 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing and Correcting Errors for LLM-based Planners
Jan 30, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities on math and coding, but frequently fail on symbolic classical planning tasks. Our studies, as well as prior work, show that LLM-generated plans routinely violate domain constraints given in their instructions (e.g., walking through walls). To address this failure, we propose iteratively augmenting instructions with Localized In-Context Learning (L-ICL) demonstrations: targeted corrections for specific failing steps. Specifically, L-ICL identifies the first constraint violation in a trace and injects a minimal input-output example giving the correct behavior for the failing step. Our proposed technique of L-ICL is much effective than explicit instructions or traditional ICL, which adds complete problem-solving trajectories, and many other baselines. For example, on an 8x8 gridworld, L-ICL produces valid plans 89% of the time with only 60 training examples, compared to 59% for the best baseline, an increase of 30%. L-ICL also shows dramatic improvements in other domains (gridworld navigation, mazes, Sokoban, and BlocksWorld), and on several LLM architectures.
Semi-structured LLM Reasoners Can Be Rigorously Audited
May 30, 2025As Large Language Models (LLMs) become increasingly capable at reasoning, the problem of "faithfulness" persists: LLM "reasoning traces" can contain errors and omissions that are difficult to detect, and may obscure biases in model outputs. To address these limitations, we introduce Semi-Structured Reasoning Models (SSRMs), which internalize a semi-structured Chain-of-Thought (CoT) reasoning format within the model. Our SSRMs generate reasoning traces in a Pythonic syntax. While SSRM traces are not executable, they adopt a restricted, task-specific vocabulary to name distinct reasoning steps, and to mark each step's inputs and outputs. Through extensive evaluation on ten benchmarks, SSRMs demonstrate strong performance and generality: they outperform comparably sized baselines by nearly ten percentage points on in-domain tasks while remaining competitive with specialized models on out-of-domain medical benchmarks. Furthermore, we show that semi-structured reasoning is more amenable to analysis: in particular, they can be automatically audited to identify reasoning flaws. We explore both hand-crafted structured audits, which detect task-specific problematic reasoning patterns, and learned typicality audits, which apply probabilistic models over reasoning patterns, and show that both audits can be used to effectively flag probable reasoning errors.
CrossWordBench: Evaluating the Reasoning Capabilities of LLMs and LVLMs with Controllable Puzzle Generation
Mar 30, 2025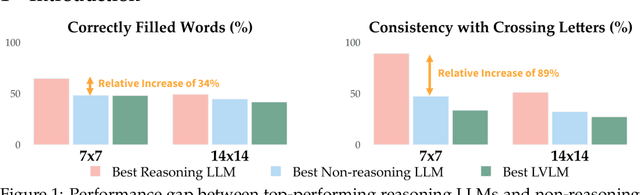
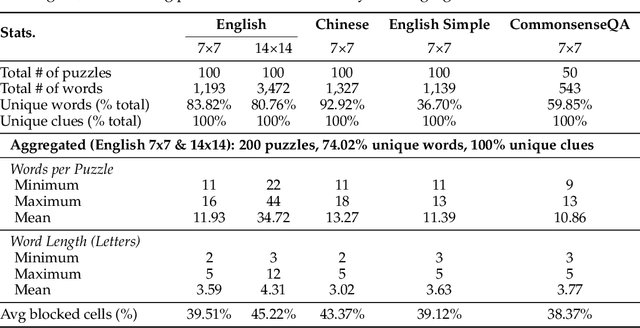
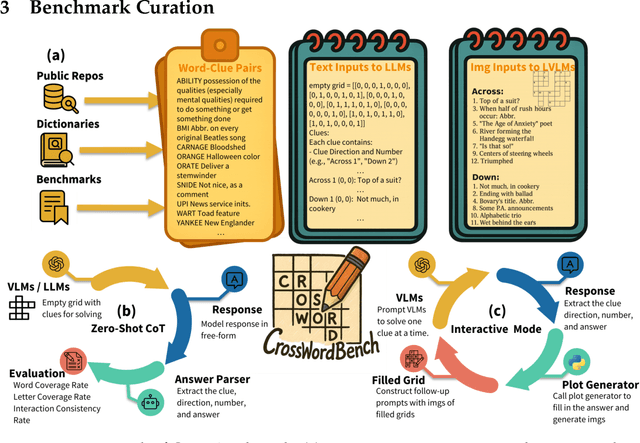
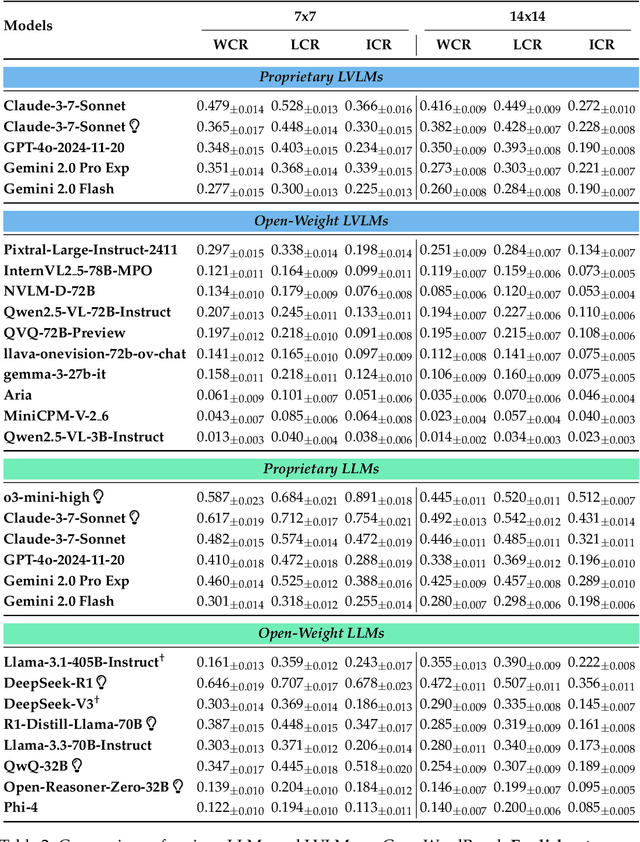
Existing reasoning evaluation frameworks for Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) predominantly either assess text-based reasoning or vision-language understanding capabilities, with limited dynamic interplay between textual and visual constraints. To address this limitation, we introduce CrossWordBench, a benchmark designed to evaluate the reasoning capabilities of both LLMs and LVLMs through the medium of crossword puzzles-a task requiring multimodal adherence to semantic constraints from text-based clues and intersectional constraints from visual grid structures. CrossWordBench leverages a controllable puzzle generation framework that produces puzzles in multiple formats (text and image) and offers different evaluation strategies ranging from direct puzzle solving to interactive modes. Our extensive evaluation of over 20 models reveals that reasoning LLMs outperform non-reasoning models substantially by effectively leveraging crossing-letter constraints. We further demonstrate that LVLMs struggle with the task, showing a strong correlation between their puzzle-solving performance and grid-parsing accuracy. Our findings offer insights into the limitations of the reasoning capabilities of current LLMs and LVLMs, and provide an effective approach for creating multimodal constrained tasks for future evaluations.
ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Jun 20, 2024Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation
Jun 06, 2024

Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. PPI achieves this by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate -- but potentially biased -- automatic system, in a way that results in tighter confidence intervals for certain parameters of interest (e.g., the mean performance of a language model). In this paper, we propose a method called Stratified Prediction-Powered Inference (StratPPI), in which we show that the basic PPI estimates can be considerably improved by employing simple data stratification strategies. Without making any assumptions on the underlying automatic labeling system or data distribution, we derive an algorithm for computing provably valid confidence intervals for population parameters (such as averages) that is based on stratified sampling. In particular, we show both theoretically and empirically that, with appropriate choices of stratification and sample allocation, our approach can provide substantially tighter confidence intervals than unstratified approaches. Specifically, StratPPI is expected to improve in cases where the performance of the autorater varies across different conditional distributions of the target data.
Bayesian Prediction-Powered Inference
May 09, 2024Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. Specifically, PPI methods provide tighter confidence intervals by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate, but potentially biased, automatic system. We propose a framework for PPI based on Bayesian inference that allows researchers to develop new task-appropriate PPI methods easily. Exploiting the ease with which we can design new metrics, we propose improved PPI methods for several importantcases, such as autoraters that give discrete responses (e.g., prompted LLM ``judges'') and autoraters with scores that have a non-linear relationship to human scores.
Characterizing Tradeoffs in Language Model Decoding with Informational Interpretations
Nov 16, 2023We propose a theoretical framework for formulating language model decoder algorithms with dynamic programming and information theory. With dynamic programming, we lift the design of decoder algorithms from the logit space to the action-state value function space, and show that the decoding algorithms are consequences of optimizing the action-state value functions. Each component in the action-state value function space has an information theoretical interpretation. With the lifting and interpretation, it becomes evident what the decoder algorithm is optimized for, and hence facilitating the arbitration of the tradeoffs in sensibleness, diversity, and attribution.
Trusted Source Alignment in Large Language Models
Nov 12, 2023



Large language models (LLMs) are trained on web-scale corpora that inevitably include contradictory factual information from sources of varying reliability. In this paper, we propose measuring an LLM property called trusted source alignment (TSA): the model's propensity to align with content produced by trusted publishers in the face of uncertainty or controversy. We present FactCheckQA, a TSA evaluation dataset based on a corpus of fact checking articles. We describe a simple protocol for evaluating TSA and offer a detailed analysis of design considerations including response extraction, claim contextualization, and bias in prompt formulation. Applying the protocol to PaLM-2, we find that as we scale up the model size, the model performance on FactCheckQA improves from near-random to up to 80% balanced accuracy in aligning with trusted sources.
SEMQA: Semi-Extractive Multi-Source Question Answering
Nov 08, 2023Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
MEMORY-VQ: Compression for Tractable Internet-Scale Memory
Aug 28, 2023



Retrieval augmentation is a powerful but expensive method to make language models more knowledgeable about the world. Memory-based methods like LUMEN pre-compute token representations for retrieved passages to drastically speed up inference. However, memory also leads to much greater storage requirements from storing pre-computed representations. We propose MEMORY-VQ, a new method to reduce storage requirements of memory-augmented models without sacrificing performance. Our method uses a vector quantization variational autoencoder (VQ-VAE) to compress token representations. We apply MEMORY-VQ to the LUMEN model to obtain LUMEN-VQ, a memory model that achieves a 16x compression rate with comparable performance on the KILT benchmark. LUMEN-VQ enables practical retrieval augmentation even for extremely large retrieval corpora.