 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini in an arena for learning
May 30, 2025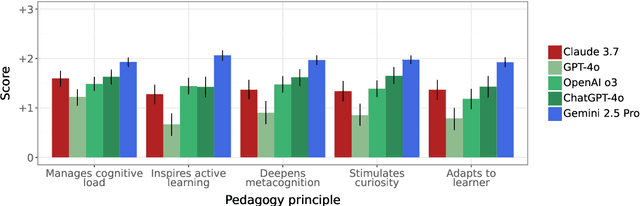

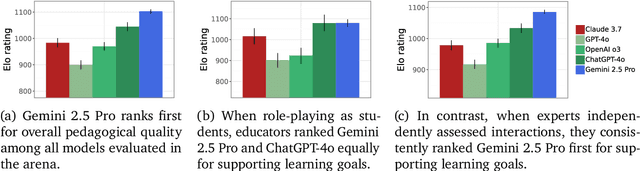
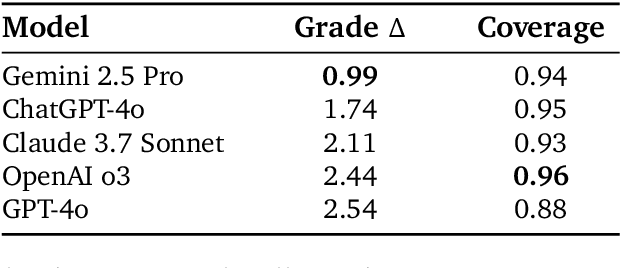
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024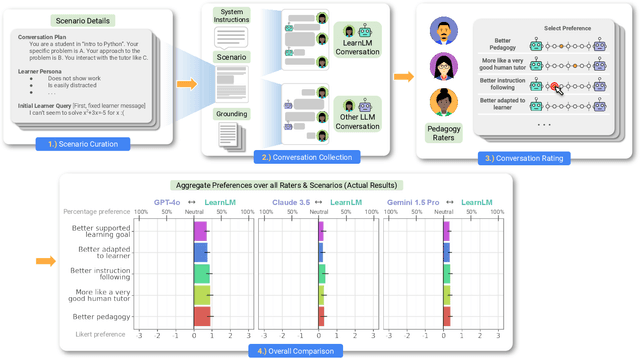
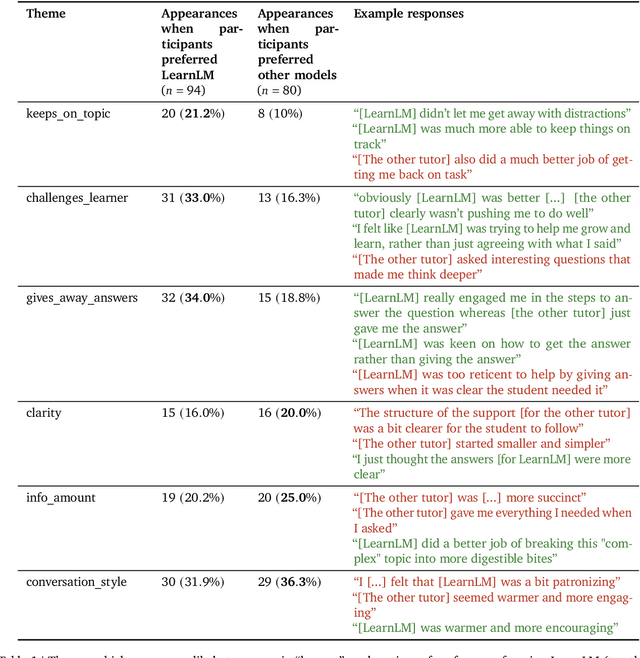
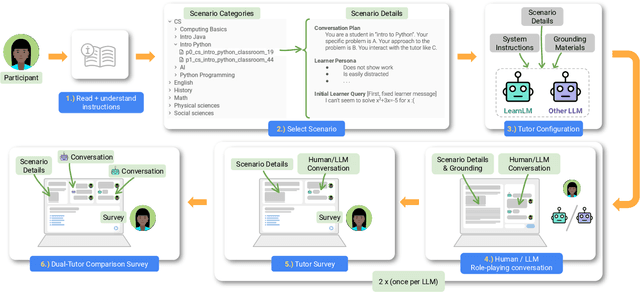
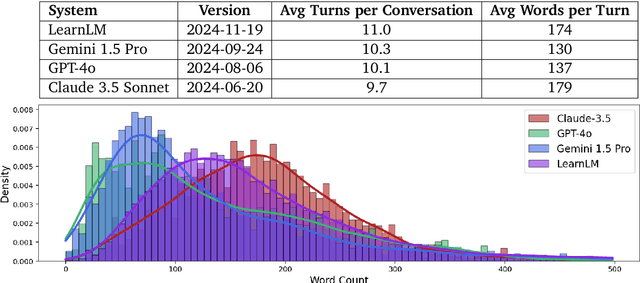
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Selectively Answering Ambiguous Questions
May 24, 2023Trustworthy language models should abstain from answering questions when they do not know the answer. However, the answer to a question can be unknown for a variety of reasons. Prior research has focused on the case in which the question is clear and the answer is unambiguous but possibly unknown. However, the answer to a question can also be unclear due to uncertainty of the questioner's intent or context. We investigate question answering from this perspective, focusing on answering a subset of questions with a high degree of accuracy, from a set of questions in which many are inherently ambiguous. In this setting, we find that the most reliable approach to calibration involves quantifying repetition within a set of sampled model outputs, rather than the model's likelihood or self-verification as used in prior work. % We find this to be the case across different types of uncertainty, varying model scales and both with or without instruction tuning. Our results suggest that sampling-based confidence scores help calibrate answers to relatively unambiguous questions, with more dramatic improvements on ambiguous questions.
NAIL: Lexical Retrieval Indices with Efficient Non-Autoregressive Decoders
May 23, 2023


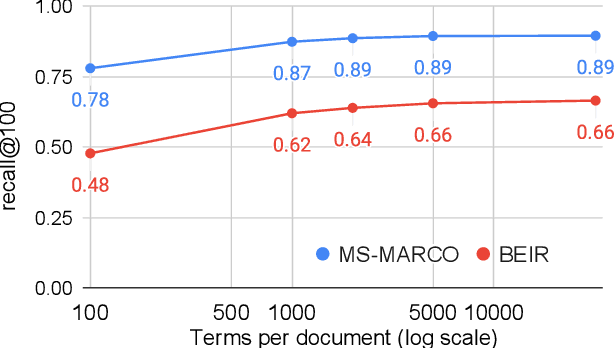
Neural document rerankers are extremely effective in terms of accuracy. However, the best models require dedicated hardware for serving, which is costly and often not feasible. To avoid this serving-time requirement, we present a method of capturing up to 86% of the gains of a Transformer cross-attention model with a lexicalized scoring function that only requires 10-6% of the Transformer's FLOPs per document and can be served using commodity CPUs. When combined with a BM25 retriever, this approach matches the quality of a state-of-the art dual encoder retriever, that still requires an accelerator for query encoding. We introduce NAIL (Non-Autoregressive Indexing with Language models) as a model architecture that is compatible with recent encoder-decoder and decoder-only large language models, such as T5, GPT-3 and PaLM. This model architecture can leverage existing pre-trained checkpoints and can be fine-tuned for efficiently constructing document representations that do not require neural processing of queries.
Time-Aware Language Models as Temporal Knowledge Bases
Jun 29, 2021
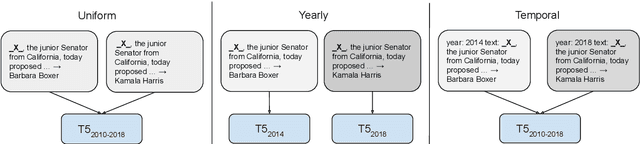
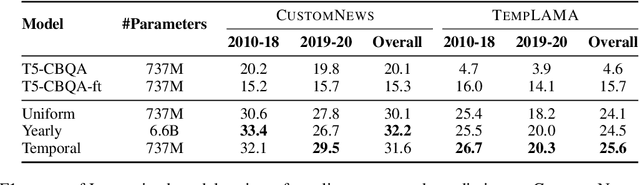
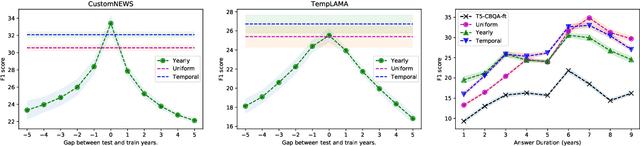
Many facts come with an expiration date, from the name of the President to the basketball team Lebron James plays for. But language models (LMs) are trained on snapshots of data collected at a specific moment in time, and this can limit their utility, especially in the closed-book setting where the pretraining corpus must contain the facts the model should memorize. We introduce a diagnostic dataset aimed at probing LMs for factual knowledge that changes over time and highlight problems with LMs at either end of the spectrum -- those trained on specific slices of temporal data, as well as those trained on a wide range of temporal data. To mitigate these problems, we propose a simple technique for jointly modeling text with its timestamp. This improves memorization of seen facts from the training time period, as well as calibration on predictions about unseen facts from future time periods. We also show that models trained with temporal context can be efficiently ``refreshed'' as new data arrives, without the need for retraining from scratch.
MOLEMAN: Mention-Only Linking of Entities with a Mention Annotation Network
Jun 02, 2021
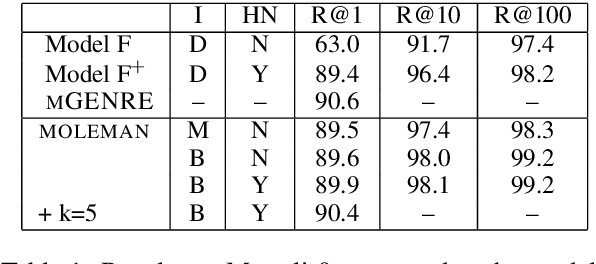
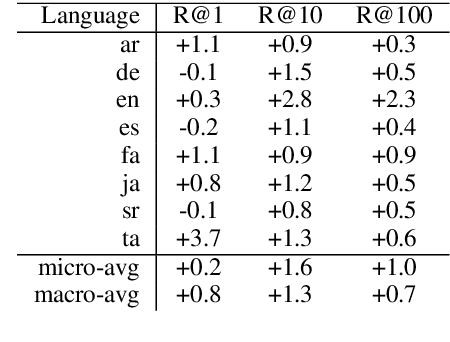
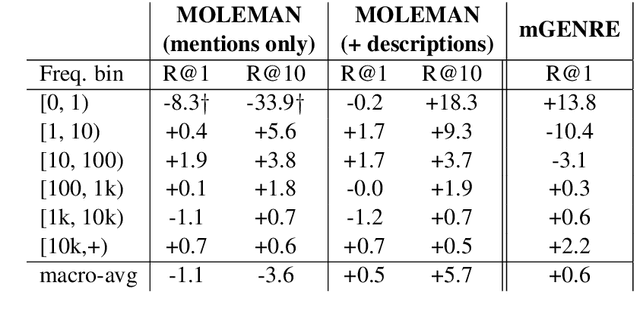
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as "class prototypes" as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor's entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
Entity Linking in 100 Languages
Nov 05, 2020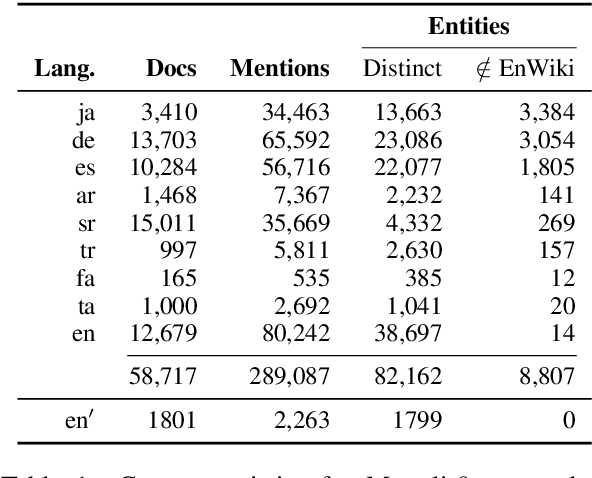
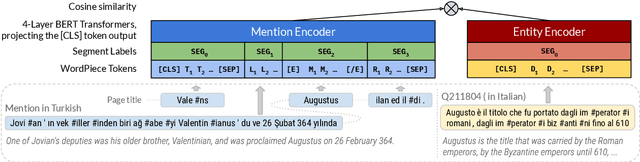
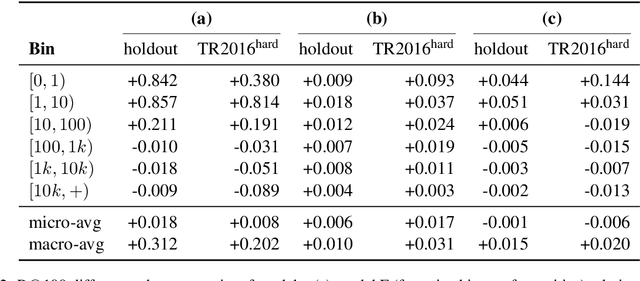
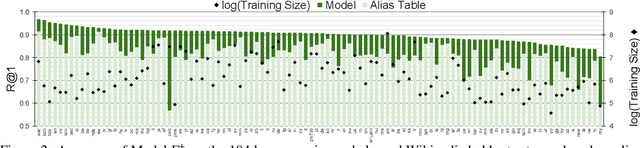
We propose a new formulation for multilingual entity linking, where language-specific mentions resolve to a language-agnostic Knowledge Base. We train a dual encoder in this new setting, building on prior work with improved feature representation, negative mining, and an auxiliary entity-pairing task, to obtain a single entity retrieval model that covers 100+ languages and 20 million entities. The model outperforms state-of-the-art results from a far more limited cross-lingual linking task. Rare entities and low-resource languages pose challenges at this large-scale, so we advocate for an increased focus on zero- and few-shot evaluation. To this end, we provide Mewsli-9, a large new multilingual dataset (http://goo.gle/mewsli-dataset) matched to our setting, and show how frequency-based analysis provided key insights for our model and training enhancements.
Learning Dense Representations for Entity Retrieval
Sep 23, 2019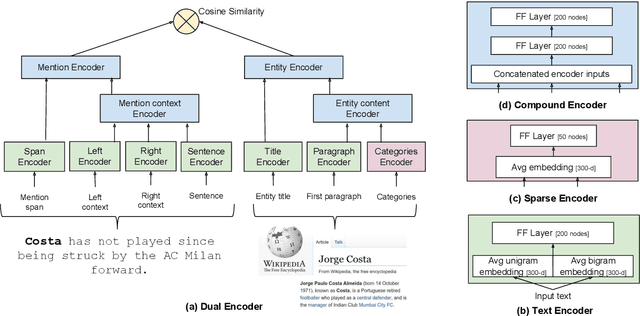
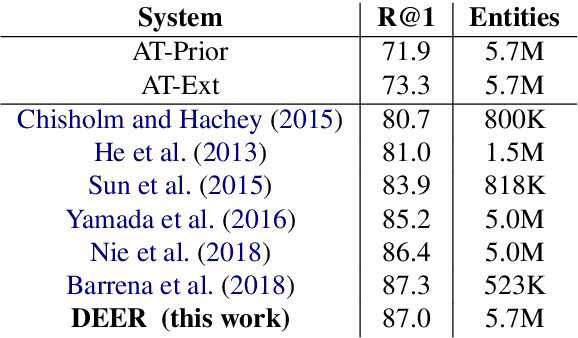
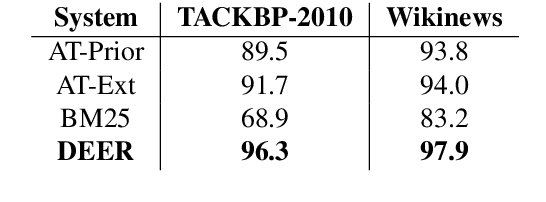
We show that it is feasible to perform entity linking by training a dual encoder (two-tower) model that encodes mentions and entities in the same dense vector space, where candidate entities are retrieved by approximate nearest neighbor search. Unlike prior work, this setup does not rely on an alias table followed by a re-ranker, and is thus the first fully learned entity retrieval model. We show that our dual encoder, trained using only anchor-text links in Wikipedia, outperforms discrete alias table and BM25 baselines, and is competitive with the best comparable results on the standard TACKBP-2010 dataset. In addition, it can retrieve candidates extremely fast, and generalizes well to a new dataset derived from Wikinews. On the modeling side, we demonstrate the dramatic value of an unsupervised negative mining algorithm for this task.
End-to-End Retrieval in Continuous Space
Nov 19, 2018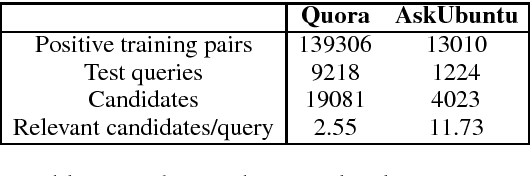
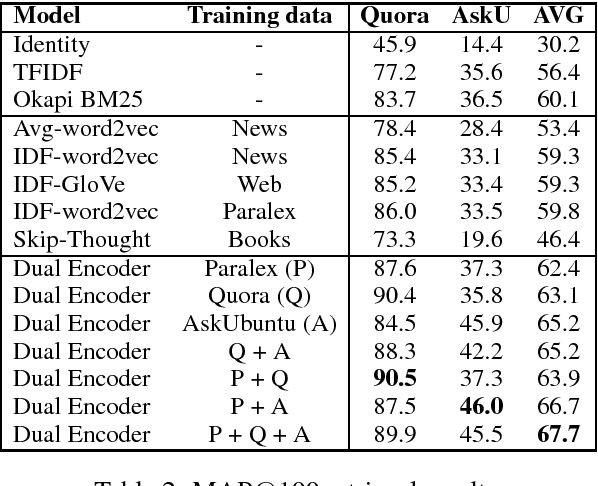
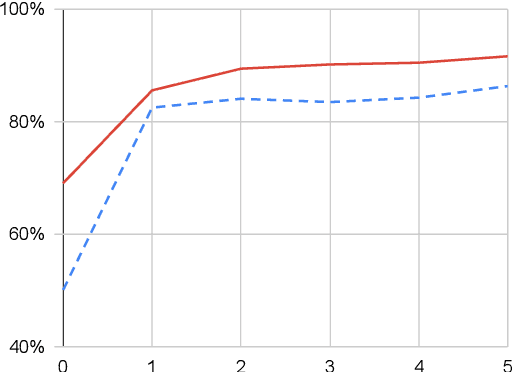
Most text-based information retrieval (IR) systems index objects by words or phrases. These discrete systems have been augmented by models that use embeddings to measure similarity in continuous space. But continuous-space models are typically used just to re-rank the top candidates. We consider the problem of end-to-end continuous retrieval, where standard approximate nearest neighbor (ANN) search replaces the usual discrete inverted index, and rely entirely on distances between learned embeddings. By training simple models specifically for retrieval, with an appropriate model architecture, we improve on a discrete baseline by 8% and 26% (MAP) on two similar-question retrieval tasks. We also discuss the problem of evaluation for retrieval systems, and show how to modify existing pairwise similarity datasets for this purpose.
A Fast, Compact, Accurate Model for Language Identification of Codemixed Text
Oct 09, 2018
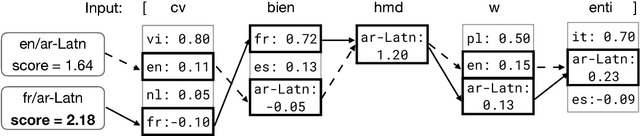
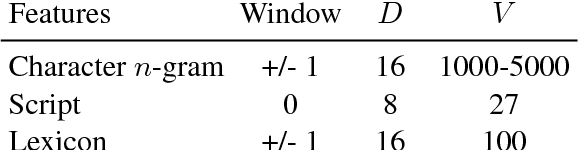
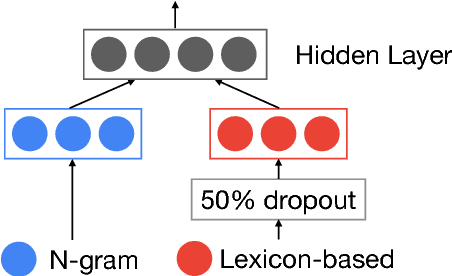
We address fine-grained multilingual language identification: providing a language code for every token in a sentence, including codemixed text containing multiple languages. Such text is prevalent online, in documents, social media, and message boards. We show that a feed-forward network with a simple globally constrained decoder can accurately and rapidly label both codemixed and monolingual text in 100 languages and 100 language pairs. This model outperforms previously published multilingual approaches in terms of both accuracy and speed, yielding an 800x speed-up and a 19.5% averaged absolute gain on three codemixed datasets. It furthermore outperforms several benchmark systems on monolingual language identification.