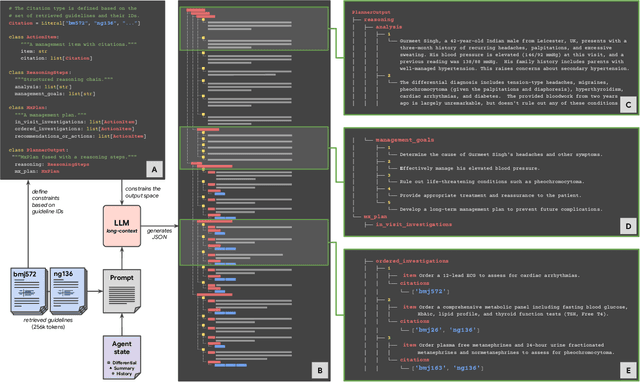
While large language models (LLMs) have shown promise in diagnostic dialogue, their capabilities for effective management reasoning - including disease progression, therapeutic response, and safe medication prescription - remain under-explored. We advance the previously demonstrated diagnostic capabilities of the Articulate Medical Intelligence Explorer (AMIE) through a new LLM-based agentic system optimised for clinical management and dialogue, incorporating reasoning over the evolution of disease and multiple patient visit encounters, response to therapy, and professional competence in medication prescription. To ground its reasoning in authoritative clinical knowledge, AMIE leverages Gemini's long-context capabilities, combining in-context retrieval with structured reasoning to align its output with relevant and up-to-date clinical practice guidelines and drug formularies. In a randomized, blinded virtual Objective Structured Clinical Examination (OSCE) study, AMIE was compared to 21 primary care physicians (PCPs) across 100 multi-visit case scenarios designed to reflect UK NICE Guidance and BMJ Best Practice guidelines. AMIE was non-inferior to PCPs in management reasoning as assessed by specialist physicians and scored better in both preciseness of treatments and investigations, and in its alignment with and grounding of management plans in clinical guidelines. To benchmark medication reasoning, we developed RxQA, a multiple-choice question benchmark derived from two national drug formularies (US, UK) and validated by board-certified pharmacists. While AMIE and PCPs both benefited from the ability to access external drug information, AMIE outperformed PCPs on higher difficulty questions. While further research would be needed before real-world translation, AMIE's strong performance across evaluations marks a significant step towards conversational AI as a tool in disease management.
LearnLM: Improving Gemini for Learning
Dec 21, 2024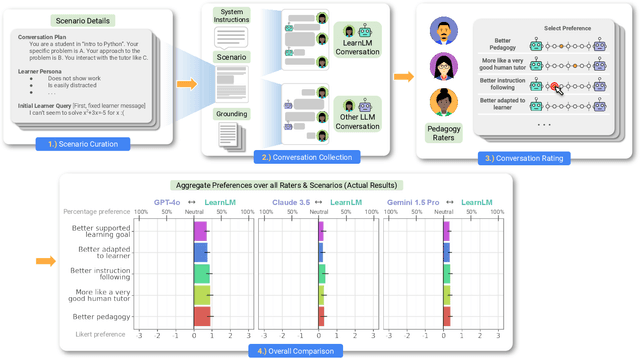
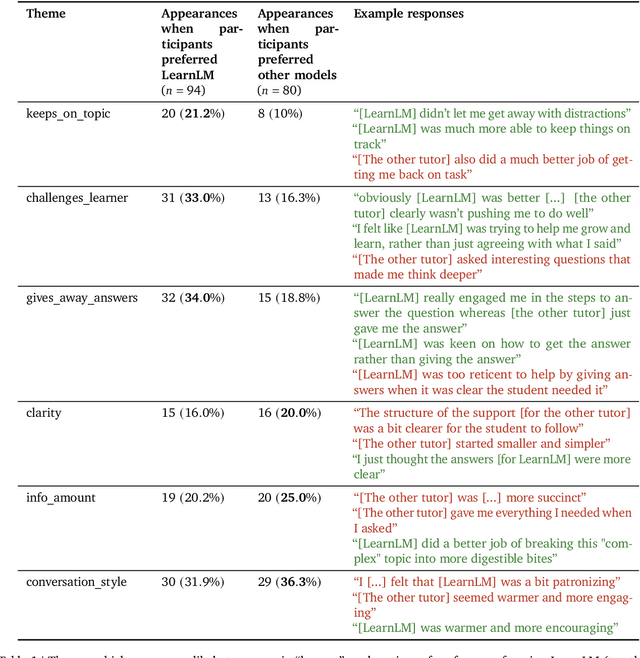
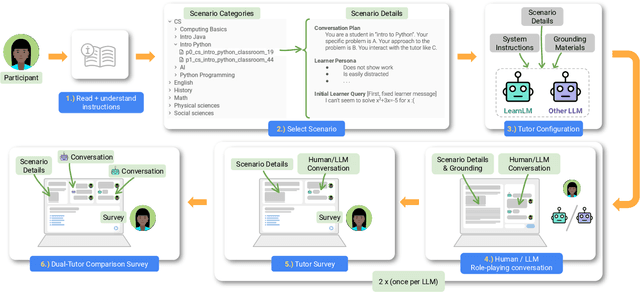
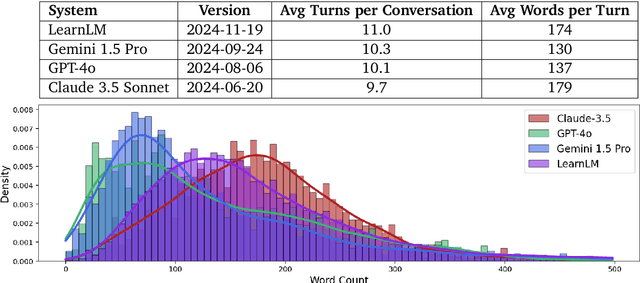
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
MINT: A wrapper to make multi-modal and multi-image AI models interactive
Jan 22, 2024During the diagnostic process, doctors incorporate multimodal information including imaging and the medical history - and similarly medical AI development has increasingly become multimodal. In this paper we tackle a more subtle challenge: doctors take a targeted medical history to obtain only the most pertinent pieces of information; how do we enable AI to do the same? We develop a wrapper method named MINT (Make your model INTeractive) that automatically determines what pieces of information are most valuable at each step, and ask for only the most useful information. We demonstrate the efficacy of MINT wrapping a skin disease prediction model, where multiple images and a set of optional answers to $25$ standard metadata questions (i.e., structured medical history) are used by a multi-modal deep network to provide a differential diagnosis. We show that MINT can identify whether metadata inputs are needed and if so, which question to ask next. We also demonstrate that when collecting multiple images, MINT can identify if an additional image would be beneficial, and if so, which type of image to capture. We showed that MINT reduces the number of metadata and image inputs needed by 82% and 36.2% respectively, while maintaining predictive performance. Using real-world AI dermatology system data, we show that needing fewer inputs can retain users that may otherwise fail to complete the system submission and drop off without a diagnosis. Qualitative examples show MINT can closely mimic the step-by-step decision making process of a clinical workflow and how this is different for straight forward cases versus more difficult, ambiguous cases. Finally we demonstrate how MINT is robust to different underlying multi-model classifiers and can be easily adapted to user requirements without significant model re-training.
Towards Conversational Diagnostic AI
Jan 11, 2024At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.